 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-aware Non-repetitive Multimodal Transformers for TextCaps
Dec 08, 2020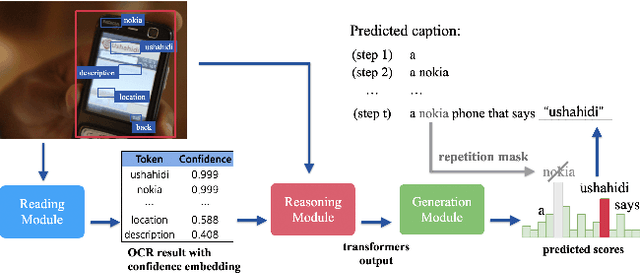
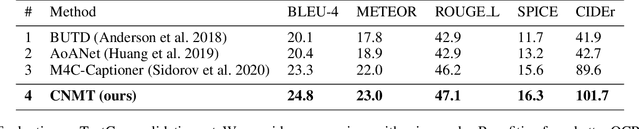
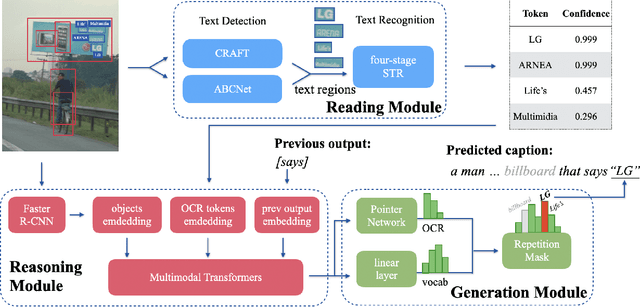

When describing an image, reading text in the visual scene is crucial to understand the key information. Recent work explores the TextCaps task, i.e. image captioning with reading Optical Character Recognition (OCR) tokens, which requires models to read text and cover them in generated captions. Existing approaches fail to generate accurate descriptions because of their (1) poor reading ability; (2) inability to choose the crucial words among all extracted OCR tokens; (3) repetition of words in predicted captions. To this end, we propose a Confidence-aware Non-repetitive Multimodal Transformers (CNMT) to tackle the above challenges. Our CNMT consists of a reading, a reasoning and a generation modules, in which Reading Module employs better OCR systems to enhance text reading ability and a confidence embedding to select the most noteworthy tokens. To address the issue of word redundancy in captions, our Generation Module includes a repetition mask to avoid predicting repeated word in captions. Our model outperforms state-of-the-art models on TextCaps dataset, improving from 81.0 to 93.0 in CIDEr. Our source code is publicly available.
Face Aging with Contextual Generative Adversarial Nets
Feb 01, 2018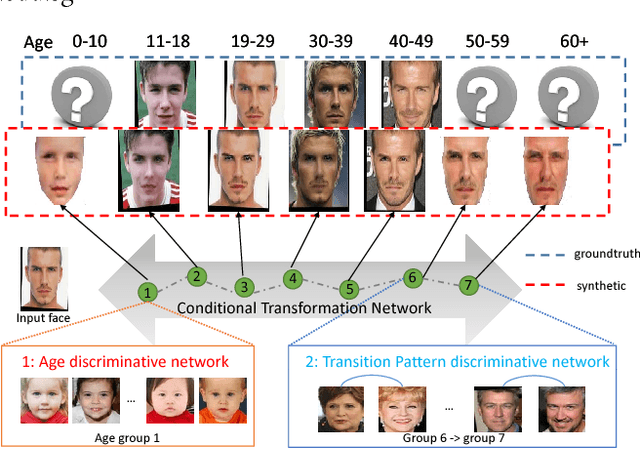

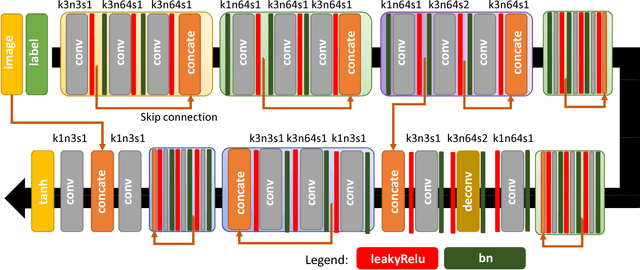
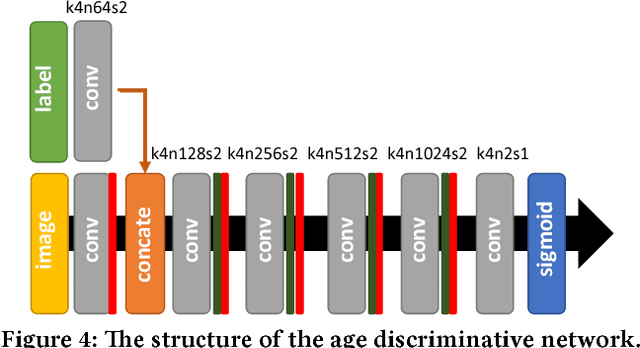
Face aging, which renders aging faces for an input face, has attracted extensive attention in the multimedia research. Recently, several conditional Generative Adversarial Nets (GANs) based methods have achieved great success. They can generate images fitting the real face distributions conditioned on each individual age group. However, these methods fail to capture the transition patterns, e.g., the gradual shape and texture changes between adjacent age groups. In this paper, we propose a novel Contextual Generative Adversarial Nets (C-GANs) to specifically take it into consideration. The C-GANs consists of a conditional transformation network and two discriminative networks. The conditional transformation network imitates the aging procedure with several specially designed residual blocks. The age discriminative network guides the synthesized face to fit the real conditional distribution. The transition pattern discriminative network is novel, aiming to distinguish the real transition patterns with the fake ones. It serves as an extra regularization term for the conditional transformation network, ensuring the generated image pairs to fit the corresponding real transition pattern distribution. Experimental results demonstrate the proposed framework produces appealing results by comparing with the state-of-the-art and ground truth. We also observe performance gain for cross-age face verification.
Surveillance Video Parsing with Single Frame Supervision
Nov 29, 2016

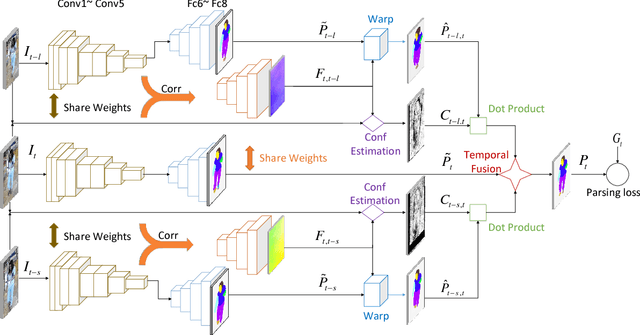

Surveillance video parsing, which segments the video frames into several labels, e.g., face, pants, left-leg, has wide applications. However,pixel-wisely annotating all frames is tedious and inefficient. In this paper, we develop a Single frame Video Parsing (SVP) method which requires only one labeled frame per video in training stage. To parse one particular frame, the video segment preceding the frame is jointly considered. SVP (1) roughly parses the frames within the video segment, (2) estimates the optical flow between frames and (3) fuses the rough parsing results warped by optical flow to produce the refined parsing result. The three components of SVP, namely frame parsing, optical flow estimation and temporal fusion are integrated in an end-to-end manner. Experimental results on two surveillance video datasets show the superiority of SVP over state-of-the-arts.