 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Symplectic Optimization for Stable Reinforcement Learning
Dec 03, 2024



Training deep reinforcement learning (RL) agents necessitates overcoming the highly unstable nonconvex stochastic optimization inherent in the trial-and-error mechanism. To tackle this challenge, we propose a physics-inspired optimization algorithm called relativistic adaptive gradient descent (RAD), which enhances long-term training stability. By conceptualizing neural network (NN) training as the evolution of a conformal Hamiltonian system, we present a universal framework for transferring long-term stability from conformal symplectic integrators to iterative NN updating rules, where the choice of kinetic energy governs the dynamical properties of resulting optimization algorithms. By utilizing relativistic kinetic energy, RAD incorporates principles from special relativity and limits parameter updates below a finite speed, effectively mitigating abnormal gradient influences. Additionally, RAD models NN optimization as the evolution of a multi-particle system where each trainable parameter acts as an independent particle with an individual adaptive learning rate. We prove RAD's sublinear convergence under general nonconvex settings, where smaller gradient variance and larger batch sizes contribute to tighter convergence. Notably, RAD degrades to the well-known adaptive moment estimation (ADAM) algorithm when its speed coefficient is chosen as one and symplectic factor as a small positive value. Experimental results show RAD outperforming nine baseline optimizers with five RL algorithms across twelve environments, including standard benchmarks and challenging scenarios. Notably, RAD achieves up to a 155.1% performance improvement over ADAM in Atari games, showcasing its efficacy in stabilizing and accelerating RL training.
Feasible Actor-Critic: Constrained Reinforcement Learning for Ensuring Statewise Safety
May 28, 2021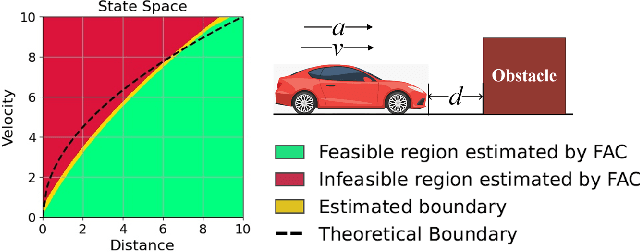


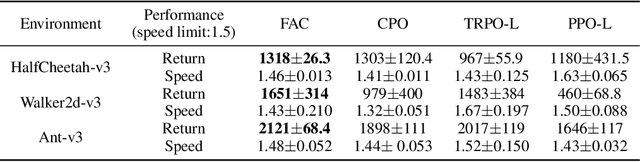
The safety constraints commonly used by existing safe reinforcement learning (RL) methods are defined only on expectation of initial states, but allow each certain state to be unsafe, which is unsatisfying for real-world safety-critical tasks. In this paper, we introduce the feasible actor-critic (FAC) algorithm, which is the first model-free constrained RL method that considers statewise safety, e.g, safety for each initial state. We claim that some states are inherently unsafe no matter what policy we choose, while for other states there exist policies ensuring safety, where we say such states and policies are feasible. By constructing a statewise Lagrange function available on RL sampling and adopting an additional neural network to approximate the statewise Lagrange multiplier, we manage to obtain the optimal feasible policy which ensures safety for each feasible state and the safest possible policy for infeasible states. Furthermore, the trained multiplier net can indicate whether a given state is feasible or not through the statewise complementary slackness condition. We provide theoretical guarantees that FAC outperforms previous expectation-based constrained RL methods in terms of both constraint satisfaction and reward optimization. Experimental results on both robot locomotive tasks and safe exploration tasks verify the safety enhancement and feasibility interpretation of the proposed method.