 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeasible Actor-Critic: Constrained Reinforcement Learning for Ensuring Statewise Safety
May 28, 2021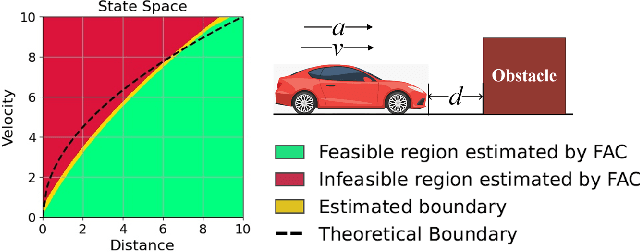


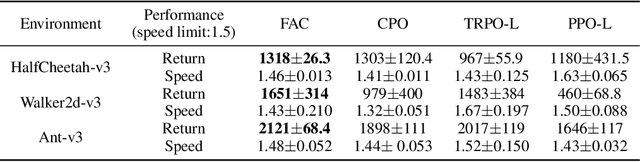
The safety constraints commonly used by existing safe reinforcement learning (RL) methods are defined only on expectation of initial states, but allow each certain state to be unsafe, which is unsatisfying for real-world safety-critical tasks. In this paper, we introduce the feasible actor-critic (FAC) algorithm, which is the first model-free constrained RL method that considers statewise safety, e.g, safety for each initial state. We claim that some states are inherently unsafe no matter what policy we choose, while for other states there exist policies ensuring safety, where we say such states and policies are feasible. By constructing a statewise Lagrange function available on RL sampling and adopting an additional neural network to approximate the statewise Lagrange multiplier, we manage to obtain the optimal feasible policy which ensures safety for each feasible state and the safest possible policy for infeasible states. Furthermore, the trained multiplier net can indicate whether a given state is feasible or not through the statewise complementary slackness condition. We provide theoretical guarantees that FAC outperforms previous expectation-based constrained RL methods in terms of both constraint satisfaction and reward optimization. Experimental results on both robot locomotive tasks and safe exploration tasks verify the safety enhancement and feasibility interpretation of the proposed method.