 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHölder Policy Optimisation
May 12, 2026Group Relative Policy Optimisation (GRPO) enhances large language models by estimating advantages across a group of sampled trajectories. However, mapping these trajectory-level advantages to policy updates requires aggregating token-level probabilities within each sequence. Relying on a fixed aggregation mechanism for this step fundamentally limits the algorithm's adaptability. Empirically, we observe a critical trade-off: certain fixed aggregations frequently suffer from training collapse, while others fail to yield satisfactory performance. To resolve this, we propose \textbf{HölderPO}, a generalised policy optimisation framework unifying token-level probability aggregation via the Hölder mean. By explicitly modulating the parameter $p$, our framework provides continuous control over the trade-off between gradient concentration and variance bounds. Theoretically, we prove that a larger $p$ concentrates the gradient to amplify sparse learning signals, whereas a smaller $p$ strictly bounds gradient variance. Because no static configuration can universally resolve this concentration-stability trade-off, we instantiate the framework with a dynamic annealing algorithm that progressively schedules $p$ across the training lifecycle. Extensive evaluations demonstrate superior stability and convergence over existing baselines. Specifically, our approach achieves a state-of-the-art average accuracy of $54.9\%$ across multiple mathematical benchmarks, yielding a substantial $7.2\%$ relative gain over standard GRPO and secures an exceptional $93.8\%$ success rate on ALFWorld.
GRADE: Benchmarking Discipline-Informed Reasoning in Image Editing
Mar 12, 2026Unified multimodal models target joint understanding, reasoning, and generation, but current image editing benchmarks are largely confined to natural images and shallow commonsense reasoning, offering limited assessment of this capability under structured, domain-specific constraints. In this work, we introduce GRADE, the first benchmark to assess discipline-informed knowledge and reasoning in image editing. GRADE comprises 520 carefully curated samples across 10 academic domains, spanning from natural science to social science. To support rigorous evaluation, we propose a multi-dimensional evaluation protocol that jointly assesses Discipline Reasoning, Visual Consistency, and Logical Readability. Extensive experiments on 20 state-of-the-art open-source and closed-source models reveal substantial limitations in current models under implicit, knowledge-intensive editing settings, leading to large performance gaps. Beyond quantitative scores, we conduct rigorous analyses and ablations to expose model shortcomings and identify the constraints within disciplinary editing. Together, GRADE pinpoints key directions for the future development of unified multimodal models, advancing the research on discipline-informed image editing and reasoning. Our benchmark and evaluation code are publicly released.
InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing
Mar 10, 2026Unified multimodal models (UMMs) that integrate understanding, reasoning, generation, and editing face inherent trade-offs between maintaining strong semantic comprehension and acquiring powerful generation capabilities. In this report, we present InternVL-U, a lightweight 4B-parameter UMM that democratizes these capabilities within a unified framework. Guided by the principles of unified contextual modeling and modality-specific modular design with decoupled visual representations, InternVL-U integrates a state-of-the-art Multimodal Large Language Model (MLLM) with a specialized MMDiT-based visual generation head. To further bridge the gap between aesthetic generation and high-level intelligence, we construct a comprehensive data synthesis pipeline targeting high-semantic-density tasks, such as text rendering and scientific reasoning, under a reasoning-centric paradigm that leverages Chain-of-Thought (CoT) to better align abstract user intent with fine-grained visual generation details. Extensive experiments demonstrate that InternVL-U achieves a superior performance - efficiency balance. Despite using only 4B parameters, it consistently outperforms unified baseline models with over 3x larger scales such as BAGEL (14B) on various generation and editing tasks, while retaining strong multimodal understanding and reasoning capabilities.
GenExam: A Multidisciplinary Text-to-Image Exam
Sep 17, 2025



Exams are a fundamental test of expert-level intelligence and require integrated understanding, reasoning, and generation. Existing exam-style benchmarks mainly focus on understanding and reasoning tasks, and current generation benchmarks emphasize the illustration of world knowledge and visual concepts, neglecting the evaluation of rigorous drawing exams. We introduce GenExam, the first benchmark for multidisciplinary text-to-image exams, featuring 1,000 samples across 10 subjects with exam-style prompts organized under a four-level taxonomy. Each problem is equipped with ground-truth images and fine-grained scoring points to enable a precise evaluation of semantic correctness and visual plausibility. Experiments show that even state-of-the-art models such as GPT-Image-1 and Gemini-2.5-Flash-Image achieve less than 15% strict scores, and most models yield almost 0%, suggesting the great challenge of our benchmark. By framing image generation as an exam, GenExam offers a rigorous assessment of models' ability to integrate knowledge, reasoning, and generation, providing insights on the path to general AGI.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025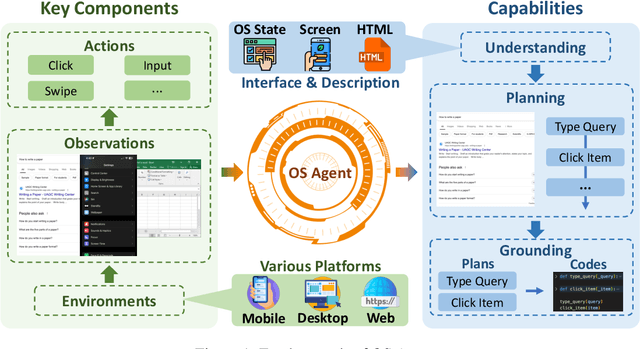
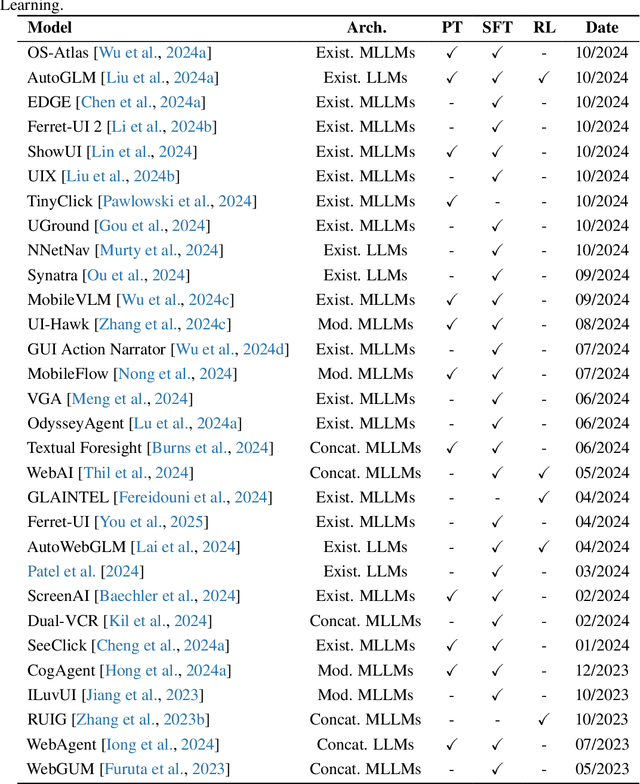
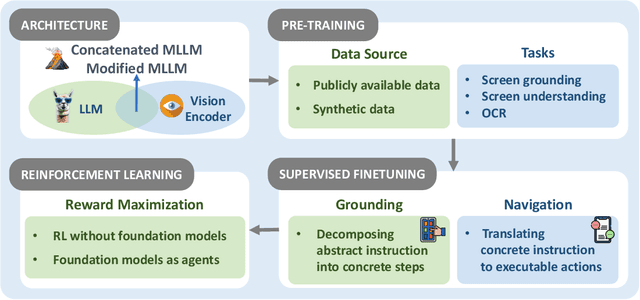
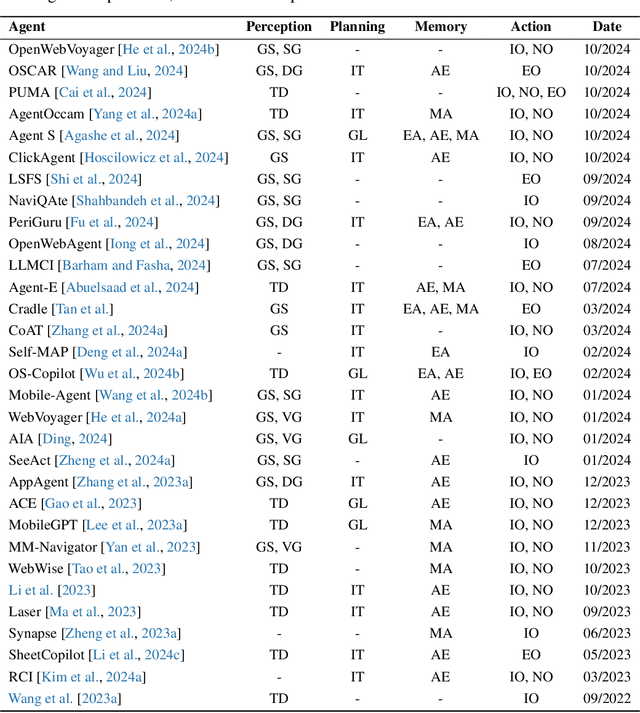
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Apr 18, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has recently demonstrated notable success in enhancing the reasoning capabilities of LLMs, particularly in mathematics and programming tasks. It is widely believed that RLVR enables LLMs to continuously self-improve, thus acquiring novel reasoning abilities that exceed corresponding base models' capacity. In this study, however, we critically re-examines this assumption by measuring the pass@\textit{k} metric with large values of \textit{k} to explore the reasoning capability boundary of the models across a wide range of model families and benchmarks. Surprisingly, the RL does \emph{not}, in fact, elicit fundamentally new reasoning patterns. While RL-trained models outperform their base models at smaller values of $k$ (\eg, $k$=1), base models can achieve a comparable or even higher pass@$k$ score compared to their RL counterparts at large $k$ values. The reasoning paths generated by RL-trained models are already included in the base models' sampling distribution, suggesting that most reasoning abilities manifested in RL-trained models are already obtained by base models. Further analysis shows that RL training boosts the performance by biasing the model's output distribution toward paths that are more likely to yield rewards, therefore sampling correct responses more efficiently. But this also results in a narrower reasoning capability boundary compared to base models. Similar results are observed in visual reasoning tasks trained with RLVR. Moreover, we find that distillation can genuinely introduce new knowledge into the model, different from RLVR. These findings underscore a critical limitation of RLVR in advancing LLM reasoning abilities which requires us to fundamentally rethink the impact of RL training in reasoning LLMs and the need of a better paradigm. Project Page: https://limit-of-RLVR.github.io
Vision-to-Music Generation: A Survey
Mar 27, 2025Vision-to-music Generation, including video-to-music and image-to-music tasks, is a significant branch of multimodal artificial intelligence demonstrating vast application prospects in fields such as film scoring, short video creation, and dance music synthesis. However, compared to the rapid development of modalities like text and images, research in vision-to-music is still in its preliminary stage due to its complex internal structure and the difficulty of modeling dynamic relationships with video. Existing surveys focus on general music generation without comprehensive discussion on vision-to-music. In this paper, we systematically review the research progress in the field of vision-to-music generation. We first analyze the technical characteristics and core challenges for three input types: general videos, human movement videos, and images, as well as two output types of symbolic music and audio music. We then summarize the existing methodologies on vision-to-music generation from the architecture perspective. A detailed review of common datasets and evaluation metrics is provided. Finally, we discuss current challenges and promising directions for future research. We hope our survey can inspire further innovation in vision-to-music generation and the broader field of multimodal generation in academic research and industrial applications. To follow latest works and foster further innovation in this field, we are continuously maintaining a GitHub repository at https://github.com/wzk1015/Awesome-Vision-to-Music-Generation.
TIDE : Temporal-Aware Sparse Autoencoders for Interpretable Diffusion Transformers in Image Generation
Mar 10, 2025Diffusion Transformers (DiTs) are a powerful yet underexplored class of generative models compared to U-Net-based diffusion models. To bridge this gap, we introduce TIDE (Temporal-aware Sparse Autoencoders for Interpretable Diffusion transformErs), a novel framework that enhances temporal reconstruction within DiT activation layers across denoising steps. TIDE employs Sparse Autoencoders (SAEs) with a sparse bottleneck layer to extract interpretable and hierarchical features, revealing that diffusion models inherently learn hierarchical features at multiple levels (e.g., 3D, semantic, class) during generative pre-training. Our approach achieves state-of-the-art reconstruction performance, with a mean squared error (MSE) of 1e-3 and a cosine similarity of 0.97, demonstrating superior accuracy in capturing activation dynamics along the denoising trajectory. Beyond interpretability, we showcase TIDE's potential in downstream applications such as sparse activation-guided image editing and style transfer, enabling improved controllability for generative systems. By providing a comprehensive training and evaluation protocol tailored for DiTs, TIDE contributes to developing more interpretable, transparent, and trustworthy generative models.
Parameter-Inverted Image Pyramid Networks for Visual Perception and Multimodal Understanding
Jan 14, 2025Image pyramids are widely adopted in top-performing methods to obtain multi-scale features for precise visual perception and understanding. However, current image pyramids use the same large-scale model to process multiple resolutions of images, leading to significant computational cost. To address this challenge, we propose a novel network architecture, called Parameter-Inverted Image Pyramid Networks (PIIP). Specifically, PIIP uses pretrained models (ViTs or CNNs) as branches to process multi-scale images, where images of higher resolutions are processed by smaller network branches to balance computational cost and performance. To integrate information from different spatial scales, we further propose a novel cross-branch feature interaction mechanism. To validate PIIP, we apply it to various perception models and a representative multimodal large language model called LLaVA, and conduct extensive experiments on various tasks such as object detection, segmentation, image classification and multimodal understanding. PIIP achieves superior performance compared to single-branch and existing multi-resolution approaches with lower computational cost. When applied to InternViT-6B, a large-scale vision foundation model, PIIP can improve its performance by 1%-2% on detection and segmentation with only 40%-60% of the original computation, finally achieving 60.0 box AP on MS COCO and 59.7 mIoU on ADE20K. For multimodal understanding, our PIIP-LLaVA achieves 73.0% accuracy on TextVQA and 74.5% on MMBench with only 2.8M training data. Our code is released at https://github.com/OpenGVLab/PIIP.