 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Generative Policy via Langevin-Guided Flow Matching for Autonomous Driving
Mar 03, 2026Reinforcement learning (RL) is a fundamental methodology in autonomous driving systems, where generative policies exhibit considerable potential by leveraging their ability to model complex distributions to enhance exploration. However, their inherent high inference latency severely impedes their deployment in real-time decision-making and control. To address this issue, we propose diffusion actor-critic with entropy regulator via flow matching (DACER-F) by introducing flow matching into online RL, enabling the generation of competitive actions in a single inference step. By leveraging Langevin dynamics and gradients of the Q-function, DACER-F dynamically optimizes actions from experience replay toward a target distribution that balances high Q-value information with exploratory behavior. The flow policy is then trained to efficiently learn a mapping from a simple prior distribution to this dynamic target. In complex multi-lane and intersection simulations, DACER-F outperforms baselines diffusion actor-critic with entropy regulator (DACER) and distributional soft actor-critic (DSAC), while maintaining an ultra-low inference latency. DACER-F further demonstrates its scalability on standard RL benchmark DeepMind Control Suite (DMC), achieving a score of 775.8 in the humanoid-stand task and surpassing prior methods. Collectively, these results establish DACER-F as a high-performance and computationally efficient RL algorithm.
Distributional Soft Actor-Critic with Diffusion Policy
Jul 02, 2025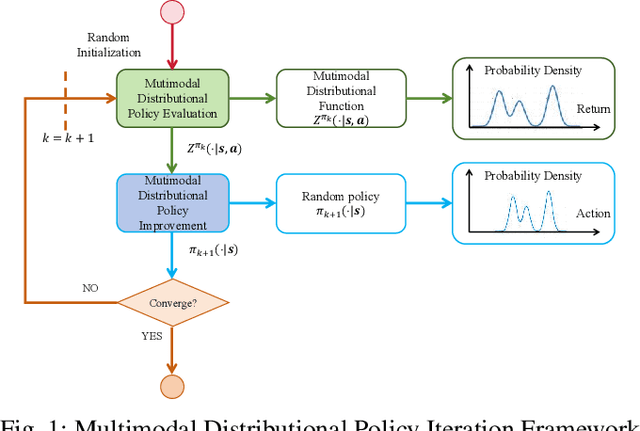
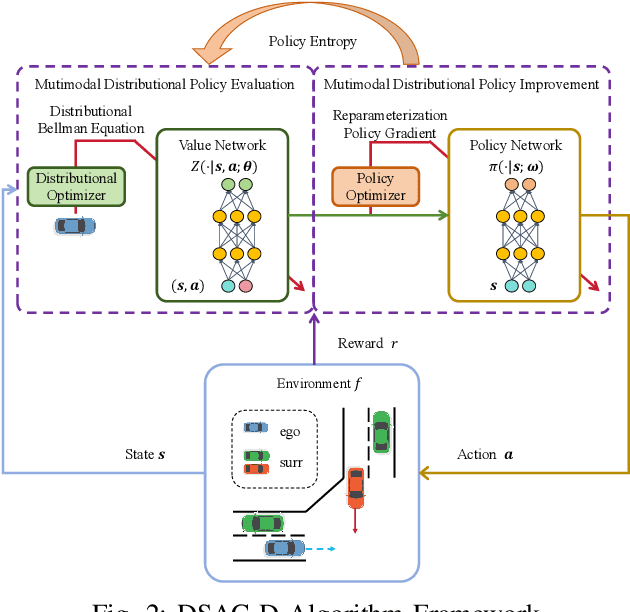

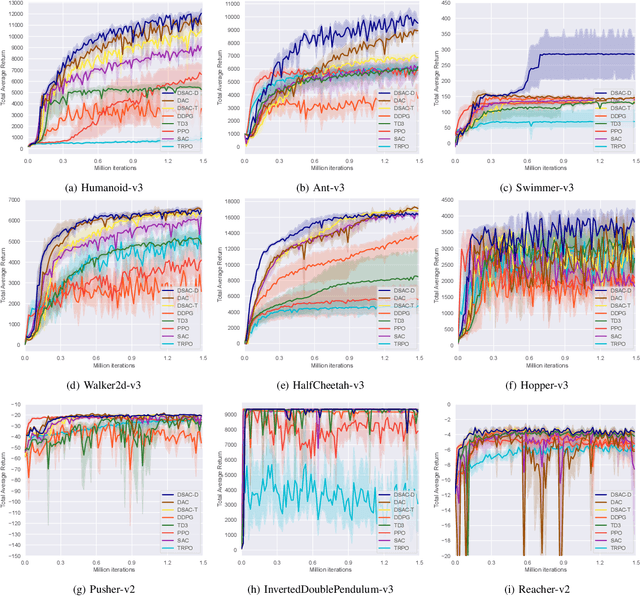
Reinforcement learning has been proven to be highly effective in handling complex control tasks. Traditional methods typically use unimodal distributions, such as Gaussian distributions, to model the output of value distributions. However, unimodal distribution often and easily causes bias in value function estimation, leading to poor algorithm performance. This paper proposes a distributional reinforcement learning algorithm called DSAC-D (Distributed Soft Actor Critic with Diffusion Policy) to address the challenges of estimating bias in value functions and obtaining multimodal policy representations. A multimodal distributional policy iteration framework that can converge to the optimal policy was established by introducing policy entropy and value distribution function. A diffusion value network that can accurately characterize the distribution of multi peaks was constructed by generating a set of reward samples through reverse sampling using a diffusion model. Based on this, a distributional reinforcement learning algorithm with dual diffusion of the value network and the policy network was derived. MuJoCo testing tasks demonstrate that the proposed algorithm not only learns multimodal policy, but also achieves state-of-the-art (SOTA) performance in all 9 control tasks, with significant suppression of estimation bias and total average return improvement of over 10\% compared to existing mainstream algorithms. The results of real vehicle testing show that DSAC-D can accurately characterize the multimodal distribution of different driving styles, and the diffusion policy network can characterize multimodal trajectories.
Enhanced DACER Algorithm with High Diffusion Efficiency
May 29, 2025Due to their expressive capacity, diffusion models have shown great promise in offline RL and imitation learning. Diffusion Actor-Critic with Entropy Regulator (DACER) extended this capability to online RL by using the reverse diffusion process as a policy approximator, trained end-to-end with policy gradient methods, achieving strong performance. However, this comes at the cost of requiring many diffusion steps, which significantly hampers training efficiency, while directly reducing the steps leads to noticeable performance degradation. Critically, the lack of inference efficiency becomes a significant bottleneck for applying diffusion policies in real-time online RL settings. To improve training and inference efficiency while maintaining or even enhancing performance, we propose a Q-gradient field objective as an auxiliary optimization target to guide the denoising process at each diffusion step. Nonetheless, we observe that the independence of the Q-gradient field from the diffusion time step negatively impacts the performance of the diffusion policy. To address this, we introduce a temporal weighting mechanism that enables the model to efficiently eliminate large-scale noise in the early stages and refine actions in the later stages. Experimental results on MuJoCo benchmarks and several multimodal tasks demonstrate that the DACER2 algorithm achieves state-of-the-art performance in most MuJoCo control tasks with only five diffusion steps, while also exhibiting stronger multimodality compared to DACER.
Diffusion Actor-Critic with Entropy Regulator
May 24, 2024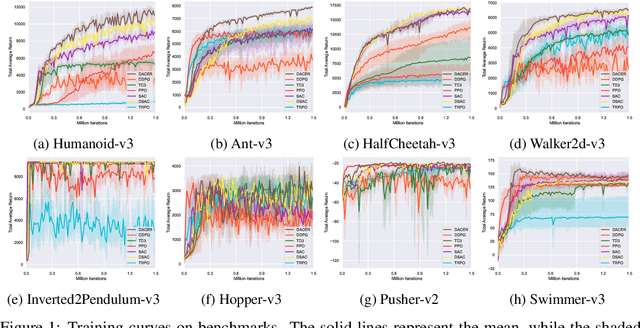
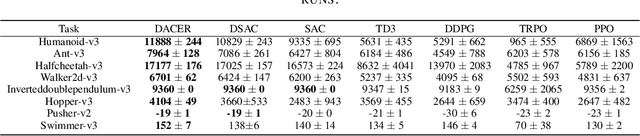
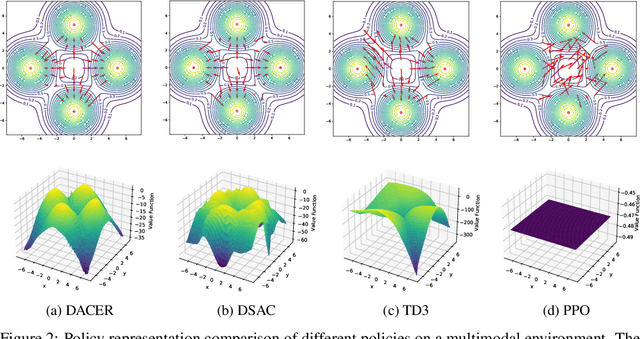
Reinforcement learning (RL) has proven highly effective in addressing complex decision-making and control tasks. However, in most traditional RL algorithms, the policy is typically parameterized as a diagonal Gaussian distribution with learned mean and variance, which constrains their capability to acquire complex policies. In response to this problem, we propose an online RL algorithm termed diffusion actor-critic with entropy regulator (DACER). This algorithm conceptualizes the reverse process of the diffusion model as a novel policy function and leverages the capability of the diffusion model to fit multimodal distributions, thereby enhancing the representational capacity of the policy. Since the distribution of the diffusion policy lacks an analytical expression, its entropy cannot be determined analytically. To mitigate this, we propose a method to estimate the entropy of the diffusion policy utilizing Gaussian mixture model. Building on the estimated entropy, we can learn a parameter $\alpha$ that modulates the degree of exploration and exploitation. Parameter $\alpha$ will be employed to adaptively regulate the variance of the added noise, which is applied to the action output by the diffusion model. Experimental trials on MuJoCo benchmarks and a multimodal task demonstrate that the DACER algorithm achieves state-of-the-art (SOTA) performance in most MuJoCo control tasks while exhibiting a stronger representational capacity of the diffusion policy.
Policy Bifurcation in Safe Reinforcement Learning
Mar 28, 2024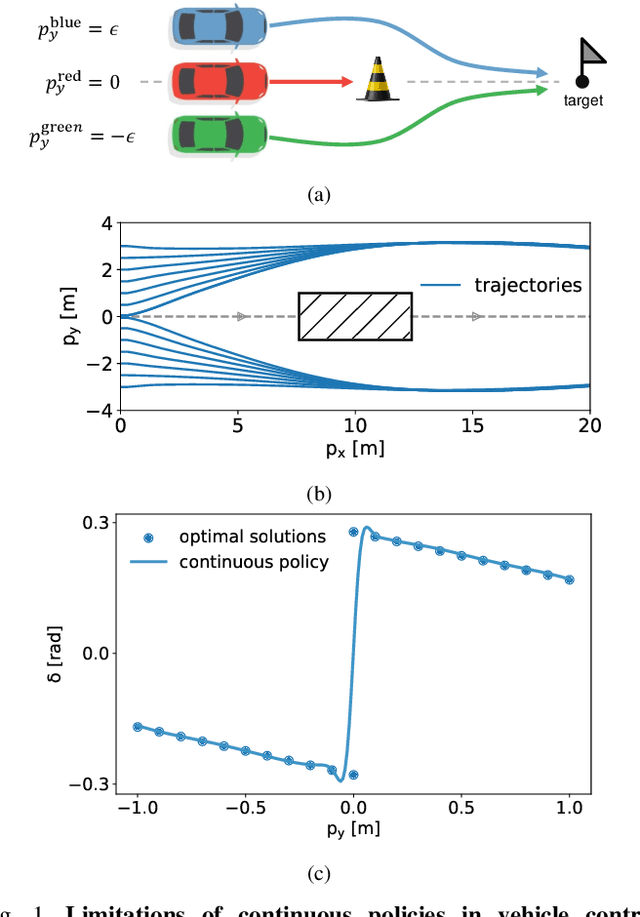
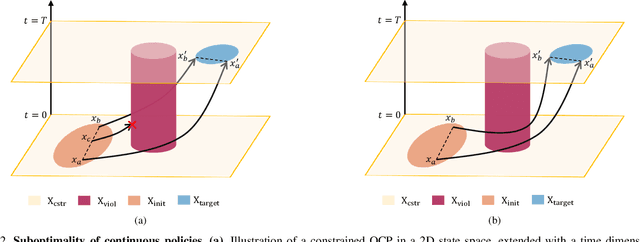
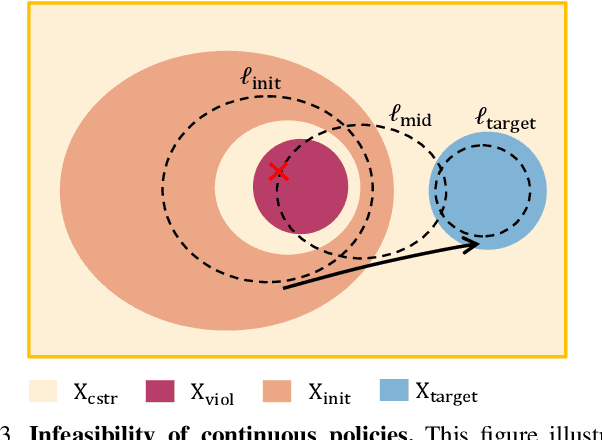
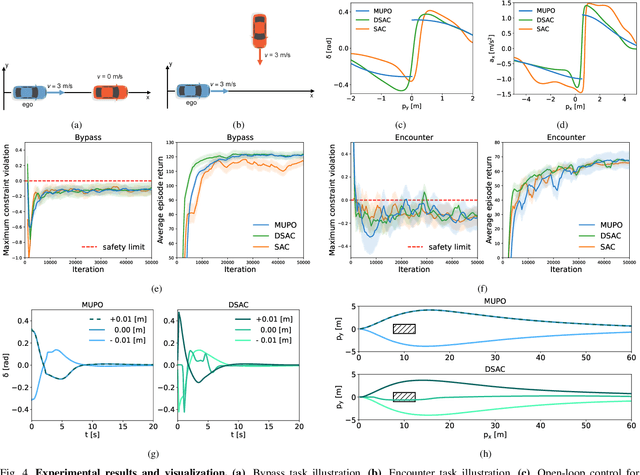
Safe reinforcement learning (RL) offers advanced solutions to constrained optimal control problems. Existing studies in safe RL implicitly assume continuity in policy functions, where policies map states to actions in a smooth, uninterrupted manner; however, our research finds that in some scenarios, the feasible policy should be discontinuous or multi-valued, interpolating between discontinuous local optima can inevitably lead to constraint violations. We are the first to identify the generating mechanism of such a phenomenon, and employ topological analysis to rigorously prove the existence of policy bifurcation in safe RL, which corresponds to the contractibility of the reachable tuple. Our theorem reveals that in scenarios where the obstacle-free state space is non-simply connected, a feasible policy is required to be bifurcated, meaning its output action needs to change abruptly in response to the varying state. To train such a bifurcated policy, we propose a safe RL algorithm called multimodal policy optimization (MUPO), which utilizes a Gaussian mixture distribution as the policy output. The bifurcated behavior can be achieved by selecting the Gaussian component with the highest mixing coefficient. Besides, MUPO also integrates spectral normalization and forward KL divergence to enhance the policy's capability of exploring different modes. Experiments with vehicle control tasks show that our algorithm successfully learns the bifurcated policy and ensures satisfying safety, while a continuous policy suffers from inevitable constraint violations.
Safe Model-Based Reinforcement Learning with an Uncertainty-Aware Reachability Certificate
Oct 14, 2022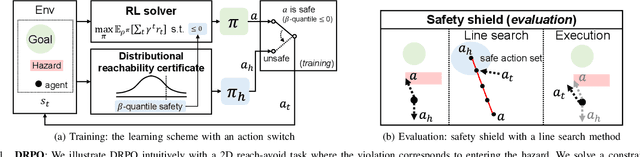
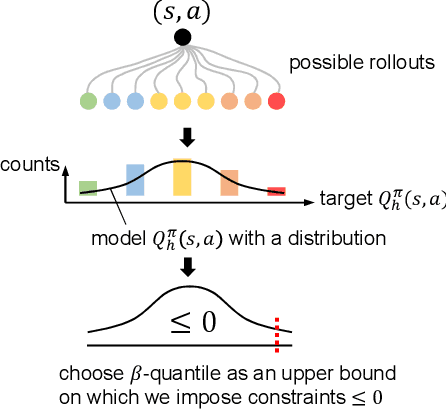
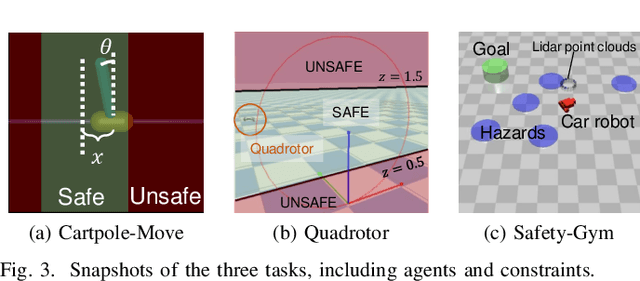
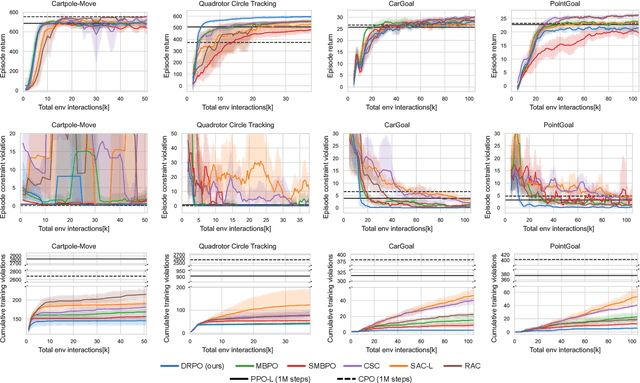
Safe reinforcement learning (RL) that solves constraint-satisfactory policies provides a promising way to the broader safety-critical applications of RL in real-world problems such as robotics. Among all safe RL approaches, model-based methods reduce training time violations further due to their high sample efficiency. However, lacking safety robustness against the model uncertainties remains an issue in safe model-based RL, especially in training time safety. In this paper, we propose a distributional reachability certificate (DRC) and its Bellman equation to address model uncertainties and characterize robust persistently safe states. Furthermore, we build a safe RL framework to resolve constraints required by the DRC and its corresponding shield policy. We also devise a line search method to maintain safety and reach higher returns simultaneously while leveraging the shield policy. Comprehensive experiments on classical benchmarks such as constrained tracking and navigation indicate that the proposed algorithm achieves comparable returns with much fewer constraint violations during training.