 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Universal Learning-based Model for Cardiac Image Reconstruction: Summary of the CMRxRecon2024 Challenge
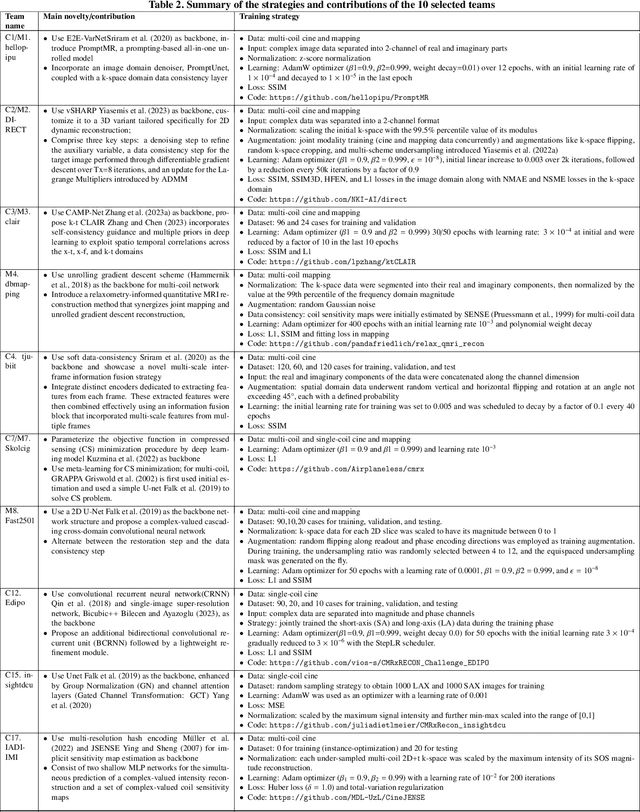
Mar 05, 2025Cardiovascular magnetic resonance (CMR) offers diverse imaging contrasts for assessment of cardiac function and tissue characterization. However, acquiring each single CMR modality is often time-consuming, and comprehensive clinical protocols require multiple modalities with various sampling patterns, further extending the overall acquisition time and increasing susceptibility to motion artifacts. Existing deep learning-based reconstruction methods are often designed for specific acquisition parameters, which limits their ability to generalize across a variety of scan scenarios. As part of the CMRxRecon Series, the CMRxRecon2024 challenge provides diverse datasets encompassing multi-modality multi-view imaging with various sampling patterns, and a platform for the international community to develop and benchmark reconstruction solutions in two well-crafted tasks. Task 1 is a modality-universal setting, evaluating the out-of-distribution generalization of the reconstructed model, while Task 2 follows sampling-universal setting assessing the one-for-all adaptability of the universal model. Main contributions include providing the first and largest publicly available multi-modality, multi-view cardiac k-space dataset; developing a benchmarking platform that simulates clinical acceleration protocols, with a shared code library and tutorial for various k-t undersampling patterns and data processing; giving technical insights of enhanced data consistency based on physic-informed networks and adaptive prompt-learning embedding to be versatile to different clinical settings; additional finding on evaluation metrics to address the limitations of conventional ground-truth references in universal reconstruction tasks.
The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024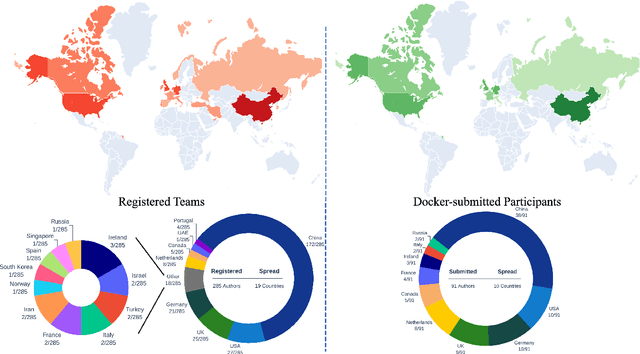
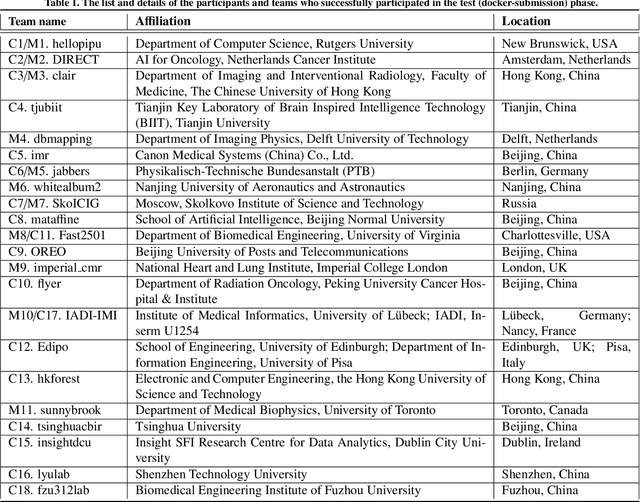
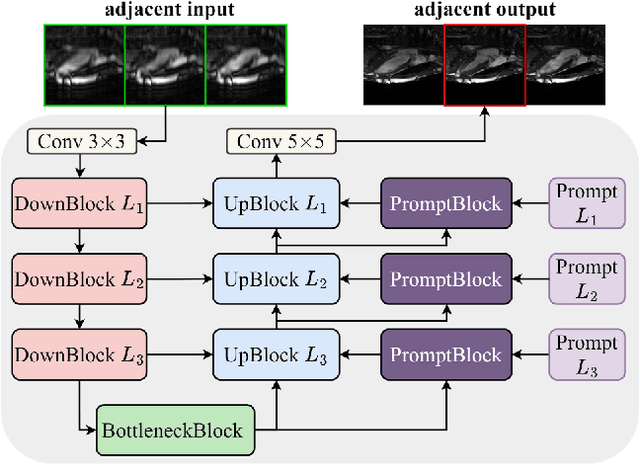
Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
BERT memorisation and pitfalls in low-resource scenarios
Apr 16, 2021State-of-the-art pre-trained models have been shown to memorise facts and perform well with limited amounts of training data. To gain a better understanding of how these models learn, we study their generalisation and memorisation capabilities in noisy and low-resource scenarios. We find that the training of these models is almost unaffected by label noise and that it is possible to reach near-optimal performances even on extremely noisy datasets. Conversely, we also find that they completely fail when tested on low-resource tasks such as few-shot learning and rare entity recognition. To mitigate such limitations, we propose a novel architecture based on BERT and prototypical networks that improves performance in low-resource named entity recognition tasks.