 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2018 Robotic Scene Segmentation Challenge
Feb 03, 2020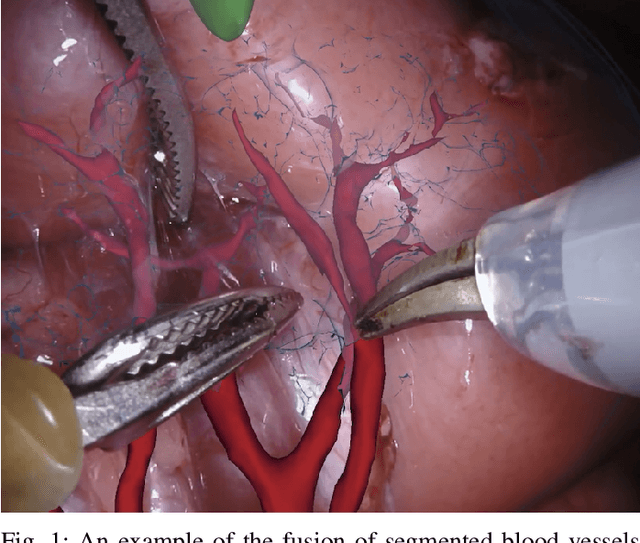
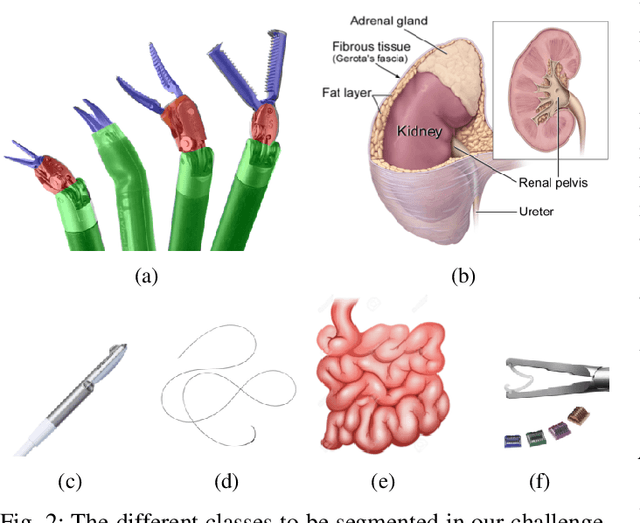
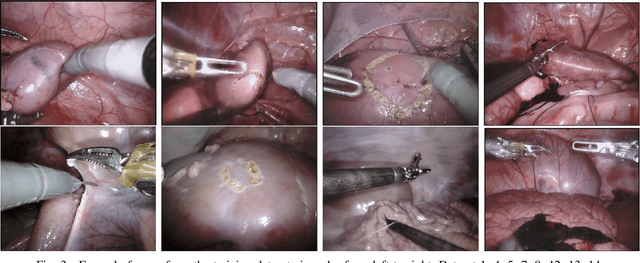
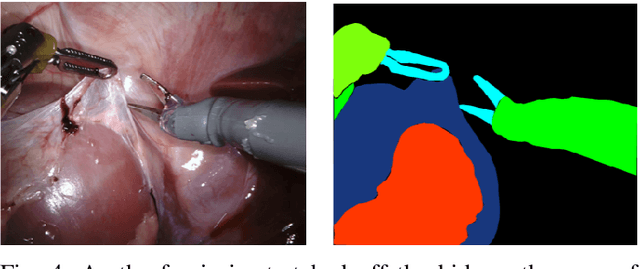
In 2015 we began a sub-challenge at the EndoVis workshop at MICCAI in Munich using endoscope images of ex-vivo tissue with automatically generated annotations from robot forward kinematics and instrument CAD models. However, the limited background variation and simple motion rendered the dataset uninformative in learning about which techniques would be suitable for segmentation in real surgery. In 2017, at the same workshop in Quebec we introduced the robotic instrument segmentation dataset with 10 teams participating in the challenge to perform binary, articulating parts and type segmentation of da Vinci instruments. This challenge included realistic instrument motion and more complex porcine tissue as background and was widely addressed with modifications on U-Nets and other popular CNN architectures. In 2018 we added to the complexity by introducing a set of anatomical objects and medical devices to the segmented classes. To avoid over-complicating the challenge, we continued with porcine data which is dramatically simpler than human tissue due to the lack of fatty tissue occluding many organs.
CaDIS: Cataract Dataset for Image Segmentation
Jul 19, 2019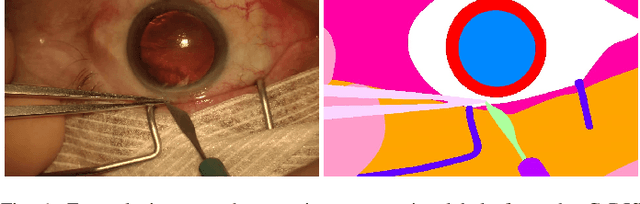
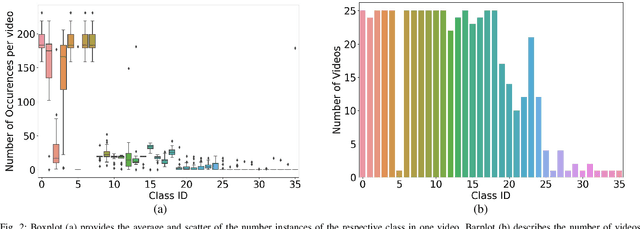
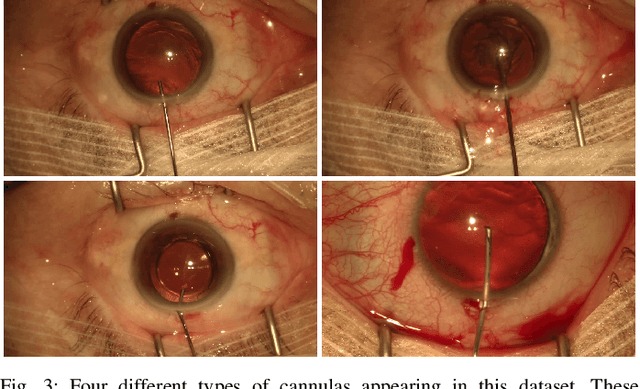

Video signals provide a wealth of information about surgical procedures and are the main sensory cue for surgeons. Video processing and understanding can be used to empower computer assisted interventions (CAI) as well as the development of detailed post-operative analysis of the surgical intervention. A fundamental building block to such capabilities is the ability to understand and segment video into semantic labels that differentiate and localize tissue types and different instruments. Deep learning has advanced semantic segmentation techniques dramatically in recent years but is fundamentally reliant on the availability of labelled datasets used to train models. In this paper, we introduce a high quality dataset for semantic segmentation in Cataract surgery. We generated this dataset from the CATARACTS challenge dataset, which is publicly available. To the best of our knowledge, this dataset has the highest quality annotation in surgical data to date. We introduce the dataset and then show the automatic segmentation performance of state-of-the-art models on that dataset as a benchmark.
SurReal: enhancing Surgical simulation Realism using style transfer
Nov 07, 2018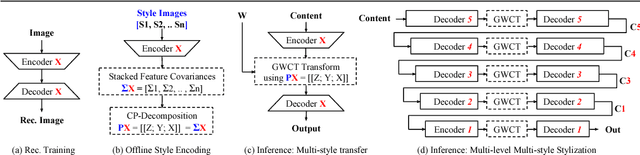

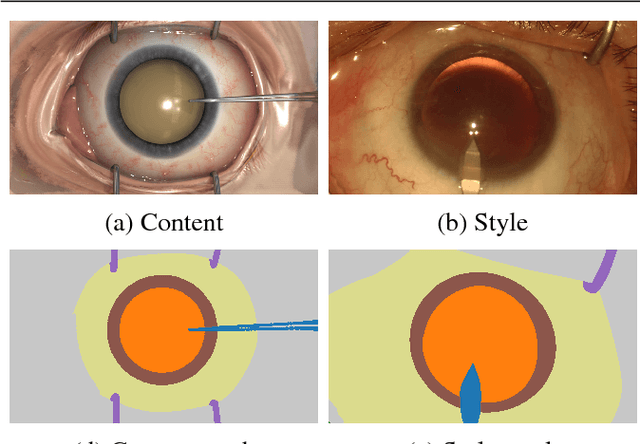

Surgical simulation is an increasingly important element of surgical education. Using simulation can be a means to address some of the significant challenges in developing surgical skills with limited time and resources. The photo-realistic fidelity of simulations is a key feature that can improve the experience and transfer ratio of trainees. In this paper, we demonstrate how we can enhance the visual fidelity of existing surgical simulation by performing style transfer of multi-class labels from real surgical video onto synthetic content. We demonstrate our approach on simulations of cataract surgery using real data labels from an existing public dataset. Our results highlight the feasibility of the approach and also the powerful possibility to extend this technique to incorporate additional temporal constraints and to different applications.
FaceOff: Anonymizing Videos in the Operating Rooms
Aug 06, 2018
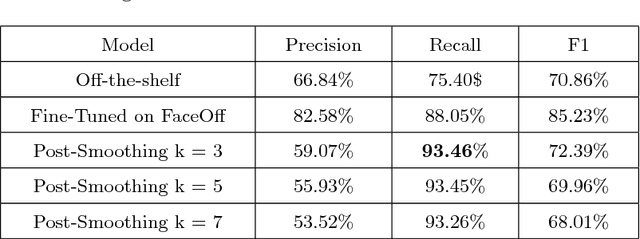
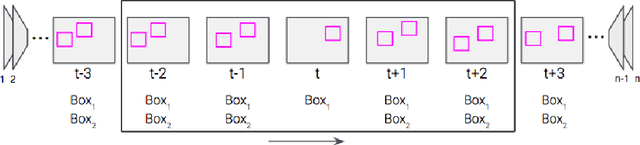

Video capture in the surgical operating room (OR) is increasingly possible and has potential for use with computer assisted interventions (CAI), surgical data science and within smart OR integration. Captured video innately carries sensitive information that should not be completely visible in order to preserve the patient's and the clinical teams' identities. When surgical video streams are stored on a server, the videos must be anonymized prior to storage if taken outside of the hospital. In this article, we describe how a deep learning model, Faster R-CNN, can be used for this purpose and help to anonymize video data captured in the OR. The model detects and blurs faces in an effort to preserve anonymity. After testing an existing face detection trained model, a new dataset tailored to the surgical environment, with faces obstructed by surgical masks and caps, was collected for fine-tuning to achieve higher face-detection rates in the OR. We also propose a temporal regularisation kernel to improve recall rates. The fine-tuned model achieves a face detection recall of 88.05 % and 93.45 % before and after applying temporal-smoothing respectively.
DeepPhase: Surgical Phase Recognition in CATARACTS Videos
Jul 17, 2018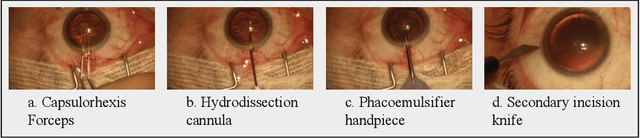
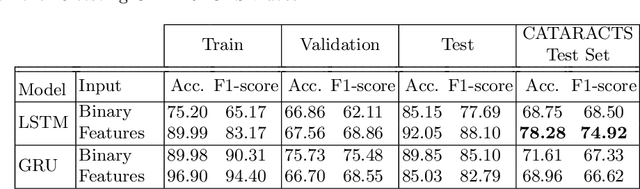
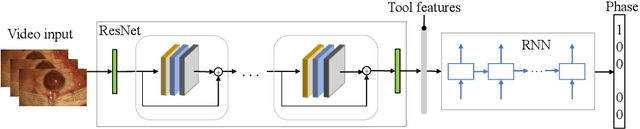
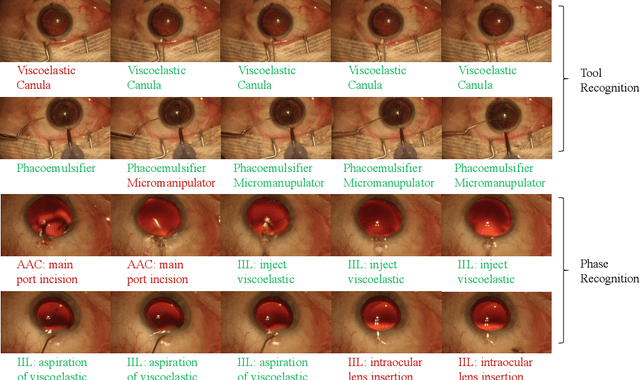
Automated surgical workflow analysis and understanding can assist surgeons to standardize procedures and enhance post-surgical assessment and indexing, as well as, interventional monitoring. Computer-assisted interventional (CAI) systems based on video can perform workflow estimation through surgical instruments' recognition while linking them to an ontology of procedural phases. In this work, we adopt a deep learning paradigm to detect surgical instruments in cataract surgery videos which in turn feed a surgical phase inference recurrent network that encodes temporal aspects of phase steps within the phase classification. Our models present comparable to state-of-the-art results for surgical tool detection and phase recognition with accuracies of 99 and 78% respectively.