 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining LLM Semantic Reasoning with GNN Structural Modeling for Multi-View Multi-Label Feature Selection
Nov 19, 2025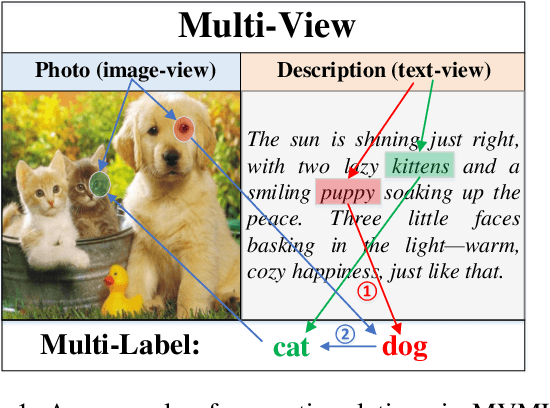



Multi-view multi-label feature selection aims to identify informative features from heterogeneous views, where each sample is associated with multiple interdependent labels. This problem is particularly important in machine learning involving high-dimensional, multimodal data such as social media, bioinformatics or recommendation systems. Existing Multi-View Multi-Label Feature Selection (MVMLFS) methods mainly focus on analyzing statistical information of data, but seldom consider semantic information. In this paper, we aim to use these two types of information jointly and propose a method that combines Large Language Models (LLMs) semantic reasoning with Graph Neural Networks (GNNs) structural modeling for MVMLFS. Specifically, the method consists of three main components. (1) LLM is first used as an evaluation agent to assess the latent semantic relevance among feature, view, and label descriptions. (2) A semantic-aware heterogeneous graph with two levels is designed to represent relations among features, views and labels: one is a semantic graph representing semantic relations, and the other is a statistical graph. (3) A lightweight Graph Attention Network (GAT) is applied to learn node embedding in the heterogeneous graph as feature saliency scores for ranking and selection. Experimental results on multiple benchmark datasets demonstrate the superiority of our method over state-of-the-art baselines, and it is still effective when applied to small-scale datasets, showcasing its robustness, flexibility, and generalization ability.
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Apr 18, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has recently demonstrated notable success in enhancing the reasoning capabilities of LLMs, particularly in mathematics and programming tasks. It is widely believed that RLVR enables LLMs to continuously self-improve, thus acquiring novel reasoning abilities that exceed corresponding base models' capacity. In this study, however, we critically re-examines this assumption by measuring the pass@\textit{k} metric with large values of \textit{k} to explore the reasoning capability boundary of the models across a wide range of model families and benchmarks. Surprisingly, the RL does \emph{not}, in fact, elicit fundamentally new reasoning patterns. While RL-trained models outperform their base models at smaller values of $k$ (\eg, $k$=1), base models can achieve a comparable or even higher pass@$k$ score compared to their RL counterparts at large $k$ values. The reasoning paths generated by RL-trained models are already included in the base models' sampling distribution, suggesting that most reasoning abilities manifested in RL-trained models are already obtained by base models. Further analysis shows that RL training boosts the performance by biasing the model's output distribution toward paths that are more likely to yield rewards, therefore sampling correct responses more efficiently. But this also results in a narrower reasoning capability boundary compared to base models. Similar results are observed in visual reasoning tasks trained with RLVR. Moreover, we find that distillation can genuinely introduce new knowledge into the model, different from RLVR. These findings underscore a critical limitation of RLVR in advancing LLM reasoning abilities which requires us to fundamentally rethink the impact of RL training in reasoning LLMs and the need of a better paradigm. Project Page: https://limit-of-RLVR.github.io
End-to-end Neural Video Coding Using a Compound Spatiotemporal Representation
Aug 05, 2021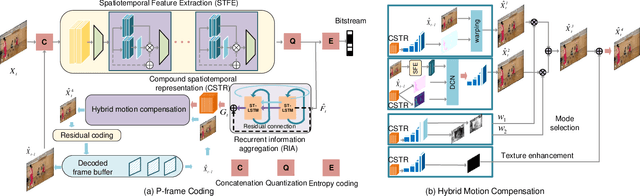
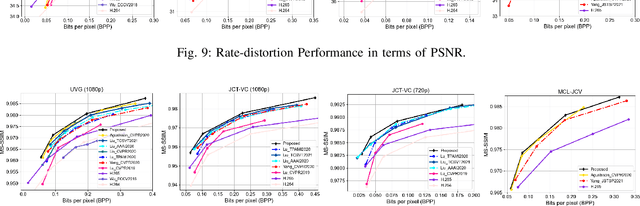
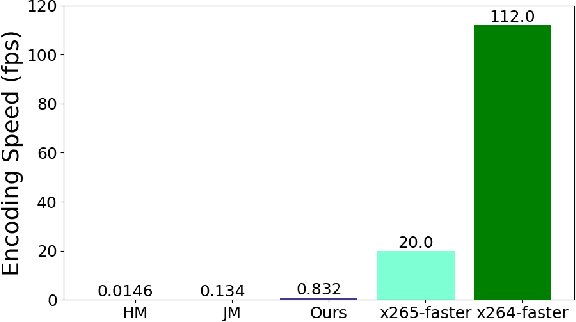
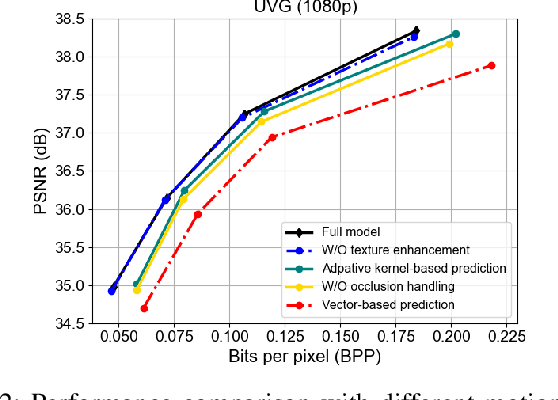
Recent years have witnessed rapid advances in learnt video coding. Most algorithms have solely relied on the vector-based motion representation and resampling (e.g., optical flow based bilinear sampling) for exploiting the inter frame redundancy. In spite of the great success of adaptive kernel-based resampling (e.g., adaptive convolutions and deformable convolutions) in video prediction for uncompressed videos, integrating such approaches with rate-distortion optimization for inter frame coding has been less successful. Recognizing that each resampling solution offers unique advantages in regions with different motion and texture characteristics, we propose a hybrid motion compensation (HMC) method that adaptively combines the predictions generated by these two approaches. Specifically, we generate a compound spatiotemporal representation (CSTR) through a recurrent information aggregation (RIA) module using information from the current and multiple past frames. We further design a one-to-many decoder pipeline to generate multiple predictions from the CSTR, including vector-based resampling, adaptive kernel-based resampling, compensation mode selection maps and texture enhancements, and combines them adaptively to achieve more accurate inter prediction. Experiments show that our proposed inter coding system can provide better motion-compensated prediction and is more robust to occlusions and complex motions. Together with jointly trained intra coder and residual coder, the overall learnt hybrid coder yields the state-of-the-art coding efficiency in low-delay scenario, compared to the traditional H.264/AVC and H.265/HEVC, as well as recently published learning-based methods, in terms of both PSNR and MS-SSIM metrics.
PDWN: Pyramid Deformable Warping Network for Video Interpolation
Apr 04, 2021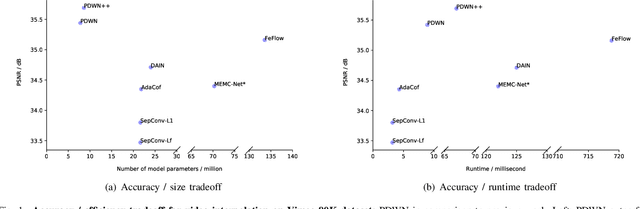
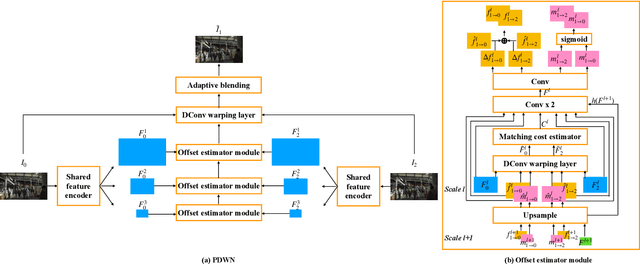


Video interpolation aims to generate a non-existent intermediate frame given the past and future frames. Many state-of-the-art methods achieve promising results by estimating the optical flow between the known frames and then generating the backward flows between the middle frame and the known frames. However, these methods usually suffer from the inaccuracy of estimated optical flows and require additional models or information to compensate for flow estimation errors. Following the recent development in using deformable convolution (DConv) for video interpolation, we propose a light but effective model, called Pyramid Deformable Warping Network (PDWN). PDWN uses a pyramid structure to generate DConv offsets of the unknown middle frame with respect to the known frames through coarse-to-fine successive refinements. Cost volumes between warped features are calculated at every pyramid level to help the offset inference. At the finest scale, the two warped frames are adaptively blended to generate the middle frame. Lastly, a context enhancement network further enhances the contextual detail of the final output. Ablation studies demonstrate the effectiveness of the coarse-to-fine offset refinement, cost volumes, and DConv. Our method achieves better or on-par accuracy compared to state-of-the-art models on multiple datasets while the number of model parameters and the inference time are substantially less than previous models. Moreover, we present an extension of the proposed framework to use four input frames, which can achieve significant improvement over using only two input frames, with only a slight increase in the model size and inference time.