 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Soft Actor-Critic with Diffusion Policy
Jul 02, 2025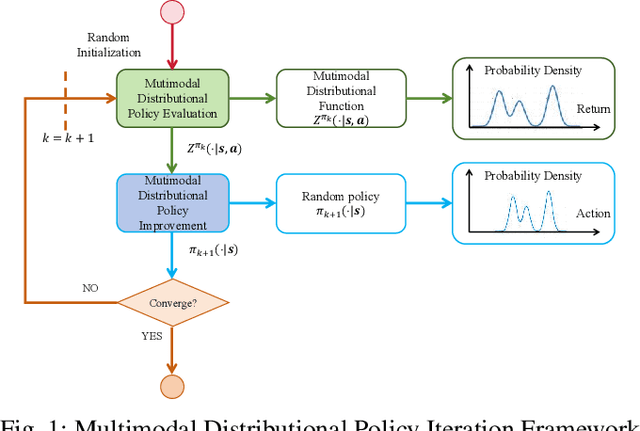
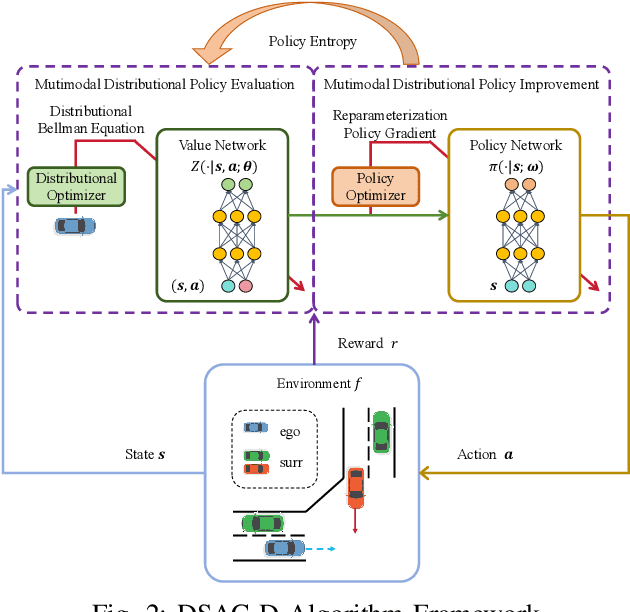

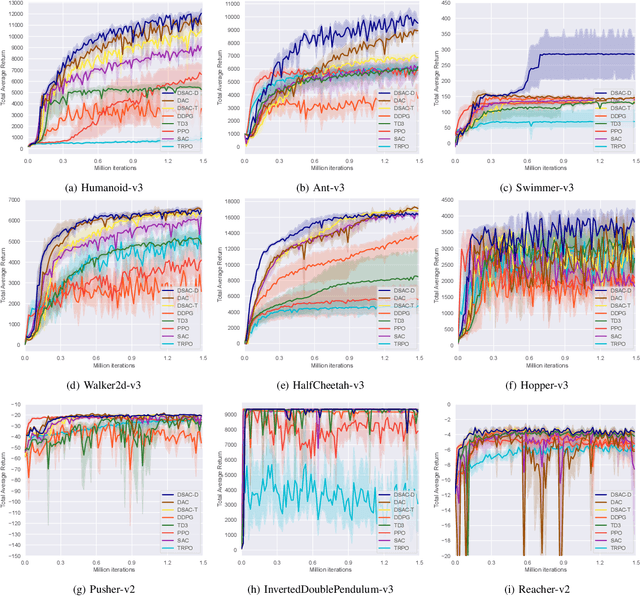
Reinforcement learning has been proven to be highly effective in handling complex control tasks. Traditional methods typically use unimodal distributions, such as Gaussian distributions, to model the output of value distributions. However, unimodal distribution often and easily causes bias in value function estimation, leading to poor algorithm performance. This paper proposes a distributional reinforcement learning algorithm called DSAC-D (Distributed Soft Actor Critic with Diffusion Policy) to address the challenges of estimating bias in value functions and obtaining multimodal policy representations. A multimodal distributional policy iteration framework that can converge to the optimal policy was established by introducing policy entropy and value distribution function. A diffusion value network that can accurately characterize the distribution of multi peaks was constructed by generating a set of reward samples through reverse sampling using a diffusion model. Based on this, a distributional reinforcement learning algorithm with dual diffusion of the value network and the policy network was derived. MuJoCo testing tasks demonstrate that the proposed algorithm not only learns multimodal policy, but also achieves state-of-the-art (SOTA) performance in all 9 control tasks, with significant suppression of estimation bias and total average return improvement of over 10\% compared to existing mainstream algorithms. The results of real vehicle testing show that DSAC-D can accurately characterize the multimodal distribution of different driving styles, and the diffusion policy network can characterize multimodal trajectories.
Enhanced DACER Algorithm with High Diffusion Efficiency
May 29, 2025Due to their expressive capacity, diffusion models have shown great promise in offline RL and imitation learning. Diffusion Actor-Critic with Entropy Regulator (DACER) extended this capability to online RL by using the reverse diffusion process as a policy approximator, trained end-to-end with policy gradient methods, achieving strong performance. However, this comes at the cost of requiring many diffusion steps, which significantly hampers training efficiency, while directly reducing the steps leads to noticeable performance degradation. Critically, the lack of inference efficiency becomes a significant bottleneck for applying diffusion policies in real-time online RL settings. To improve training and inference efficiency while maintaining or even enhancing performance, we propose a Q-gradient field objective as an auxiliary optimization target to guide the denoising process at each diffusion step. Nonetheless, we observe that the independence of the Q-gradient field from the diffusion time step negatively impacts the performance of the diffusion policy. To address this, we introduce a temporal weighting mechanism that enables the model to efficiently eliminate large-scale noise in the early stages and refine actions in the later stages. Experimental results on MuJoCo benchmarks and several multimodal tasks demonstrate that the DACER2 algorithm achieves state-of-the-art performance in most MuJoCo control tasks with only five diffusion steps, while also exhibiting stronger multimodality compared to DACER.
Diffusion Actor-Critic with Entropy Regulator
May 24, 2024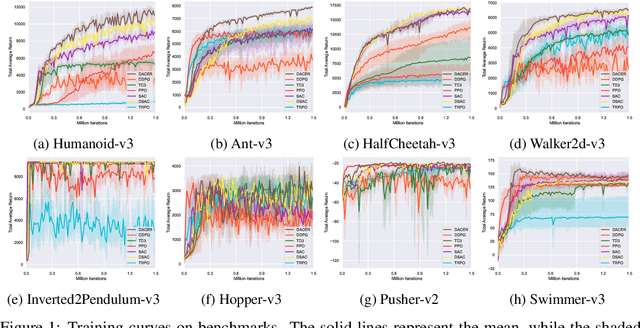
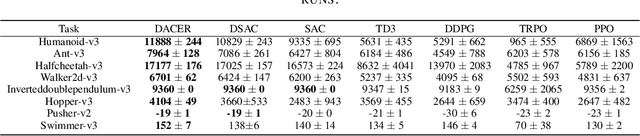
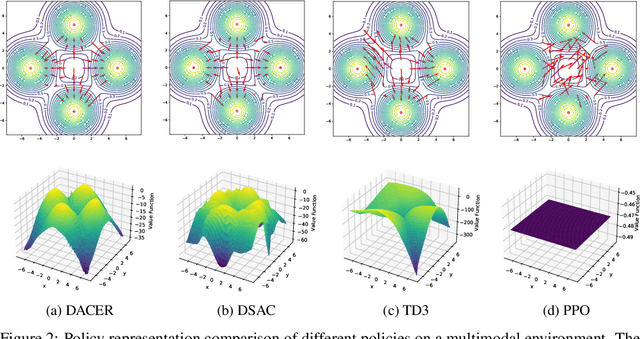
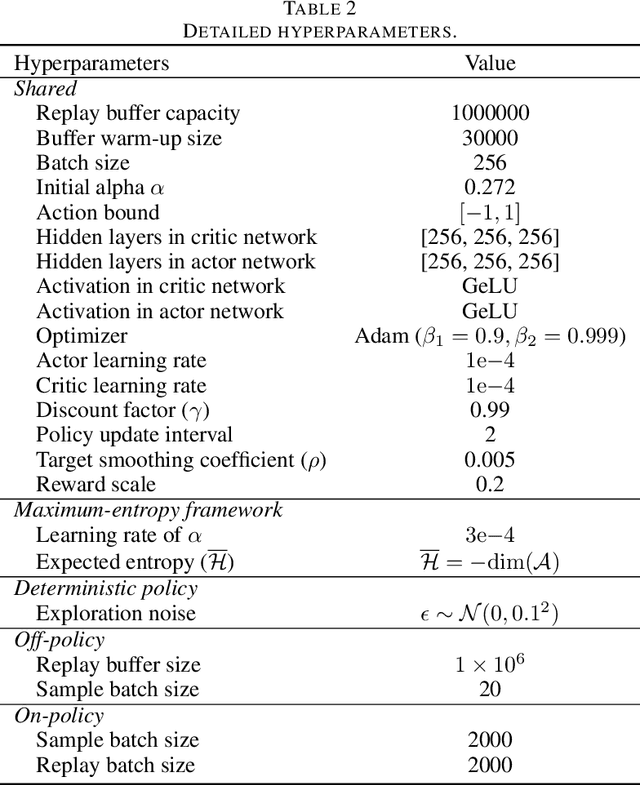
Reinforcement learning (RL) has proven highly effective in addressing complex decision-making and control tasks. However, in most traditional RL algorithms, the policy is typically parameterized as a diagonal Gaussian distribution with learned mean and variance, which constrains their capability to acquire complex policies. In response to this problem, we propose an online RL algorithm termed diffusion actor-critic with entropy regulator (DACER). This algorithm conceptualizes the reverse process of the diffusion model as a novel policy function and leverages the capability of the diffusion model to fit multimodal distributions, thereby enhancing the representational capacity of the policy. Since the distribution of the diffusion policy lacks an analytical expression, its entropy cannot be determined analytically. To mitigate this, we propose a method to estimate the entropy of the diffusion policy utilizing Gaussian mixture model. Building on the estimated entropy, we can learn a parameter $\alpha$ that modulates the degree of exploration and exploitation. Parameter $\alpha$ will be employed to adaptively regulate the variance of the added noise, which is applied to the action output by the diffusion model. Experimental trials on MuJoCo benchmarks and a multimodal task demonstrate that the DACER algorithm achieves state-of-the-art (SOTA) performance in most MuJoCo control tasks while exhibiting a stronger representational capacity of the diffusion policy.
Training Multi-layer Neural Networks on Ising Machine
Nov 06, 2023



As a dedicated quantum device, Ising machines could solve large-scale binary optimization problems in milliseconds. There is emerging interest in utilizing Ising machines to train feedforward neural networks due to the prosperity of generative artificial intelligence. However, existing methods can only train single-layer feedforward networks because of the complex nonlinear network topology. This paper proposes an Ising learning algorithm to train quantized neural network (QNN), by incorporating two essential techinques, namely binary representation of topological network and order reduction of loss function. As far as we know, this is the first algorithm to train multi-layer feedforward networks on Ising machines, providing an alternative to gradient-based backpropagation. Firstly, training QNN is formulated as a quadratic constrained binary optimization (QCBO) problem by representing neuron connection and activation function as equality constraints. All quantized variables are encoded by binary bits based on binary encoding protocol. Secondly, QCBO is converted to a quadratic unconstrained binary optimization (QUBO) problem, that can be efficiently solved on Ising machines. The conversion leverages both penalty function and Rosenberg order reduction, who together eliminate equality constraints and reduce high-order loss function into a quadratic one. With some assumptions, theoretical analysis shows the space complexity of our algorithm is $\mathcal{O}(H^2L + HLN\log H)$, quantifying the required number of Ising spins. Finally, the algorithm effectiveness is validated with a simulated Ising machine on MNIST dataset. After annealing 700 ms, the classification accuracy achieves 98.3%. Among 100 runs, the success probability of finding the optimal solution is 72%. Along with the increasing number of spins on Ising machine, our algorithm has the potential to train deeper neural networks.
Non-zero-sum Game Control for Multi-vehicle Driving via Reinforcement Learning
Feb 08, 2023



When a vehicle drives on the road, its behaviors will be affected by surrounding vehicles. Prediction and decision should not be considered as two separate stages because all vehicles make decisions interactively. This paper constructs the multi-vehicle driving scenario as a non-zero-sum game and proposes a novel game control framework, which consider prediction, decision and control as a whole. The mutual influence of interactions between vehicles is considered in this framework because decisions are made by Nash equilibrium strategy. To efficiently obtain the strategy, ADP, a model-based reinforcement learning method, is used to solve coupled Hamilton-Jacobi-Bellman equations. Driving performance is evaluated by tracking, efficiency, safety and comfort indices. Experiments show that our algorithm could drive perfectly by directly controlling acceleration and steering angle. Vehicles could learn interactive behaviors such as overtaking and pass. In summary, we propose a non-zero-sum game framework for modeling multi-vehicle driving, provide an effective way to solve the Nash equilibrium driving strategy, and validate at non-signalized intersections.
MITNet: GAN Enhanced Magnetic Induction Tomography Based on Complex CNN
Feb 16, 2021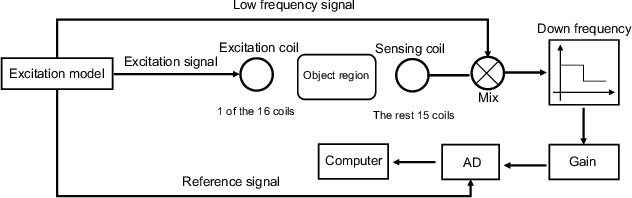
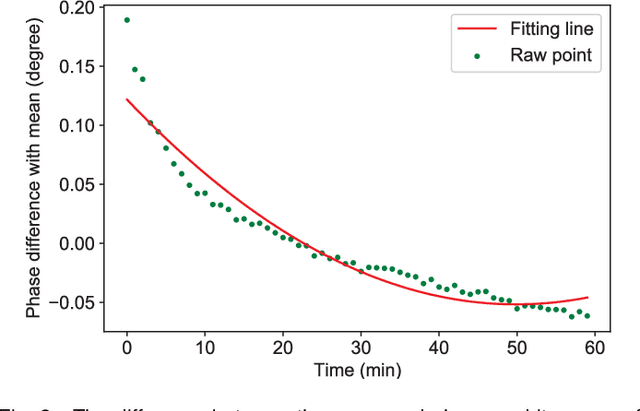
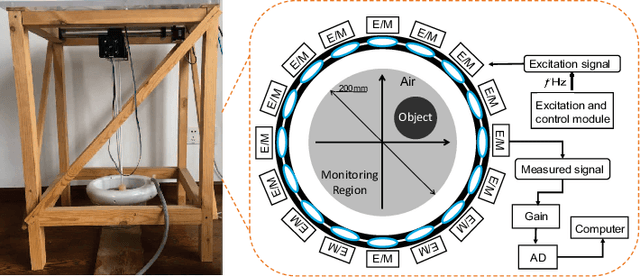
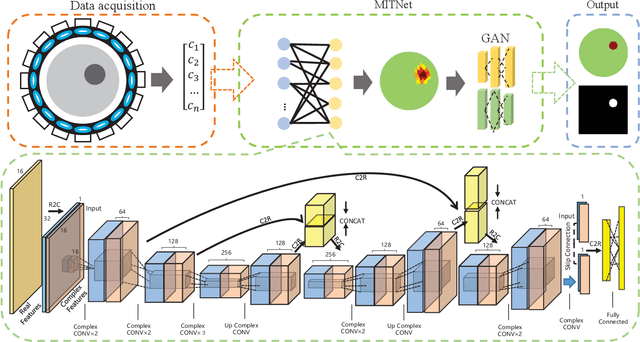
Magnetic induction tomography (MIT) is an efficient solution for long-term brain disease monitoring, which focuses on reconstructing bio-impedance distribution inside the human brain using non-intrusive electromagnetic fields. However, high-quality brain image reconstruction remains challenging since reconstructing images from the measured weak signals is a highly non-linear and ill-conditioned problem. In this work, we propose a generative adversarial network (GAN) enhanced MIT technique, named MITNet, based on a complex convolutional neural network (CNN). The experimental results on the real-world dataset validate the performance of our technique, which outperforms the state-of-art method by 25.27%.