 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
Dec 24, 2024



General-purposed embodied agents are designed to understand the users' natural instructions or intentions and act precisely to complete universal tasks. Recently, methods based on foundation models especially Vision-Language-Action models (VLAs) have shown a substantial potential to solve language-conditioned manipulation (LCM) tasks well. However, existing benchmarks do not adequately meet the needs of VLAs and relative algorithms. To better define such general-purpose tasks in the context of LLMs and advance the research in VLAs, we present VLABench, an open-source benchmark for evaluating universal LCM task learning. VLABench provides 100 carefully designed categories of tasks, with strong randomization in each category of task and a total of 2000+ objects. VLABench stands out from previous benchmarks in four key aspects: 1) tasks requiring world knowledge and common sense transfer, 2) natural language instructions with implicit human intentions rather than templates, 3) long-horizon tasks demanding multi-step reasoning, and 4) evaluation of both action policies and language model capabilities. The benchmark assesses multiple competencies including understanding of mesh\&texture, spatial relationship, semantic instruction, physical laws, knowledge transfer and reasoning, etc. To support the downstream finetuning, we provide high-quality training data collected via an automated framework incorporating heuristic skills and prior information. The experimental results indicate that both the current state-of-the-art pretrained VLAs and the workflow based on VLMs face challenges in our tasks.
Data Mixing Laws: Optimizing Data Mixtures by Predicting Language Modeling Performance
Mar 25, 2024



Pretraining data of large language models composes multiple domains (e.g., web texts, academic papers, codes), whose mixture proportions crucially impact the competence of outcome models. While existing endeavors rely on heuristics or qualitative strategies to tune the proportions, we discover the quantitative predictability of model performance regarding the mixture proportions in function forms, which we refer to as the data mixing laws. Fitting such functions on sample mixtures unveils model performance on unseen mixtures before actual runs, thus guiding the selection of an ideal data mixture. Furthermore, we propose nested use of the scaling laws of training steps, model sizes, and our data mixing law to enable predicting the performance of large models trained on massive data under various mixtures with only small-scale training. Moreover, experimental results verify that our method effectively optimizes the training mixture of a 1B model trained for 100B tokens in RedPajama, reaching a performance comparable to the one trained for 48% more steps on the default mixture. Extending the application of data mixing laws to continual training accurately predicts the critical mixture proportion that avoids catastrophic forgetting and outlooks the potential for dynamic data schedules
An Open-World Lottery Ticket for Out-of-Domain Intent Classification
Oct 13, 2022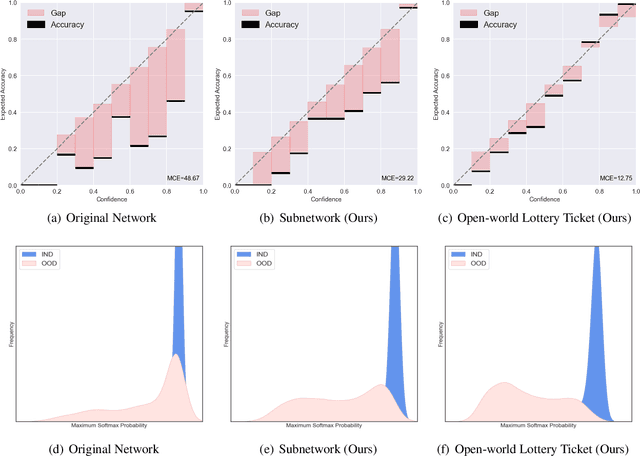
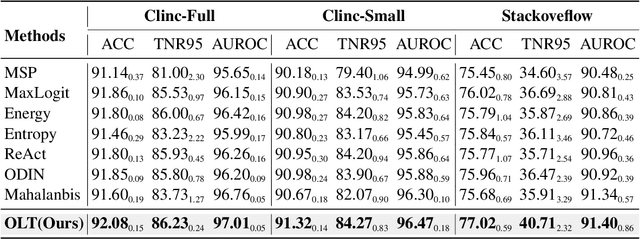

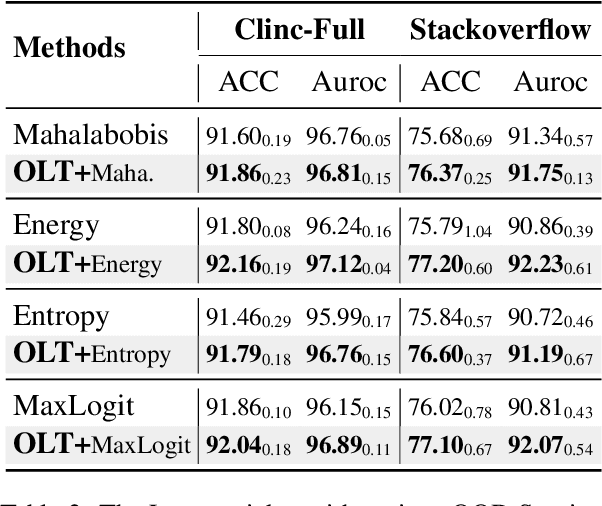
Most existing methods of Out-of-Domain (OOD) intent classification, which rely on extensive auxiliary OOD corpora or specific training paradigms, are underdeveloped in the underlying principle that the models should have differentiated confidence in In- and Out-of-domain intent. In this work, we demonstrate that calibrated subnetworks can be uncovered by pruning the (poor-calibrated) overparameterized model. Calibrated confidence provided by the subnetwork can better distinguish In- and Out-of-domain. Furthermore, we theoretically bring new insights into why temperature scaling can differentiate In- and Out-of-Domain intent and empirically extend the Lottery Ticket Hypothesis to the open-world setting. Extensive experiments on three real-world datasets demonstrate our approach can establish consistent improvements compared with a suite of competitive baselines.
Mining Implicit Entity Preference from User-Item Interaction Data for Knowledge Graph Completion via Adversarial Learning
Apr 26, 2020



The task of Knowledge Graph Completion (KGC) aims to automatically infer the missing fact information in Knowledge Graph (KG). In this paper, we take a new perspective that aims to leverage rich user-item interaction data (user interaction data for short) for improving the KGC task. Our work is inspired by the observation that many KG entities correspond to online items in application systems. However, the two kinds of data sources have very different intrinsic characteristics, and it is likely to hurt the original performance using simple fusion strategy. To address this challenge, we propose a novel adversarial learning approach by leveraging user interaction data for the KGC task. Our generator is isolated from user interaction data, and serves to improve the performance of the discriminator. The discriminator takes the learned useful information from user interaction data as input, and gradually enhances the evaluation capacity in order to identify the fake samples generated by the generator. To discover implicit entity preference of users, we design an elaborate collaborative learning algorithms based on graph neural networks, which will be jointly optimized with the discriminator. Such an approach is effective to alleviate the issues about data heterogeneity and semantic complexity for the KGC task. Extensive experiments on three real-world datasets have demonstrated the effectiveness of our approach on the KGC task.