 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Single Timestamps: Complexity Estimation in Laparoscopic Cholecystectomy
Nov 06, 2025Purpose: Accurate assessment of surgical complexity is essential in Laparoscopic Cholecystectomy (LC), where severe inflammation is associated with longer operative times and increased risk of postoperative complications. The Parkland Grading Scale (PGS) provides a clinically validated framework for stratifying inflammation severity; however, its automation in surgical videos remains largely unexplored, particularly in realistic scenarios where complete videos must be analyzed without prior manual curation. Methods: In this work, we introduce STC-Net, a novel framework for SingleTimestamp-based Complexity estimation in LC via the PGS, designed to operate under weak temporal supervision. Unlike prior methods limited to static images or manually trimmed clips, STC-Net operates directly on full videos. It jointly performs temporal localization and grading through a localization, window proposal, and grading module. We introduce a novel loss formulation combining hard and soft localization objectives and background-aware grading supervision. Results: Evaluated on a private dataset of 1,859 LC videos, STC-Net achieves an accuracy of 62.11% and an F1-score of 61.42%, outperforming non-localized baselines by over 10% in both metrics and highlighting the effectiveness of weak supervision for surgical complexity assessment. Conclusion: STC-Net demonstrates a scalable and effective approach for automated PGS-based surgical complexity estimation from full LC videos, making it promising for post-operative analysis and surgical training.
Self-Knowledge Distillation for Surgical Phase Recognition
Jun 15, 2023
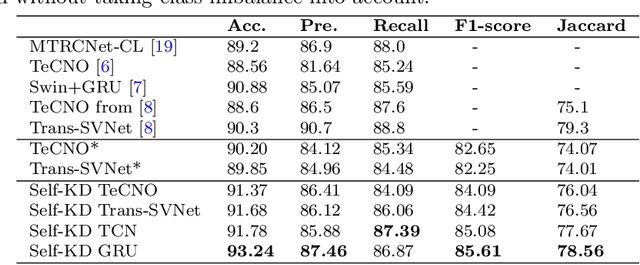


Purpose: Advances in surgical phase recognition are generally led by training deeper networks. Rather than going further with a more complex solution, we believe that current models can be exploited better. We propose a self-knowledge distillation framework that can be integrated into current state-of-the-art (SOTA) models without requiring any extra complexity to the models or annotations. Methods: Knowledge distillation is a framework for network regularization where knowledge is distilled from a teacher network to a student network. In self-knowledge distillation, the student model becomes the teacher such that the network learns from itself. Most phase recognition models follow an encoder-decoder framework. Our framework utilizes self-knowledge distillation in both stages. The teacher model guides the training process of the student model to extract enhanced feature representations from the encoder and build a more robust temporal decoder to tackle the over-segmentation problem. Results: We validate our proposed framework on the public dataset Cholec80. Our framework is embedded on top of four popular SOTA approaches and consistently improves their performance. Specifically, our best GRU model boosts performance by +3.33% accuracy and +3.95% F1-score over the same baseline model. Conclusion: We embed a self-knowledge distillation framework for the first time in the surgical phase recognition training pipeline. Experimental results demonstrate that our simple yet powerful framework can improve performance of existing phase recognition models. Moreover, our extensive experiments show that even with 75% of the training set we still achieve performance on par with the same baseline model trained on the full set.
CaDIS: Cataract Dataset for Image Segmentation
Jul 19, 2019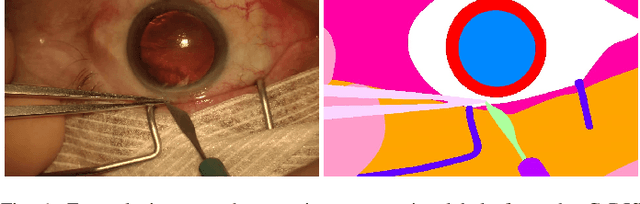
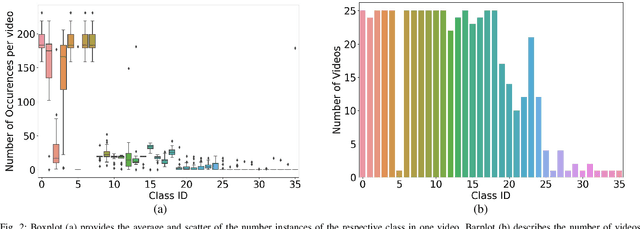
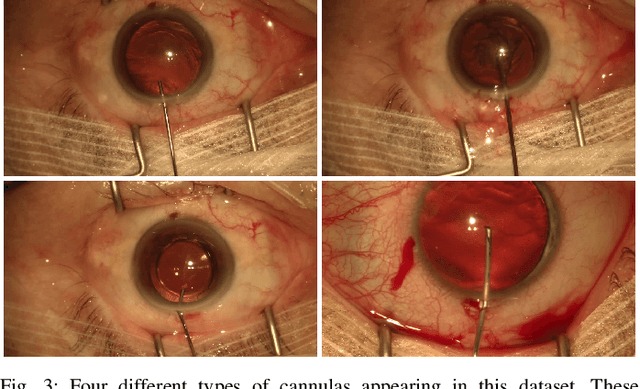

Video signals provide a wealth of information about surgical procedures and are the main sensory cue for surgeons. Video processing and understanding can be used to empower computer assisted interventions (CAI) as well as the development of detailed post-operative analysis of the surgical intervention. A fundamental building block to such capabilities is the ability to understand and segment video into semantic labels that differentiate and localize tissue types and different instruments. Deep learning has advanced semantic segmentation techniques dramatically in recent years but is fundamentally reliant on the availability of labelled datasets used to train models. In this paper, we introduce a high quality dataset for semantic segmentation in Cataract surgery. We generated this dataset from the CATARACTS challenge dataset, which is publicly available. To the best of our knowledge, this dataset has the highest quality annotation in surgical data to date. We introduce the dataset and then show the automatic segmentation performance of state-of-the-art models on that dataset as a benchmark.