 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiKC+: Bimanual Hierarchical Imitation with Keypose-Conditioned Coordination-Aware Consistency Policies
Jan 17, 2026Robots are essential in industrial manufacturing due to their reliability and efficiency. They excel in performing simple and repetitive unimanual tasks but still face challenges with bimanual manipulation. This difficulty arises from the complexities of coordinating dual arms and handling multi-stage processes. Recent integration of generative models into imitation learning (IL) has made progress in tackling specific challenges. However, few approaches explicitly consider the multi-stage nature of bimanual tasks while also emphasizing the importance of inference speed. In multi-stage tasks, failures or delays at any stage can cascade over time, impacting the success and efficiency of subsequent sub-stages and ultimately hindering overall task performance. In this paper, we propose a novel keypose-conditioned coordination-aware consistency policy tailored for bimanual manipulation. Our framework instantiates hierarchical imitation learning with a high-level keypose predictor and a low-level trajectory generator. The predicted keyposes serve as sub-goals for trajectory generation, indicating targets for individual sub-stages. The trajectory generator is formulated as a consistency model, generating action sequences based on historical observations and predicted keyposes in a single inference step. In particular, we devise an innovative approach for identifying bimanual keyposes, considering both robot-centric action features and task-centric operation styles. Simulation and real-world experiments illustrate that our approach significantly outperforms baseline methods in terms of success rates and operational efficiency. Implementation codes can be found at https://github.com/JoanaHXU/BiKC-plus.
SViP: Sequencing Bimanual Visuomotor Policies with Object-Centric Motion Primitives
Jun 23, 2025Imitation learning (IL), particularly when leveraging high-dimensional visual inputs for policy training, has proven intuitive and effective in complex bimanual manipulation tasks. Nonetheless, the generalization capability of visuomotor policies remains limited, especially when small demonstration datasets are available. Accumulated errors in visuomotor policies significantly hinder their ability to complete long-horizon tasks. To address these limitations, we propose SViP, a framework that seamlessly integrates visuomotor policies into task and motion planning (TAMP). SViP partitions human demonstrations into bimanual and unimanual operations using a semantic scene graph monitor. Continuous decision variables from the key scene graph are employed to train a switching condition generator. This generator produces parameterized scripted primitives that ensure reliable performance even when encountering out-of-the-distribution observations. Using only 20 real-world demonstrations, we show that SViP enables visuomotor policies to generalize across out-of-distribution initial conditions without requiring object pose estimators. For previously unseen tasks, SViP automatically discovers effective solutions to achieve the goal, leveraging constraint modeling in TAMP formulism. In real-world experiments, SViP outperforms state-of-the-art generative IL methods, indicating wider applicability for more complex tasks. Project website: https://sites.google.com/view/svip-bimanual
BiKC: Keypose-Conditioned Consistency Policy for Bimanual Robotic Manipulation
Jun 14, 2024



Bimanual manipulation tasks typically involve multiple stages which require efficient interactions between two arms, posing step-wise and stage-wise challenges for imitation learning systems. Specifically, failure and delay of one step will broadcast through time, hinder success and efficiency of each sub-stage task, and thereby overall task performance. Although recent works have made strides in addressing certain challenges, few approaches explicitly consider the multi-stage nature of bimanual tasks while simultaneously emphasizing the importance of inference speed. In this paper, we introduce a novel keypose-conditioned consistency policy tailored for bimanual manipulation. It is a hierarchical imitation learning framework that consists of a high-level keypose predictor and a low-level trajectory generator. The predicted keyposes provide guidance for trajectory generation and also mark the completion of one sub-stage task. The trajectory generator is designed as a consistency model trained from scratch without distillation, which generates action sequences conditioning on current observations and predicted keyposes with fast inference speed. Simulated and real-world experimental results demonstrate that the proposed approach surpasses baseline methods in terms of success rate and operational efficiency.
Safe Offline Reinforcement Learning with Feasibility-Guided Diffusion Model
Jan 19, 2024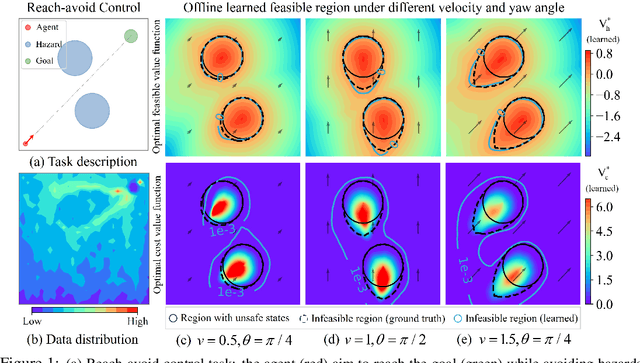

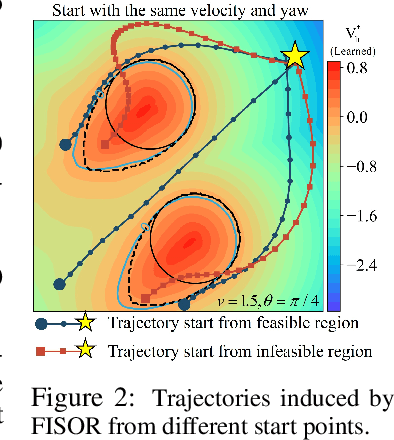

Safe offline RL is a promising way to bypass risky online interactions towards safe policy learning. Most existing methods only enforce soft constraints, i.e., constraining safety violations in expectation below thresholds predetermined. This can lead to potentially unsafe outcomes, thus unacceptable in safety-critical scenarios. An alternative is to enforce the hard constraint of zero violation. However, this can be challenging in offline setting, as it needs to strike the right balance among three highly intricate and correlated aspects: safety constraint satisfaction, reward maximization, and behavior regularization imposed by offline datasets. Interestingly, we discover that via reachability analysis of safe-control theory, the hard safety constraint can be equivalently translated to identifying the largest feasible region given the offline dataset. This seamlessly converts the original trilogy problem to a feasibility-dependent objective, i.e., maximizing reward value within the feasible region while minimizing safety risks in the infeasible region. Inspired by these, we propose FISOR (FeasIbility-guided Safe Offline RL), which allows safety constraint adherence, reward maximization, and offline policy learning to be realized via three decoupled processes, while offering strong safety performance and stability. In FISOR, the optimal policy for the translated optimization problem can be derived in a special form of weighted behavior cloning. Thus, we propose a novel energy-guided diffusion model that does not require training a complicated time-dependent classifier to extract the policy, greatly simplifying the training. We compare FISOR against baselines on DSRL benchmark for safe offline RL. Evaluation results show that FISOR is the only method that can guarantee safety satisfaction in all tasks, while achieving top returns in most tasks.
Safe Model-Based Reinforcement Learning with an Uncertainty-Aware Reachability Certificate
Oct 14, 2022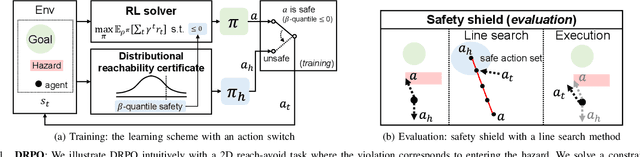
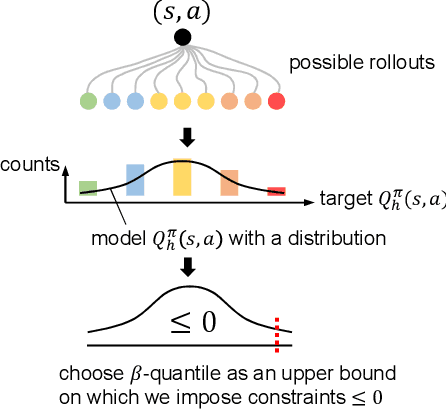
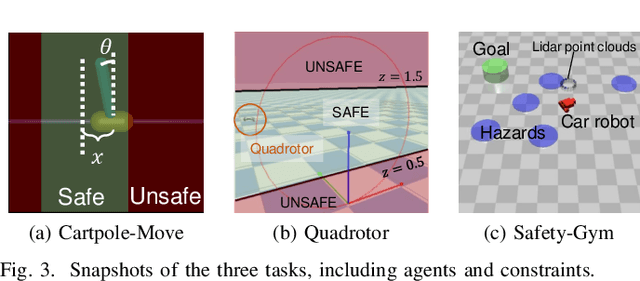
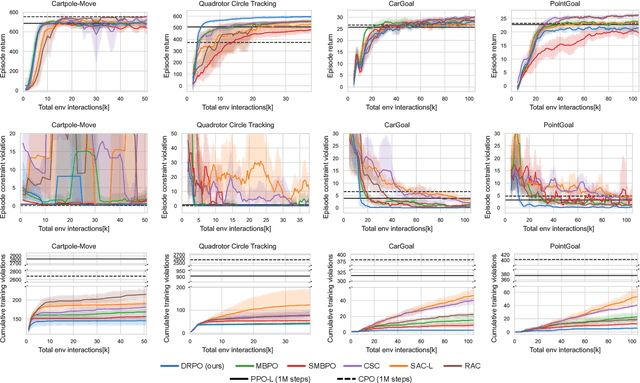
Safe reinforcement learning (RL) that solves constraint-satisfactory policies provides a promising way to the broader safety-critical applications of RL in real-world problems such as robotics. Among all safe RL approaches, model-based methods reduce training time violations further due to their high sample efficiency. However, lacking safety robustness against the model uncertainties remains an issue in safe model-based RL, especially in training time safety. In this paper, we propose a distributional reachability certificate (DRC) and its Bellman equation to address model uncertainties and characterize robust persistently safe states. Furthermore, we build a safe RL framework to resolve constraints required by the DRC and its corresponding shield policy. We also devise a line search method to maintain safety and reach higher returns simultaneously while leveraging the shield policy. Comprehensive experiments on classical benchmarks such as constrained tracking and navigation indicate that the proposed algorithm achieves comparable returns with much fewer constraint violations during training.
Reachability Constrained Reinforcement Learning
May 16, 2022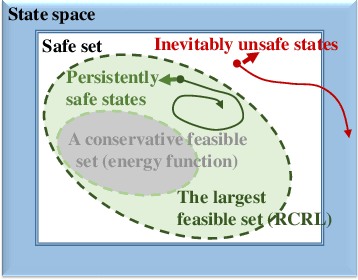
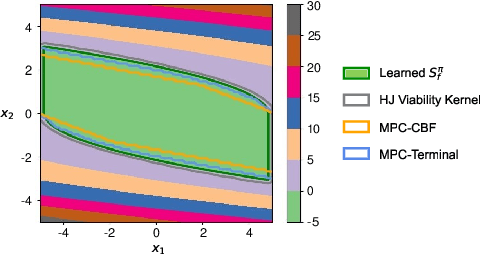
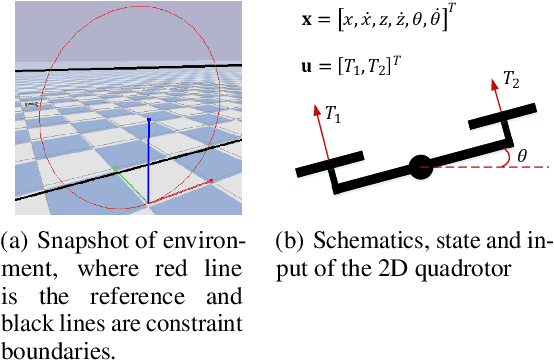
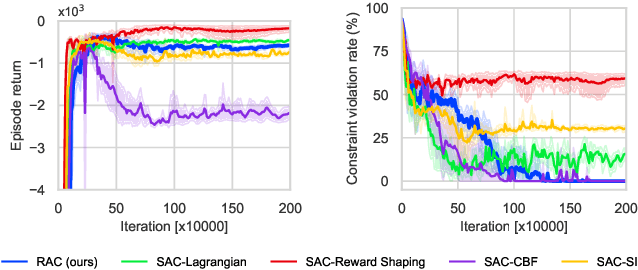
Constrained Reinforcement Learning (CRL) has gained significant interest recently, since the satisfaction of safety constraints is critical for real world problems. However, existing CRL methods constraining discounted cumulative costs generally lack rigorous definition and guarantee of safety. On the other hand, in the safe control research, safety is defined as persistently satisfying certain state constraints. Such persistent safety is possible only on a subset of the state space, called feasible set, where an optimal largest feasible set exists for a given environment. Recent studies incorporating safe control with CRL using energy-based methods such as control barrier function (CBF), safety index (SI) leverage prior conservative estimation of feasible sets, which harms performance of the learned policy. To deal with this problem, this paper proposes a reachability CRL (RCRL) method by using reachability analysis to characterize the largest feasible sets. We characterize the feasible set by the established self-consistency condition, then a safety value function can be learned and used as constraints in CRL. We also use the multi-time scale stochastic approximation theory to prove that the proposed algorithm converges to a local optimum, where the largest feasible set can be guaranteed. Empirical results on different benchmarks such as safe-control-gym and Safety-Gym validate the learned feasible set, the performance in optimal criteria, and constraint satisfaction of RCRL, compared to state-of-the-art CRL baselines.
Rethinking Pretraining as a Bridge from ANNs to SNNs
Mar 04, 2022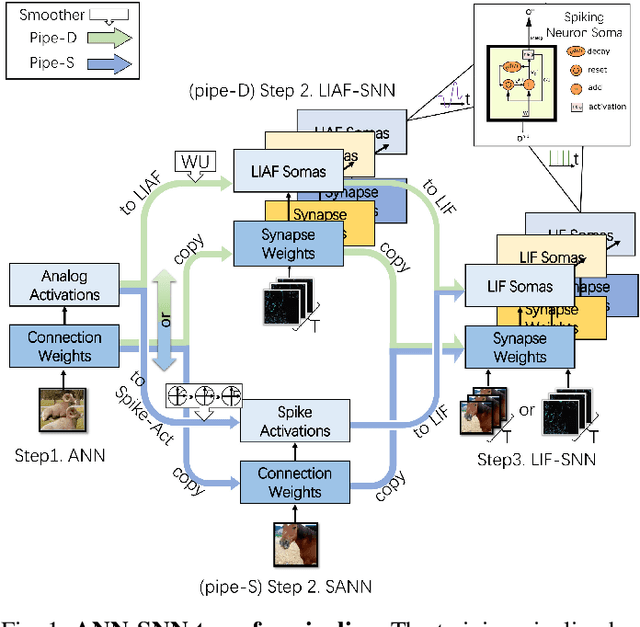
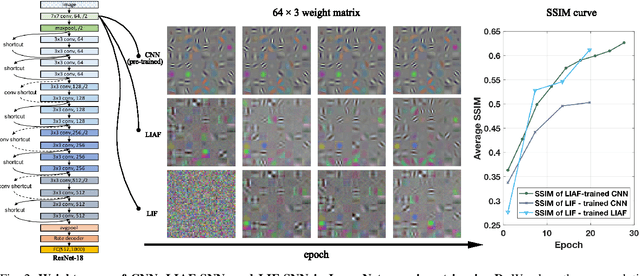
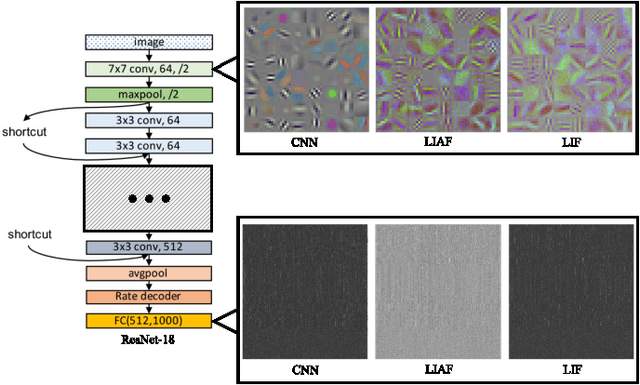
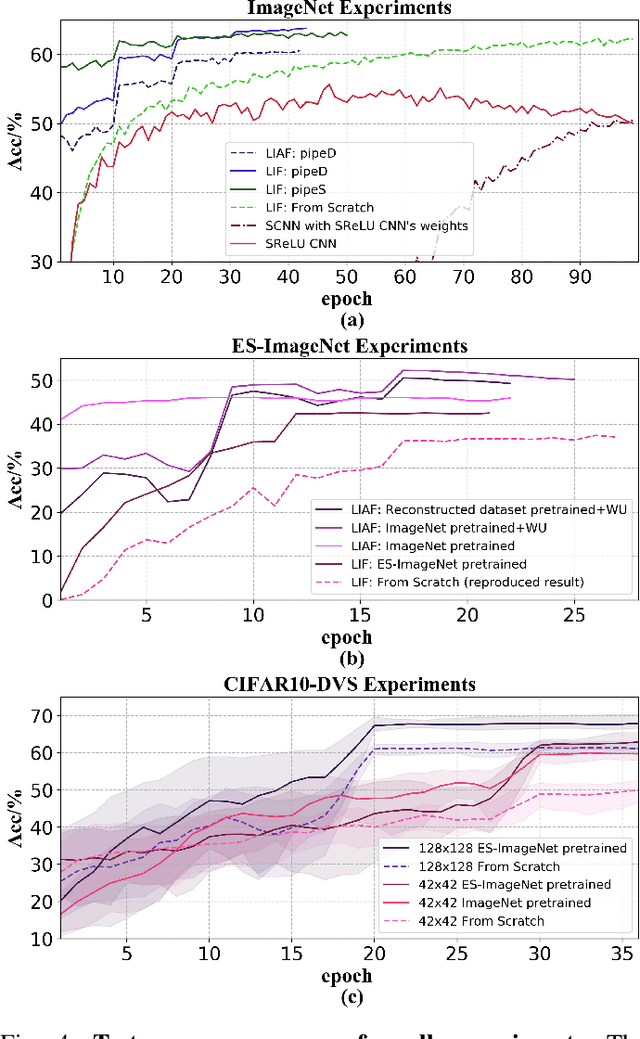
Spiking neural networks (SNNs) are known as a typical kind of brain-inspired models with their unique features of rich neuronal dynamics, diverse coding schemes and low power consumption properties. How to obtain a high-accuracy model has always been the main challenge in the field of SNN. Currently, there are two mainstream methods, i.e., obtaining a converted SNN through converting a well-trained Artificial Neural Network (ANN) to its SNN counterpart or training an SNN directly. However, the inference time of a converted SNN is too long, while SNN training is generally very costly and inefficient. In this work, a new SNN training paradigm is proposed by combining the concepts of the two different training methods with the help of the pretrain technique and BP-based deep SNN training mechanism. We believe that the proposed paradigm is a more efficient pipeline for training SNNs. The pipeline includes pipeS for static data transfer tasks and pipeD for dynamic data transfer tasks. SOTA results are obtained in a large-scale event-driven dataset ES-ImageNet. For training acceleration, we achieve the same (or higher) best accuracy as similar LIF-SNNs using 1/10 training time on ImageNet-1K and 2/5 training time on ES-ImageNet and also provide a time-accuracy benchmark for a new dataset ES-UCF101. These experimental results reveal the similarity of the functions of parameters between ANNs and SNNs and also demonstrate the various potential applications of this SNN training pipeline.
Self-learned Intelligence for Integrated Decision and Control of Automated Vehicles at Signalized Intersections
Nov 10, 2021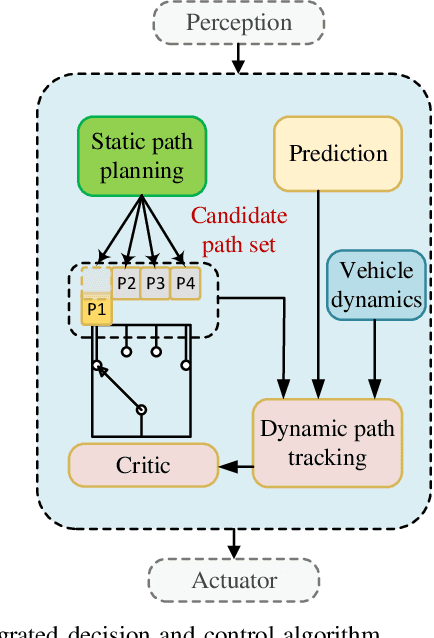
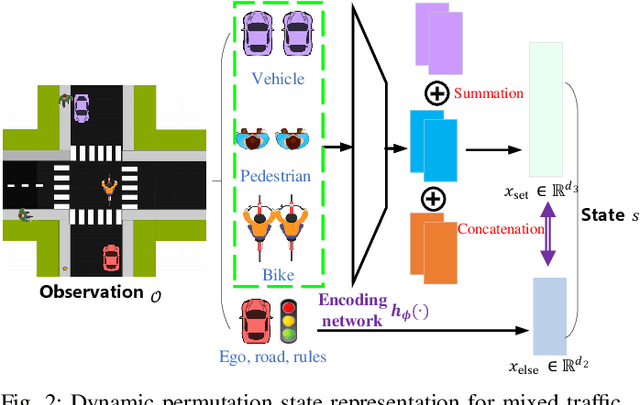
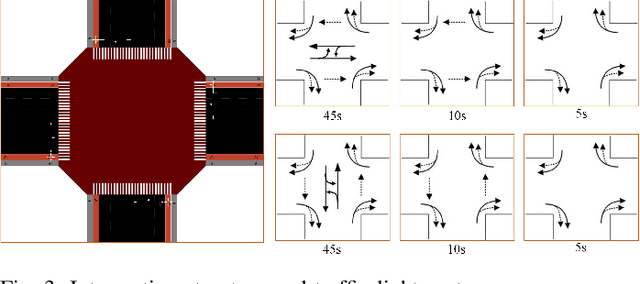
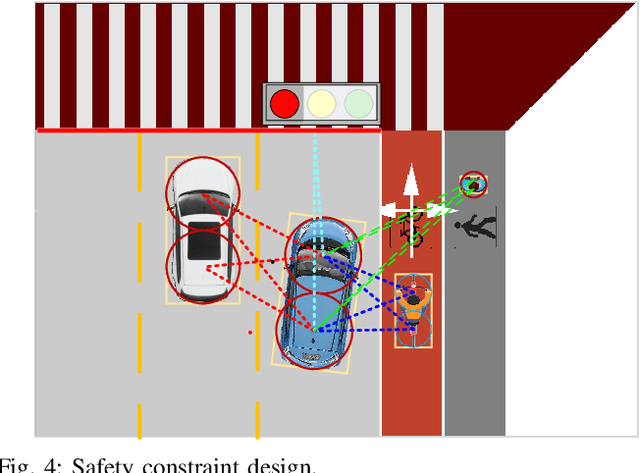
Intersection is one of the most complex and accident-prone urban scenarios for autonomous driving wherein making safe and computationally efficient decisions is non-trivial. Current research mainly focuses on the simplified traffic conditions while ignoring the existence of mixed traffic flows, i.e., vehicles, cyclists and pedestrians. For urban roads, different participants leads to a quite dynamic and complex interaction, posing great difficulty to learn an intelligent policy. This paper develops the dynamic permutation state representation in the framework of integrated decision and control (IDC) to handle signalized intersections with mixed traffic flows. Specially, this representation introduces an encoding function and summation operator to construct driving states from environmental observation, capable of dealing with different types and variant number of traffic participants. A constrained optimal control problem is built wherein the objective involves tracking performance and the constraints for different participants and signal lights are designed respectively to assure safety. We solve this problem by offline optimizing encoding function, value function and policy function, wherein the reasonable state representation will be given by the encoding function and then served as the input of policy and value function. An off-policy training is designed to reuse observations from driving environment and backpropagation through time is utilized to update the policy function and encoding function jointly. Verification result shows that the dynamic permutation state representation can enhance the driving performance of IDC, including comfort, decision compliance and safety with a large margin. The trained driving policy can realize efficient and smooth passing in the complex intersection, guaranteeing driving intelligence and safety simultaneously.
Encoding Distributional Soft Actor-Critic for Autonomous Driving in Multi-lane Scenarios
Sep 12, 2021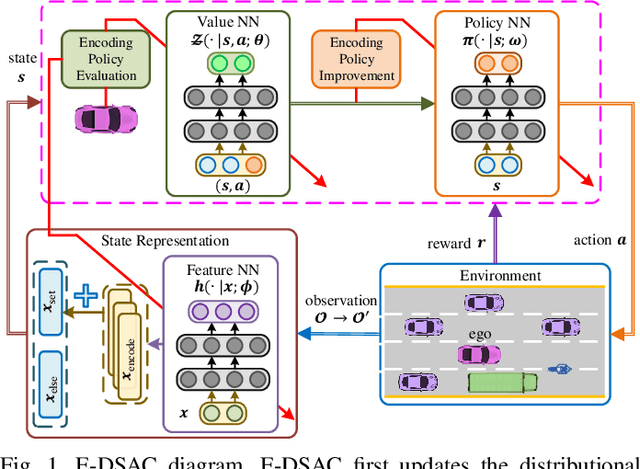
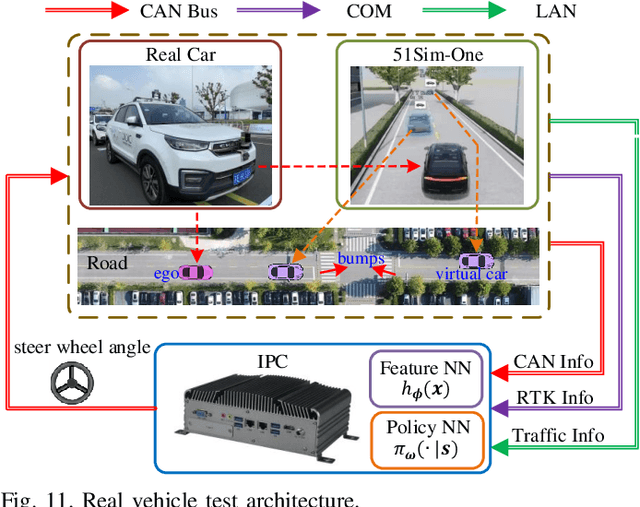
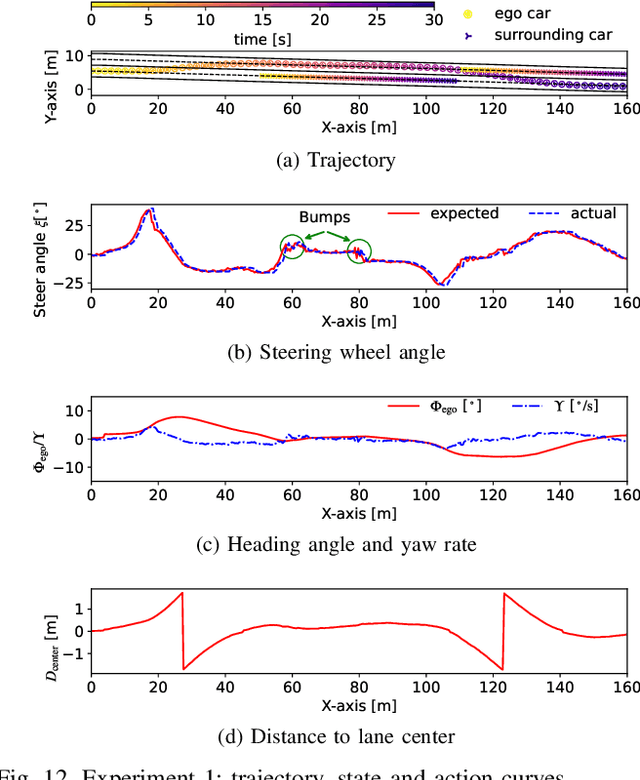
In this paper, we propose a new reinforcement learning (RL) algorithm, called encoding distributional soft actor-critic (E-DSAC), for decision-making in autonomous driving. Unlike existing RL-based decision-making methods, E-DSAC is suitable for situations where the number of surrounding vehicles is variable and eliminates the requirement for manually pre-designed sorting rules, resulting in higher policy performance and generality. We first develop an encoding distributional policy iteration (DPI) framework by embedding a permutation invariant module, which employs a feature neural network (NN) to encode the indicators of each vehicle, in the distributional RL framework. The proposed DPI framework is proved to exhibit important properties in terms of convergence and global optimality. Next, based on the developed encoding DPI framework, we propose the E-DSAC algorithm by adding the gradient-based update rule of the feature NN to the policy evaluation process of the DSAC algorithm. Then, the multi-lane driving task and the corresponding reward function are designed to verify the effectiveness of the proposed algorithm. Results show that the policy learned by E-DSAC can realize efficient, smooth, and relatively safe autonomous driving in the designed scenario. And the final policy performance learned by E-DSAC is about three times that of DSAC. Furthermore, its effectiveness has also been verified in real vehicle experiments.
Fixed-Dimensional and Permutation Invariant State Representation of Autonomous Driving
May 24, 2021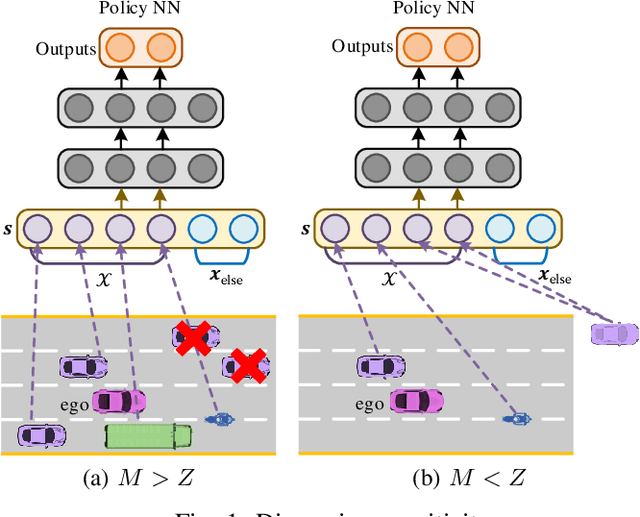
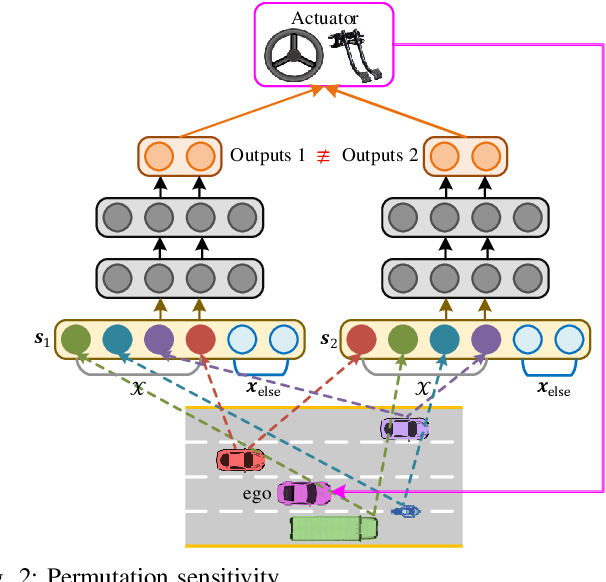
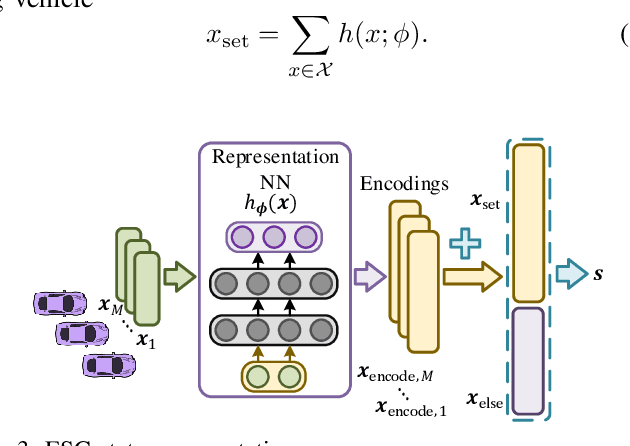
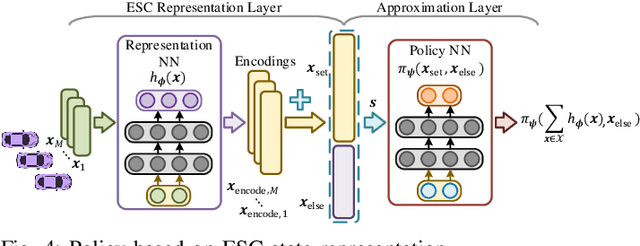
In this paper, we propose a new state representation method, called encoding sum and concatenation (ESC), for the state representation of decision-making in autonomous driving. Unlike existing state representation methods, ESC is applicable to a variable number of surrounding vehicles and eliminates the need for manually pre-designed sorting rules, leading to higher representation ability and generality. The proposed ESC method introduces a representation neural network (NN) to encode each surrounding vehicle into an encoding vector, and then adds these vectors to obtain the representation vector of the set of surrounding vehicles. By concatenating the set representation with other variables, such as indicators of the ego vehicle and road, we realize the fixed-dimensional and permutation invariant state representation. This paper has further proved that the proposed ESC method can realize the injective representation if the output dimension of the representation NN is greater than the number of variables of all surrounding vehicles. This means that by taking the ESC representation as policy inputs, we can find the nearly optimal representation NN and policy NN by simultaneously optimizing them using gradient-based updating. Experiments demonstrate that compared with the fixed-permutation representation method, the proposed method improves the representation ability of the surrounding vehicles, and the corresponding approximation error is reduced by 62.2%.