 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
SeeDNorm: Self-Rescaled Dynamic Normalization
Oct 26, 2025Normalization layer constitutes an essential component in neural networks. In transformers, the predominantly used RMSNorm constrains vectors to a unit hypersphere, followed by dimension-wise rescaling through a learnable scaling coefficient $\gamma$ to maintain the representational capacity of the model. However, RMSNorm discards the input norm information in forward pass and a static scaling factor $\gamma$ may be insufficient to accommodate the wide variability of input data and distributional shifts, thereby limiting further performance improvements, particularly in zero-shot scenarios that large language models routinely encounter. To address this limitation, we propose SeeDNorm, which enhances the representational capability of the model by dynamically adjusting the scaling coefficient based on the current input, thereby preserving the input norm information and enabling data-dependent, self-rescaled dynamic normalization. During backpropagation, SeeDNorm retains the ability of RMSNorm to dynamically adjust gradient according to the input norm. We provide a detailed analysis of the training optimization for SeedNorm and proposed corresponding solutions to address potential instability issues that may arise when applying SeeDNorm. We validate the effectiveness of SeeDNorm across models of varying sizes in large language model pre-training as well as supervised and unsupervised computer vision tasks. By introducing a minimal number of parameters and with neglligible impact on model efficiency, SeeDNorm achieves consistently superior performance compared to previously commonly used normalization layers such as RMSNorm and LayerNorm, as well as element-wise activation alternatives to normalization layers like DyT.
UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
Aug 26, 2025



While Mixture of Experts (MoE) models achieve remarkable efficiency by activating only subsets of parameters, they suffer from high memory access costs during inference. Memory-layer architectures offer an appealing alternative with very few memory access, but previous attempts like UltraMem have only matched the performance of 2-expert MoE models, falling significantly short of state-of-the-art 8-expert configurations. We present UltraMemV2, a redesigned memory-layer architecture that closes this performance gap. Our approach introduces five key improvements: integrating memory layers into every transformer block, simplifying value expansion with single linear projections, adopting FFN-based value processing from PEER, implementing principled parameter initialization, and rebalancing memory-to-FFN computation ratios. Through extensive evaluation, we demonstrate that UltraMemV2 achieves performance parity with 8-expert MoE models under same computation and parameters but significantly low memory access. Notably, UltraMemV2 shows superior performance on memory-intensive tasks, with improvements of +1.6 points on long-context memorization, +6.2 points on multi-round memorization, and +7.9 points on in-context learning. We validate our approach at scale with models up to 2.5B activated parameters from 120B total parameters, and establish that activation density has greater impact on performance than total sparse parameter count. Our work brings memory-layer architectures to performance parity with state-of-the-art MoE models, presenting a compelling alternative for efficient sparse computation.
Expert Race: A Flexible Routing Strategy for Scaling Diffusion Transformer with Mixture of Experts
Mar 20, 2025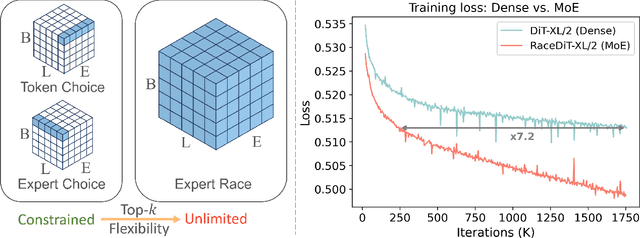



Diffusion models have emerged as mainstream framework in visual generation. Building upon this success, the integration of Mixture of Experts (MoE) methods has shown promise in enhancing model scalability and performance. In this paper, we introduce Race-DiT, a novel MoE model for diffusion transformers with a flexible routing strategy, Expert Race. By allowing tokens and experts to compete together and select the top candidates, the model learns to dynamically assign experts to critical tokens. Additionally, we propose per-layer regularization to address challenges in shallow layer learning, and router similarity loss to prevent mode collapse, ensuring better expert utilization. Extensive experiments on ImageNet validate the effectiveness of our approach, showcasing significant performance gains while promising scaling properties.
Frac-Connections: Fractional Extension of Hyper-Connections
Mar 18, 2025



Residual connections are central to modern deep learning architectures, enabling the training of very deep networks by mitigating gradient vanishing. Hyper-Connections recently generalized residual connections by introducing multiple connection strengths at different depths, thereby addressing the seesaw effect between gradient vanishing and representation collapse. However, Hyper-Connections increase memory access costs by expanding the width of hidden states. In this paper, we propose Frac-Connections, a novel approach that divides hidden states into multiple parts rather than expanding their width. Frac-Connections retain partial benefits of Hyper-Connections while reducing memory consumption. To validate their effectiveness, we conduct large-scale experiments on language tasks, with the largest being a 7B MoE model trained on up to 3T tokens, demonstrating that Frac-Connections significantly outperform residual connections.
Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling
Jan 28, 2025



Tokenization is a fundamental component of large language models (LLMs), yet its influence on model scaling and performance is not fully explored. In this paper, we introduce Over-Tokenized Transformers, a novel framework that decouples input and output vocabularies to improve language modeling performance. Specifically, our approach scales up input vocabularies to leverage multi-gram tokens. Through extensive experiments, we uncover a log-linear relationship between input vocabulary size and training loss, demonstrating that larger input vocabularies consistently enhance model performance, regardless of model size. Using a large input vocabulary, we achieve performance comparable to double-sized baselines with no additional cost. Our findings highlight the importance of tokenization in scaling laws and provide practical insight for tokenizer design, paving the way for more efficient and powerful LLMs.
Ultra-Sparse Memory Network
Nov 19, 2024



It is widely acknowledged that the performance of Transformer models is exponentially related to their number of parameters and computational complexity. While approaches like Mixture of Experts (MoE) decouple parameter count from computational complexity, they still face challenges in inference due to high memory access costs. This work introduces UltraMem, incorporating large-scale, ultra-sparse memory layer to address these limitations. Our approach significantly reduces inference latency while maintaining model performance. We also investigate the scaling laws of this new architecture, demonstrating that it not only exhibits favorable scaling properties but outperforms traditional models. In our experiments, we train networks with up to 20 million memory slots. The results show that our method achieves state-of-the-art inference speed and model performance within a given computational budget.
Hyper-Connections
Sep 29, 2024



We present hyper-connections, a simple yet effective method that can serve as an alternative to residual connections. This approach specifically addresses common drawbacks observed in residual connection variants, such as the seesaw effect between gradient vanishing and representation collapse. Theoretically, hyper-connections allow the network to adjust the strength of connections between features at different depths and dynamically rearrange layers. We conduct experiments focusing on the pre-training of large language models, including dense and sparse models, where hyper-connections show significant performance improvements over residual connections. Additional experiments conducted on vision tasks also demonstrate similar improvements. We anticipate that this method will be broadly applicable and beneficial across a wide range of AI problems.
UGAN: Untraceable GAN for Multi-Domain Face Translation
Sep 12, 2019
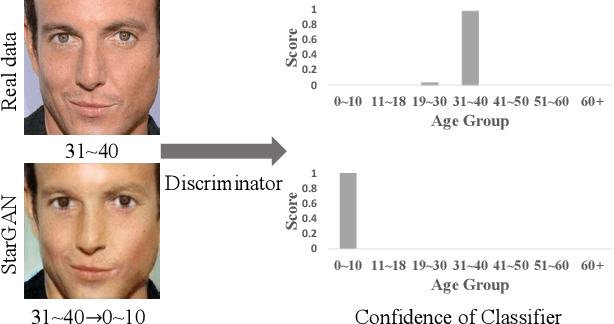
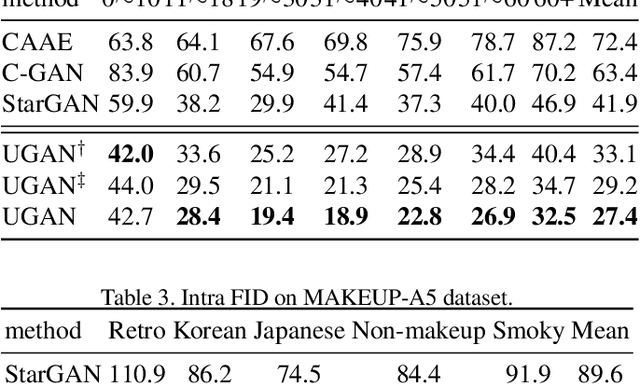
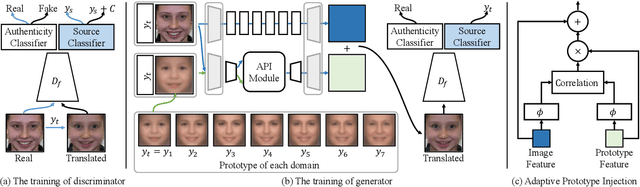
The multi-domain image-to-image translation is a challenging task where the goal is to translate an image into multiple different domains. The target-only characteristics are desired for translated images, while the source-only characteristics should be erased. However, recent methods often suffer from retaining the characteristics of the source domain, which are incompatible with the target domain. To address this issue, we propose a method called Untraceable GAN, which has a novel source classifier to differentiate which domain an image is translated from, and determines whether the translated image still retains the characteristics of the source domain. Furthermore, we take the prototype of the target domain as the guidance for the translator to effectively synthesize the target-only characteristics. The translator is learned to synthesize the target-only characteristics and make the source domain untraceable for the discriminator, so that the source-only characteristics are erased. Finally, extensive experiments on three face editing tasks, including face aging, makeup, and expression editing, show that the proposed UGAN can produce superior results over the state-of-the-art models. The source code will be released.
Face Aging with Contextual Generative Adversarial Nets
Feb 01, 2018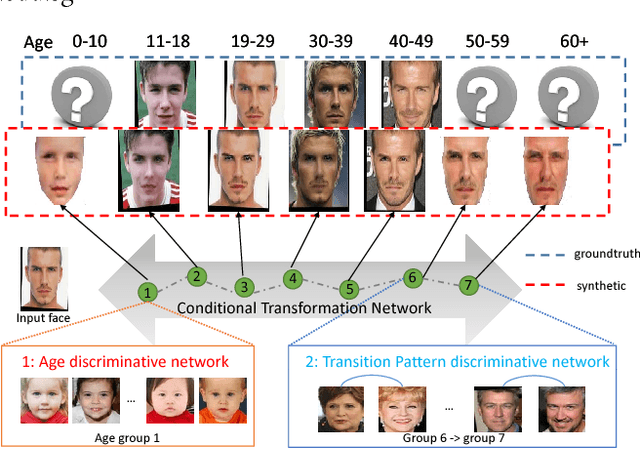

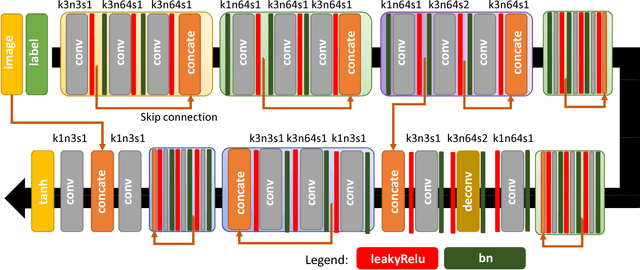
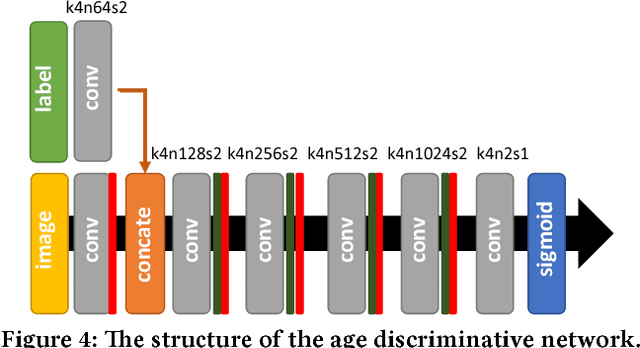
Face aging, which renders aging faces for an input face, has attracted extensive attention in the multimedia research. Recently, several conditional Generative Adversarial Nets (GANs) based methods have achieved great success. They can generate images fitting the real face distributions conditioned on each individual age group. However, these methods fail to capture the transition patterns, e.g., the gradual shape and texture changes between adjacent age groups. In this paper, we propose a novel Contextual Generative Adversarial Nets (C-GANs) to specifically take it into consideration. The C-GANs consists of a conditional transformation network and two discriminative networks. The conditional transformation network imitates the aging procedure with several specially designed residual blocks. The age discriminative network guides the synthesized face to fit the real conditional distribution. The transition pattern discriminative network is novel, aiming to distinguish the real transition patterns with the fake ones. It serves as an extra regularization term for the conditional transformation network, ensuring the generated image pairs to fit the corresponding real transition pattern distribution. Experimental results demonstrate the proposed framework produces appealing results by comparing with the state-of-the-art and ground truth. We also observe performance gain for cross-age face verification.