 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixing Expert Knowledge: Bring Human Thoughts Back To the Game of Go
Jan 23, 2026Large language models (LLMs) have demonstrated exceptional performance in reasoning tasks such as mathematics and coding, matching or surpassing human capabilities. However, these impressive reasoning abilities face significant challenges in specialized domains. Taking Go as an example, although AlphaGo has established the high performance ceiling of AI systems in Go, mainstream LLMs still struggle to reach even beginner-level proficiency, let alone perform natural language reasoning. This performance gap between general-purpose LLMs and domain experts is significantly limiting the application of LLMs on a wider range of domain-specific tasks. In this work, we aim to bridge the divide between LLMs' general reasoning capabilities and expert knowledge in domain-specific tasks. We perform mixed fine-tuning with structured Go expertise and general long Chain-of-Thought (CoT) reasoning data as a cold start, followed by reinforcement learning to integrate expert knowledge in Go with general reasoning capabilities. Through this methodology, we present \textbf{LoGos}, a powerful LLM that not only maintains outstanding general reasoning abilities, but also conducts Go gameplay in natural language, demonstrating effective strategic reasoning and accurate next-move prediction. LoGos achieves performance comparable to human professional players, substantially surpassing all existing LLMs. Through this work, we aim to contribute insights on applying general LLM reasoning capabilities to specialized domains. We will release the first large-scale Go dataset for LLM training, the first LLM Go evaluation benchmark, and the first general LLM that reaches human professional-level performance in Go at: https://github.com/Entarochuan/LoGos.
InternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling
Aug 12, 2025



Large language models (LLMs) have revolutionized artificial intelligence by enabling complex reasoning capabilities. While recent advancements in reinforcement learning (RL) have primarily focused on domain-specific reasoning tasks (e.g., mathematics or code generation), real-world reasoning scenarios often require models to handle diverse and complex environments that narrow-domain benchmarks cannot fully capture. To address this gap, we present InternBootcamp, an open-source framework comprising 1000+ domain-diverse task environments specifically designed for LLM reasoning research. Our codebase offers two key functionalities: (1) automated generation of unlimited training/testing cases with configurable difficulty levels, and (2) integrated verification modules for objective response evaluation. These features make InternBootcamp fundamental infrastructure for RL-based model optimization, synthetic data generation, and model evaluation. Although manually developing such a framework with enormous task coverage is extremely cumbersome, we accelerate the development procedure through an automated agent workflow supplemented by manual validation protocols, which enables the task scope to expand rapidly. % With these bootcamps, we further establish Bootcamp-EVAL, an automatically generated benchmark for comprehensive performance assessment. Evaluation reveals that frontier models still underperform in many reasoning tasks, while training with InternBootcamp provides an effective way to significantly improve performance, leading to our 32B model that achieves state-of-the-art results on Bootcamp-EVAL and excels on other established benchmarks. In particular, we validate that consistent performance gains come from including more training tasks, namely \textbf{task scaling}, over two orders of magnitude, offering a promising route towards capable reasoning generalist.
OS Agents: A Survey on MLLM-based Agents for General Computing Devices Use
Aug 06, 2025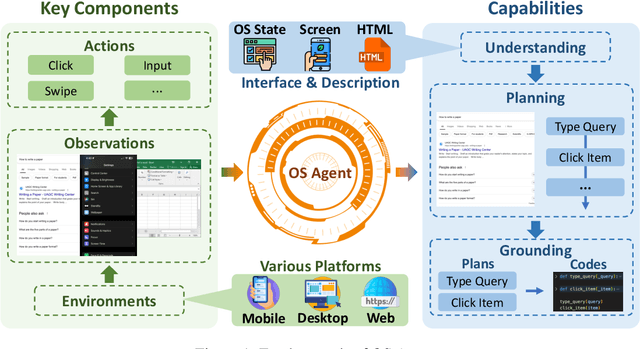
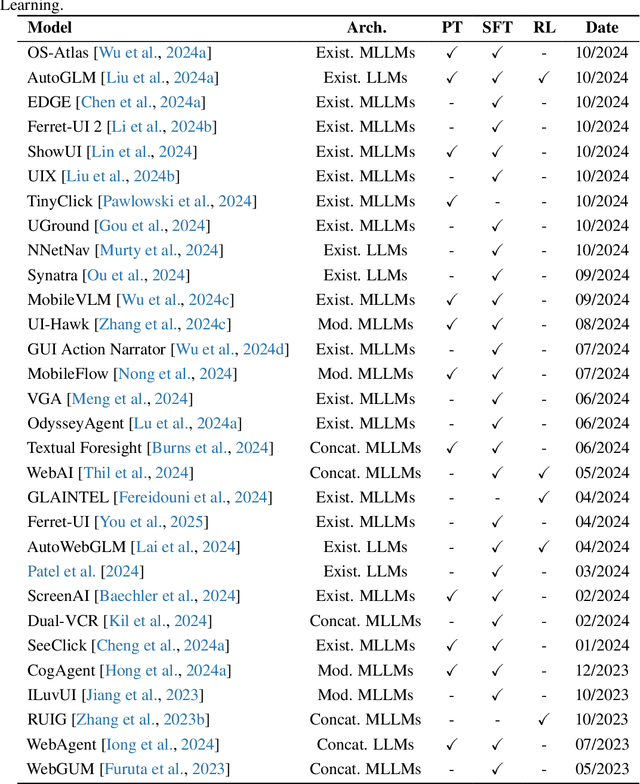
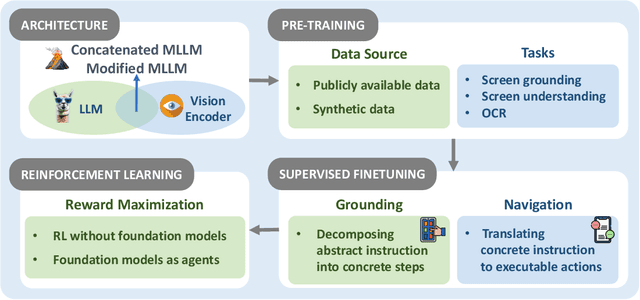
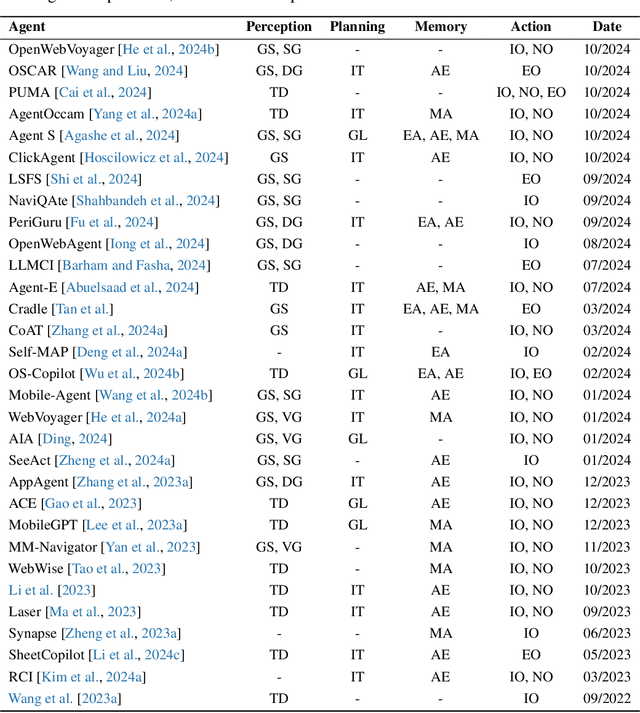
The dream to create AI assistants as capable and versatile as the fictional J.A.R.V.I.S from Iron Man has long captivated imaginations. With the evolution of (multi-modal) large language models ((M)LLMs), this dream is closer to reality, as (M)LLM-based Agents using computing devices (e.g., computers and mobile phones) by operating within the environments and interfaces (e.g., Graphical User Interface (GUI)) provided by operating systems (OS) to automate tasks have significantly advanced. This paper presents a comprehensive survey of these advanced agents, designated as OS Agents. We begin by elucidating the fundamentals of OS Agents, exploring their key components including the environment, observation space, and action space, and outlining essential capabilities such as understanding, planning, and grounding. We then examine methodologies for constructing OS Agents, focusing on domain-specific foundation models and agent frameworks. A detailed review of evaluation protocols and benchmarks highlights how OS Agents are assessed across diverse tasks. Finally, we discuss current challenges and identify promising directions for future research, including safety and privacy, personalization and self-evolution. This survey aims to consolidate the state of OS Agents research, providing insights to guide both academic inquiry and industrial development. An open-source GitHub repository is maintained as a dynamic resource to foster further innovation in this field. We present a 9-page version of our work, accepted by ACL 2025, to provide a concise overview to the domain.
DetectiveQA: Evaluating Long-Context Reasoning on Detective Novels
Sep 04, 2024



With the rapid advancement of Large Language Models (LLMs), long-context information understanding and processing have become a hot topic in academia and industry. However, benchmarks for evaluating the ability of LLMs to handle long-context information do not seem to have kept pace with the development of LLMs. Despite the emergence of various long-context evaluation benchmarks, the types of capability assessed are still limited, without new capability dimensions. In this paper, we introduce DetectiveQA, a narrative reasoning benchmark featured with an average context length of over 100K tokens. DetectiveQA focuses on evaluating the long-context reasoning ability of LLMs, which not only requires a full understanding of context but also requires extracting important evidences from the context and reasoning according to extracted evidences to answer the given questions. This is a new dimension of capability evaluation, which is more in line with the current intelligence level of LLMs. We use detective novels as data sources, which naturally have various reasoning elements. Finally, we manually annotated 600 questions in Chinese and then also provided an English edition of the context information and questions. We evaluate many long-context LLMs on DetectiveQA, including commercial and open-sourced models, and the results indicate that existing long-context LLMs still require significant advancements to effectively process true long-context dependency questions.
Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance
Mar 25, 2024



Pretraining data of large language models composes multiple domains (e.g., web texts, academic papers, codes), whose mixture proportions crucially impact the competence of outcome models. While existing endeavors rely on heuristics or qualitative strategies to tune the proportions, we discover the quantitative predictability of model performance regarding the mixture proportions in function forms, which we refer to as the data mixing laws. Fitting such functions on sample mixtures unveils model performance on unseen mixtures before actual runs, thus guiding the selection of an ideal data mixture. Furthermore, we propose nested use of the scaling laws of training steps, model sizes, and our data mixing law to enable predicting the performance of large models trained on massive data under various mixtures with only small-scale training. Moreover, experimental results verify that our method effectively optimizes the training mixture of a 1B model trained for 100B tokens in RedPajama, reaching a performance comparable to the one trained for 48% more steps on the default mixture. Extending the application of data mixing laws to continual training accurately predicts the critical mixture proportion that avoids catastrophic forgetting and outlooks the potential for dynamic data schedules
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
Feb 26, 2024



We introduce AnyGPT, an any-to-any multimodal language model that utilizes discrete representations for the unified processing of various modalities, including speech, text, images, and music. AnyGPT can be trained stably without any alterations to the current large language model (LLM) architecture or training paradigms. Instead, it relies exclusively on data-level preprocessing, facilitating the seamless integration of new modalities into LLMs, akin to the incorporation of new languages. We build a multimodal text-centric dataset for multimodal alignment pre-training. Utilizing generative models, we synthesize the first large-scale any-to-any multimodal instruction dataset. It consists of 108k samples of multi-turn conversations that intricately interweave various modalities, thus equipping the model to handle arbitrary combinations of multimodal inputs and outputs. Experimental results demonstrate that AnyGPT is capable of facilitating any-to-any multimodal conversation while achieving performance comparable to specialized models across all modalities, proving that discrete representations can effectively and conveniently unify multiple modalities within a language model. Demos are shown in https://junzhan2000.github.io/AnyGPT.github.io/
LLM can Achieve Self-Regulation via Hyperparameter Aware Generation
Feb 17, 2024In the realm of Large Language Models (LLMs), users commonly employ diverse decoding strategies and adjust hyperparameters to control the generated text. However, a critical question emerges: Are LLMs conscious of the existence of these decoding strategies and capable of regulating themselves? The current decoding generation process often relies on empirical and heuristic manual adjustments to hyperparameters based on types of tasks and demands. However, this process is typically cumbersome, and the decoding hyperparameters may not always be optimal for each sample. To address the aforementioned challenges, we propose a novel text generation paradigm termed Hyperparameter Aware Generation (HAG). By leveraging hyperparameter-aware instruction tuning, the LLM autonomously determines the optimal decoding strategy and configs based on the input samples, enabling self-regulation. Our approach eliminates the need for extensive manual tuning, offering a more autonomous, self-regulate model behavior. Experimental results spanning six datasets across reasoning, creativity, translation, and mathematics tasks demonstrate that hyperparameter-aware instruction tuning empowers the LLMs to self-regulate the decoding strategy and hyperparameter. HAG extends the current paradigm in the text generation process, highlighting the feasibility of endowing the LLMs with self-regulate decoding strategies.
Diffusion Language Models Can Perform Many Tasks with Scaling and Instruction-Finetuning
Aug 25, 2023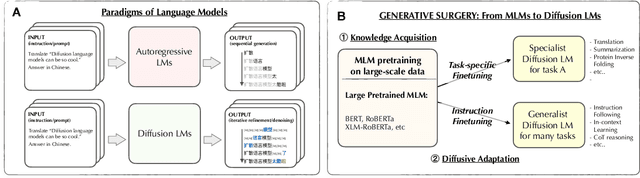
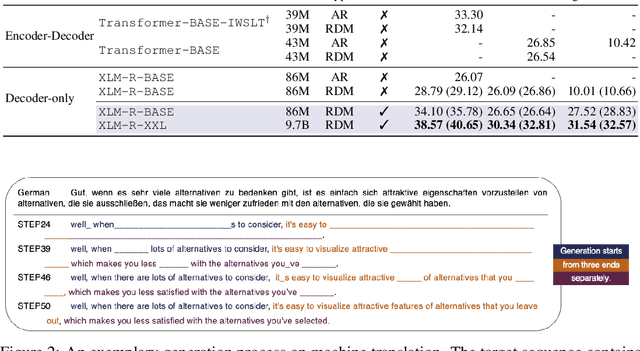

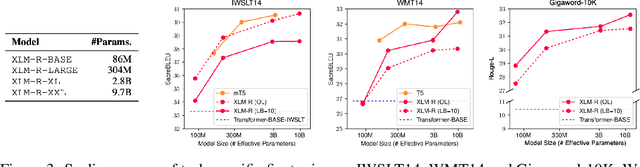
The recent surge of generative AI has been fueled by the generative power of diffusion probabilistic models and the scalable capabilities of large language models. Despite their potential, it remains elusive whether diffusion language models can solve general language tasks comparable to their autoregressive counterparts. This paper demonstrates that scaling diffusion models w.r.t. data, sizes, and tasks can effectively make them strong language learners. We build competent diffusion language models at scale by first acquiring knowledge from massive data via masked language modeling pretraining thanks to their intrinsic connections. We then reprogram pretrained masked language models into diffusion language models via diffusive adaptation, wherein task-specific finetuning and instruction finetuning are explored to unlock their versatility in solving general language tasks. Experiments show that scaling diffusion language models consistently improves performance across downstream language tasks. We further discover that instruction finetuning can elicit zero-shot and few-shot in-context learning abilities that help tackle many unseen tasks by following natural language instructions, and show promise in advanced and challenging abilities such as reasoning.
DINOISER: Diffused Conditional Sequence Learning by Manipulating Noises
Feb 20, 2023



While diffusion models have achieved great success in generating continuous signals such as images and audio, it remains elusive for diffusion models in learning discrete sequence data like natural languages. Although recent advances circumvent this challenge of discreteness by embedding discrete tokens as continuous surrogates, they still fall short of satisfactory generation quality. To understand this, we first dive deep into the denoised training protocol of diffusion-based sequence generative models and determine their three severe problems, i.e., 1) failing to learn, 2) lack of scalability, and 3) neglecting source conditions. We argue that these problems can be boiled down to the pitfall of the not completely eliminated discreteness in the embedding space, and the scale of noises is decisive herein. In this paper, we introduce DINOISER to facilitate diffusion models for sequence generation by manipulating noises. We propose to adaptively determine the range of sampled noise scales for counter-discreteness training; and encourage the proposed diffused sequence learner to leverage source conditions with amplified noise scales during inference. Experiments show that DINOISER enables consistent improvement over the baselines of previous diffusion-based sequence generative models on several conditional sequence modeling benchmarks thanks to both effective training and inference strategies. Analyses further verify that DINOISER can make better use of source conditions to govern its generative process.
Energy-based Unknown Intent Detection with Data Manipulation
Jul 27, 2021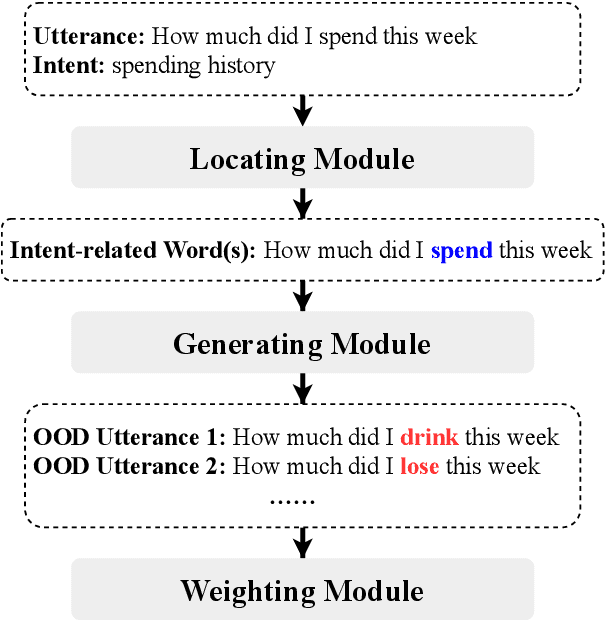
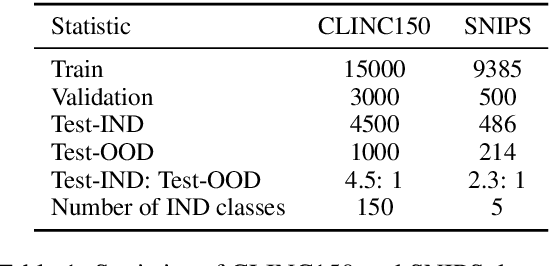
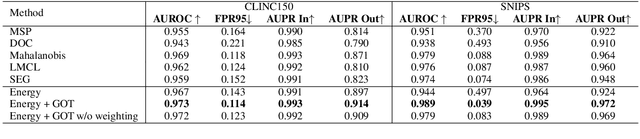
Unknown intent detection aims to identify the out-of-distribution (OOD) utterance whose intent has never appeared in the training set. In this paper, we propose using energy scores for this task as the energy score is theoretically aligned with the density of the input and can be derived from any classifier. However, high-quality OOD utterances are required during the training stage in order to shape the energy gap between OOD and in-distribution (IND), and these utterances are difficult to collect in practice. To tackle this problem, we propose a data manipulation framework to Generate high-quality OOD utterances with importance weighTs (GOT). Experimental results show that the energy-based detector fine-tuned by GOT can achieve state-of-the-art results on two benchmark datasets.