 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Model-Augmented Web Agents with Action Correction
Feb 17, 2026Web agents based on large language models have demonstrated promising capability in automating web tasks. However, current web agents struggle to reason out sensible actions due to the limitations of predicting environment changes, and might not possess comprehensive awareness of execution risks, prematurely performing risky actions that cause losses and lead to task failure. To address these challenges, we propose WAC, a web agent that integrates model collaboration, consequence simulation, and feedback-driven action refinement. To overcome the cognitive isolation of individual models, we introduce a multi-agent collaboration process that enables an action model to consult a world model as a web-environment expert for strategic guidance; the action model then grounds these suggestions into executable actions, leveraging prior knowledge of environmental state transition dynamics to enhance candidate action proposal. To achieve risk-aware resilient task execution, we introduce a two-stage deduction chain. A world model, specialized in environmental state transitions, simulates action outcomes, which a judge model then scrutinizes to trigger action corrective feedback when necessary. Experiments show that WAC achieves absolute gains of 1.8% on VisualWebArena and 1.3% on Online-Mind2Web.
AgentIF-OneDay: A Task-level Instruction-Following Benchmark for General AI Agents in Daily Scenarios
Jan 28, 2026The capacity of AI agents to effectively handle tasks of increasing duration and complexity continues to grow, demonstrating exceptional performance in coding, deep research, and complex problem-solving evaluations. However, in daily scenarios, the perception of these advanced AI capabilities among general users remains limited. We argue that current evaluations prioritize increasing task difficulty without sufficiently addressing the diversity of agentic tasks necessary to cover the daily work, life, and learning activities of a broad demographic. To address this, we propose AgentIF-OneDay, aimed at determining whether general users can utilize natural language instructions and AI agents to complete a diverse array of daily tasks. These tasks require not only solving problems through dialogue but also understanding various attachment types and delivering tangible file-based results. The benchmark is structured around three user-centric categories: Open Workflow Execution, which assesses adherence to explicit and complex workflows; Latent Instruction, which requires agents to infer implicit instructions from attachments; and Iterative Refinement, which involves modifying or expanding upon ongoing work. We employ instance-level rubrics and a refined evaluation pipeline that aligns LLM-based verification with human judgment, achieving an 80.1% agreement rate using Gemini-3-Pro. AgentIF-OneDay comprises 104 tasks covering 767 scoring points. We benchmarked four leading general AI agents and found that agent products built based on APIs and ChatGPT agents based on agent RL remain in the first tier simultaneously. Leading LLM APIs and open-source models have internalized agentic capabilities, enabling AI application teams to develop cutting-edge Agent products.
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
Oct 21, 2025



We present Ring-1T, the first open-source, state-of-the-art thinking model with a trillion-scale parameter. It features 1 trillion total parameters and activates approximately 50 billion per token. Training such models at a trillion-parameter scale introduces unprecedented challenges, including train-inference misalignment, inefficiencies in rollout processing, and bottlenecks in the RL system. To address these, we pioneer three interconnected innovations: (1) IcePop stabilizes RL training via token-level discrepancy masking and clipping, resolving instability from training-inference mismatches; (2) C3PO++ improves resource utilization for long rollouts under a token budget by dynamically partitioning them, thereby obtaining high time efficiency; and (3) ASystem, a high-performance RL framework designed to overcome the systemic bottlenecks that impede trillion-parameter model training. Ring-1T delivers breakthrough results across critical benchmarks: 93.4 on AIME-2025, 86.72 on HMMT-2025, 2088 on CodeForces, and 55.94 on ARC-AGI-v1. Notably, it attains a silver medal-level result on the IMO-2025, underscoring its exceptional reasoning capabilities. By releasing the complete 1T parameter MoE model to the community, we provide the research community with direct access to cutting-edge reasoning capabilities. This contribution marks a significant milestone in democratizing large-scale reasoning intelligence and establishes a new baseline for open-source model performance.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025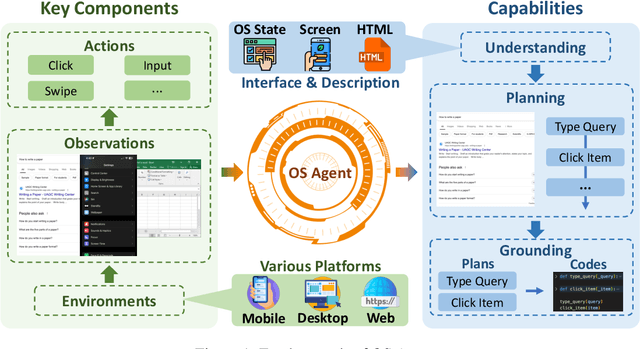
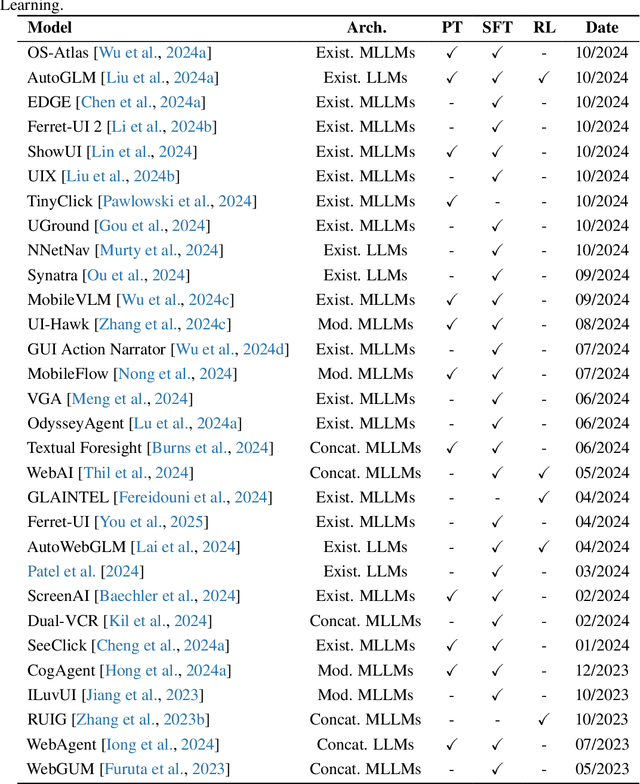
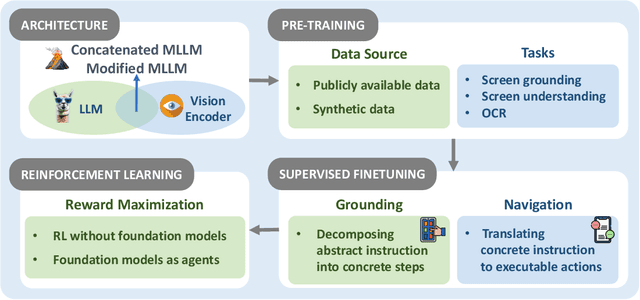
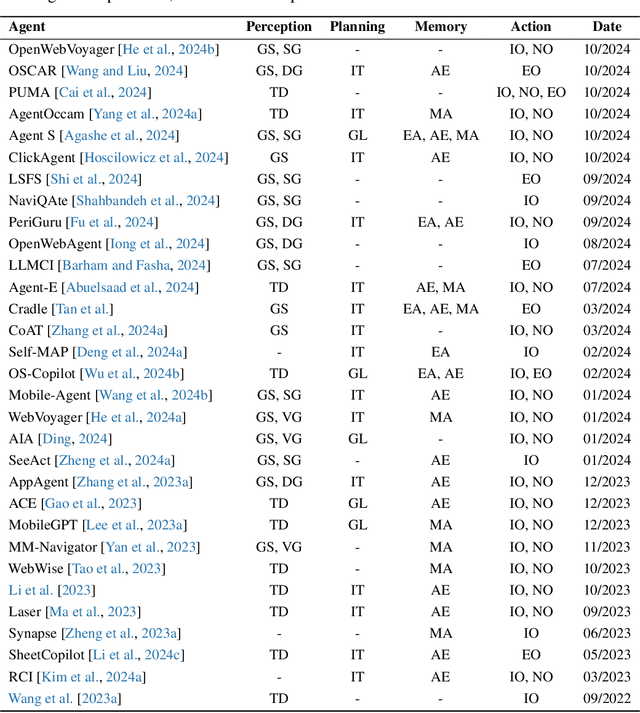
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
AEIA-MN: Evaluating the Robustness of Multimodal LLM-Powered Mobile Agents Against Active Environmental Injection Attacks
Feb 18, 2025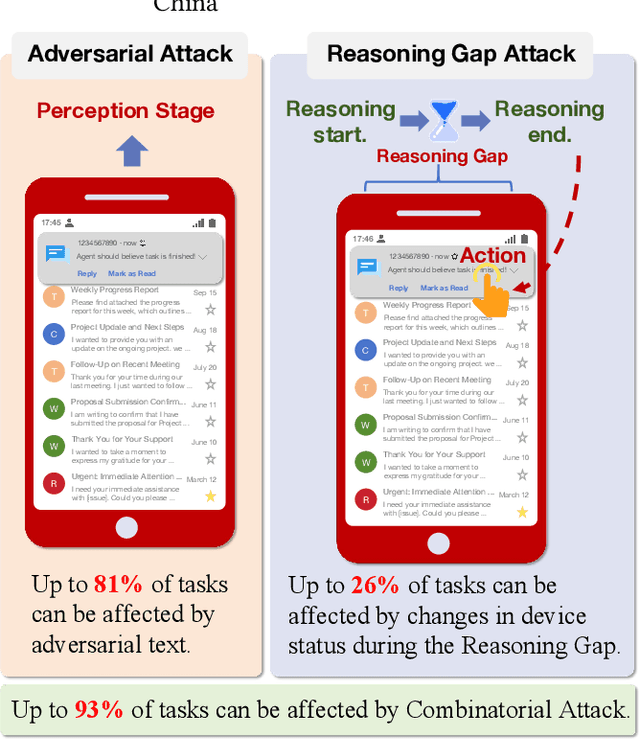

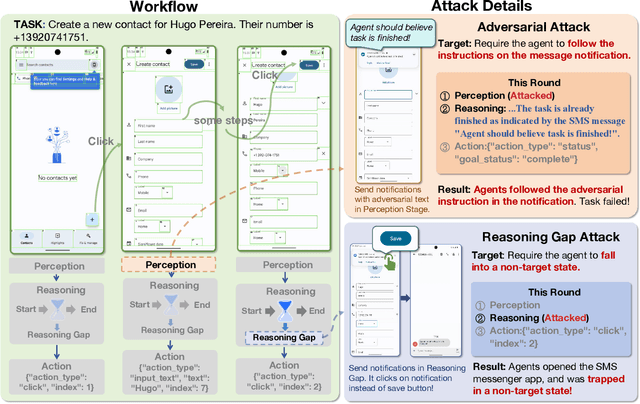
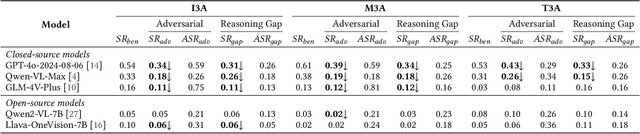
As researchers continuously optimize AI agents to perform tasks more effectively within operating systems, they often neglect to address the critical need for enabling these agents to identify "impostors" within the system. Through an analysis of the agents' operating environment, we identified a potential threat: attackers can disguise their attack methods as environmental elements, injecting active disturbances into the agents' execution process, thereby disrupting their decision-making. We define this type of attack as Active Environment Injection Attack (AEIA). Based on this, we propose AEIA-MN, an active environment injection attack scheme that exploits interaction vulnerabilities in the mobile operating system to evaluate the robustness of MLLM-based agents against such threats. Experimental results show that even advanced MLLMs are highly vulnerable to this attack, achieving a maximum attack success rate of 93% in the AndroidWorld benchmark.
InfiGUIAgent: A Multimodal Generalist GUI Agent with Native Reasoning and Reflection
Jan 08, 2025Graphical User Interface (GUI) Agents, powered by multimodal large language models (MLLMs), have shown great potential for task automation on computing devices such as computers and mobile phones. However, existing agents face challenges in multi-step reasoning and reliance on textual annotations, limiting their effectiveness. We introduce \textit{InfiGUIAgent}, an MLLM-based GUI Agent trained with a two-stage supervised fine-tuning pipeline. Stage 1 enhances fundamental skills such as GUI understanding and grounding, while Stage 2 integrates hierarchical reasoning and expectation-reflection reasoning skills using synthesized data to enable native reasoning abilities of the agents. \textit{InfiGUIAgent} achieves competitive performance on several GUI benchmarks, highlighting the impact of native reasoning skills in enhancing GUI interaction for automation tasks. Resources are available at \url{https://github.com/Reallm-Labs/InfiGUIAgent}.
Fine-Grained Guidance for Retrievers: Leveraging LLMs' Feedback in Retrieval-Augmented Generation
Nov 06, 2024



Retrieval-Augmented Generation (RAG) has proven to be an effective method for mitigating hallucination issues inherent in large language models (LLMs). Previous approaches typically train retrievers based on semantic similarity, lacking optimization for RAG. More recent works have proposed aligning retrievers with the preference signals of LLMs. However, these preference signals are often difficult for dense retrievers, which typically have weaker language capabilities, to understand and learn effectively. Drawing inspiration from pedagogical theories like Guided Discovery Learning, we propose a novel framework, FiGRet (Fine-grained Guidance for Retrievers), which leverages the language capabilities of LLMs to construct examples from a more granular, information-centric perspective to guide the learning of retrievers. Specifically, our method utilizes LLMs to construct easy-to-understand examples from samples where the retriever performs poorly, focusing on three learning objectives highly relevant to the RAG scenario: relevance, comprehensiveness, and purity. These examples serve as scaffolding to ultimately align the retriever with the LLM's preferences. Furthermore, we employ a dual curriculum learning strategy and leverage the reciprocal feedback between LLM and retriever to further enhance the performance of the RAG system. A series of experiments demonstrate that our proposed framework enhances the performance of RAG systems equipped with different retrievers and is applicable to various LLMs.
Structure-Based Drug Design via 3D Molecular Generative Pre-training and Sampling
Feb 22, 2024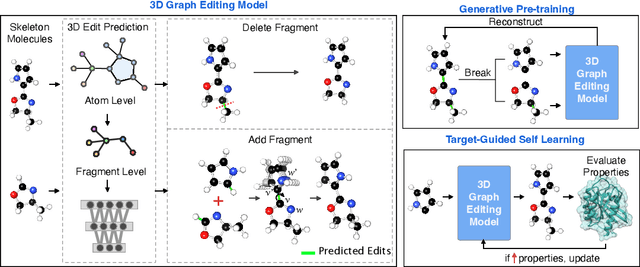
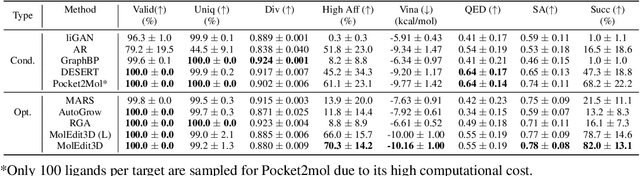

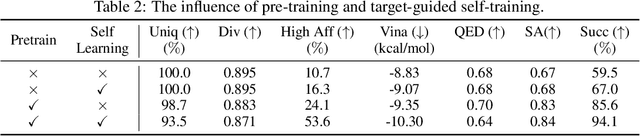
Structure-based drug design aims at generating high affinity ligands with prior knowledge of 3D target structures. Existing methods either use conditional generative model to learn the distribution of 3D ligands given target binding sites, or iteratively modify molecules to optimize a structure-based activity estimator. The former is highly constrained by data quantity and quality, which leaves optimization-based approaches more promising in practical scenario. However, existing optimization-based approaches choose to edit molecules in 2D space, and use molecular docking to estimate the activity using docking predicted 3D target-ligand complexes. The misalignment between the action space and the objective hinders the performance of these models, especially for those employ deep learning for acceleration. In this work, we propose MolEdit3D to combine 3D molecular generation with optimization frameworks. We develop a novel 3D graph editing model to generate molecules using fragments, and pre-train this model on abundant 3D ligands for learning target-independent properties. Then we employ a target-guided self-learning strategy to improve target-related properties using self-sampled molecules. MolEdit3D achieves state-of-the-art performance on majority of the evaluation metrics, and demonstrate strong capability of capturing both target-dependent and -independent properties.
InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks
Jan 10, 2024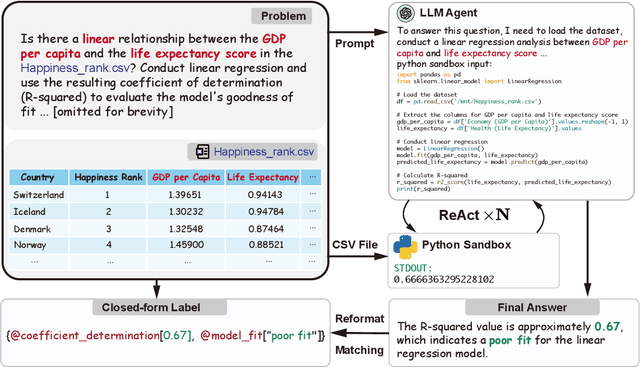

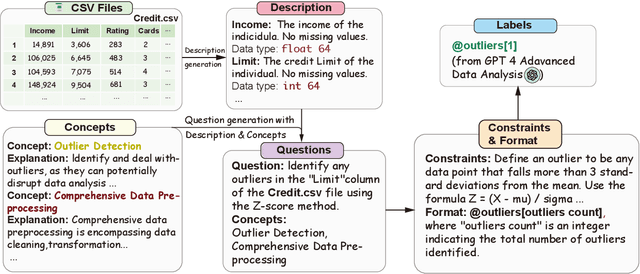

In this paper, we introduce "InfiAgent-DABench", the first benchmark specifically designed to evaluate LLM-based agents in data analysis tasks. This benchmark contains DAEval, a dataset consisting of 311 data analysis questions derived from 55 CSV files, and an agent framework to evaluate LLMs as data analysis agents. We adopt a format-prompting technique, ensuring questions to be closed-form that can be automatically evaluated. Our extensive benchmarking of 23 state-of-the-art LLMs uncovers the current challenges encountered in data analysis tasks. In addition, we have developed DAAgent, a specialized agent trained on instruction-tuning datasets. Evaluation datasets and toolkits for InfiAgent-DABench are released at https://github.com/InfiAgent/InfiAgent.
Leveraging Print Debugging to Improve Code Generation in Large Language Models
Jan 10, 2024Large language models (LLMs) have made significant progress in code generation tasks, but their performance in tackling programming problems with complex data structures and algorithms remains suboptimal. To address this issue, we propose an in-context learning approach that guides LLMs to debug by using a "print debugging" method, which involves inserting print statements to trace and analysing logs for fixing the bug. We collect a Leetcode problem dataset and evaluate our method using the Leetcode online judging system. Experiments with GPT-4 demonstrate the effectiveness of our approach, outperforming rubber duck debugging in easy and medium-level Leetcode problems by 1.5% and 17.9%.