 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Control to Foresight: Simulation as a New Paradigm for Human-Agent Collaboration
Mar 12, 2026Large Language Models (LLMs) are increasingly used to power autonomous agents for complex, multi-step tasks. However, human-agent interaction remains pointwise and reactive: users approve or correct individual actions to mitigate immediate risks, without visibility into subsequent consequences. This forces users to mentally simulate long-term effects, a cognitively demanding and often inaccurate process. Users have control over individual steps but lack the foresight to make informed decisions. We argue that effective collaboration requires foresight, not just control. We propose simulation-in-the-loop, an interaction paradigm that enables users and agents to explore simulated future trajectories before committing to decisions. Simulation transforms intervention from reactive guesswork into informed exploration, while helping users discover latent constraints and preferences along the way. This perspective paper characterizes the limitations of current paradigms, introduces a conceptual framework for simulation-based collaboration, and illustrates its potential through concrete human-agent collaboration scenarios.
From SERPs to Sound: How Search Engine Result Pages and AI-generated Podcasts Interact to Influence User Attitudes on Controversial Topics
Jan 16, 2026Compared to search engine result pages (SERPs), AI-generated podcasts represent a relatively new and relatively more passive modality of information consumption, delivering narratives in a naturally engaging format. As these two media increasingly converge in everyday information-seeking behavior, it is essential to explore how their interaction influences user attitudes, particularly in contexts involving controversial, value-laden, and often debated topics. Addressing this need, we aim to understand how information mediums of present-day SERPs and AI-generated podcasts interact to shape the opinions of users. To this end, through a controlled user study (N=483), we investigated user attitudinal effects of consuming information via SERPs and AI-generated podcasts, focusing on how the sequence and modality of exposure shape user opinions. A majority of users in our study corresponded to attitude change outcomes, and we found an effect of sequence on attitude change. Our results further revealed a role of viewpoint bias and the degree of topic controversiality in shaping attitude change, although we found no effect of individual moderators.
Plan-Then-Execute: An Empirical Study of User Trust and Team Performance When Using LLM Agents As A Daily Assistant
Feb 03, 2025



Since the explosion in popularity of ChatGPT, large language models (LLMs) have continued to impact our everyday lives. Equipped with external tools that are designed for a specific purpose (e.g., for flight booking or an alarm clock), LLM agents exercise an increasing capability to assist humans in their daily work. Although LLM agents have shown a promising blueprint as daily assistants, there is a limited understanding of how they can provide daily assistance based on planning and sequential decision making capabilities. We draw inspiration from recent work that has highlighted the value of 'LLM-modulo' setups in conjunction with humans-in-the-loop for planning tasks. We conducted an empirical study (N = 248) of LLM agents as daily assistants in six commonly occurring tasks with different levels of risk typically associated with them (e.g., flight ticket booking and credit card payments). To ensure user agency and control over the LLM agent, we adopted LLM agents in a plan-then-execute manner, wherein the agents conducted step-wise planning and step-by-step execution in a simulation environment. We analyzed how user involvement at each stage affects their trust and collaborative team performance. Our findings demonstrate that LLM agents can be a double-edged sword -- (1) they can work well when a high-quality plan and necessary user involvement in execution are available, and (2) users can easily mistrust the LLM agents with plans that seem plausible. We synthesized key insights for using LLM agents as daily assistants to calibrate user trust and achieve better overall task outcomes. Our work has important implications for the future design of daily assistants and human-AI collaboration with LLM agents.
Is Conversational XAI All You Need? Human-AI Decision Making With a Conversational XAI Assistant
Jan 29, 2025



Explainable artificial intelligence (XAI) methods are being proposed to help interpret and understand how AI systems reach specific predictions. Inspired by prior work on conversational user interfaces, we argue that augmenting existing XAI methods with conversational user interfaces can increase user engagement and boost user understanding of the AI system. In this paper, we explored the impact of a conversational XAI interface on users' understanding of the AI system, their trust, and reliance on the AI system. In comparison to an XAI dashboard, we found that the conversational XAI interface can bring about a better understanding of the AI system among users and higher user trust. However, users of both the XAI dashboard and conversational XAI interfaces showed clear overreliance on the AI system. Enhanced conversations powered by large language model (LLM) agents amplified over-reliance. Based on our findings, we reason that the potential cause of such overreliance is the illusion of explanatory depth that is concomitant with both XAI interfaces. Our findings have important implications for designing effective conversational XAI interfaces to facilitate appropriate reliance and improve human-AI collaboration. Code can be found at https://github.com/delftcrowd/IUI2025_ConvXAI
Fine-Grained Appropriate Reliance: Human-AI Collaboration with a Multi-Step Transparent Decision Workflow for Complex Task Decomposition
Jan 19, 2025In recent years, the rapid development of AI systems has brought about the benefits of intelligent services but also concerns about security and reliability. By fostering appropriate user reliance on an AI system, both complementary team performance and reduced human workload can be achieved. Previous empirical studies have extensively analyzed the impact of factors ranging from task, system, and human behavior on user trust and appropriate reliance in the context of one-step decision making. However, user reliance on AI systems in tasks with complex semantics that require multi-step workflows remains under-explored. Inspired by recent work on task decomposition with large language models, we propose to investigate the impact of a novel Multi-Step Transparent (MST) decision workflow on user reliance behaviors. We conducted an empirical study (N = 233) of AI-assisted decision making in composite fact-checking tasks (i.e., fact-checking tasks that entail multiple sub-fact verification steps). Our findings demonstrate that human-AI collaboration with an MST decision workflow can outperform one-step collaboration in specific contexts (e.g., when advice from an AI system is misleading). Further analysis of the appropriate reliance at fine-grained levels indicates that an MST decision workflow can be effective when users demonstrate a relatively high consideration of the intermediate steps. Our work highlights that there is no one-size-fits-all decision workflow that can help obtain optimal human-AI collaboration. Our insights help deepen the understanding of the role of decision workflows in facilitating appropriate reliance. We synthesize important implications for designing effective means to facilitate appropriate reliance on AI systems in composite tasks, positioning opportunities for the human-centered AI and broader HCI communities.
To Err Is AI! Debugging as an Intervention to Facilitate Appropriate Reliance on AI Systems
Sep 22, 2024



Powerful predictive AI systems have demonstrated great potential in augmenting human decision making. Recent empirical work has argued that the vision for optimal human-AI collaboration requires 'appropriate reliance' of humans on AI systems. However, accurately estimating the trustworthiness of AI advice at the instance level is quite challenging, especially in the absence of performance feedback pertaining to the AI system. In practice, the performance disparity of machine learning models on out-of-distribution data makes the dataset-specific performance feedback unreliable in human-AI collaboration. Inspired by existing literature on critical thinking and a critical mindset, we propose the use of debugging an AI system as an intervention to foster appropriate reliance. In this paper, we explore whether a critical evaluation of AI performance within a debugging setting can better calibrate users' assessment of an AI system and lead to more appropriate reliance. Through a quantitative empirical study (N = 234), we found that our proposed debugging intervention does not work as expected in facilitating appropriate reliance. Instead, we observe a decrease in reliance on the AI system after the intervention -- potentially resulting from an early exposure to the AI system's weakness. We explore the dynamics of user confidence and user estimation of AI trustworthiness across groups with different performance levels to help explain how inappropriate reliance patterns occur. Our findings have important implications for designing effective interventions to facilitate appropriate reliance and better human-AI collaboration.
Power-up! What Can Generative Models Do for Human Computation Workflows?
Jul 05, 2023We are amidst an explosion of artificial intelligence research, particularly around large language models (LLMs). These models have a range of applications across domains like medicine, finance, commonsense knowledge graphs, and crowdsourcing. Investigation into LLMs as part of crowdsourcing workflows remains an under-explored space. The crowdsourcing research community has produced a body of work investigating workflows and methods for managing complex tasks using hybrid human-AI methods. Within crowdsourcing, the role of LLMs can be envisioned as akin to a cog in a larger wheel of workflows. From an empirical standpoint, little is currently understood about how LLMs can improve the effectiveness of crowdsourcing workflows and how such workflows can be evaluated. In this work, we present a vision for exploring this gap from the perspectives of various stakeholders involved in the crowdsourcing paradigm -- the task requesters, crowd workers, platforms, and end-users. We identify junctures in typical crowdsourcing workflows at which the introduction of LLMs can play a beneficial role and propose means to augment existing design patterns for crowd work.
Knowing About Knowing: An Illusion of Human Competence Can Hinder Appropriate Reliance on AI Systems
Jan 25, 2023The dazzling promises of AI systems to augment humans in various tasks hinge on whether humans can appropriately rely on them. Recent research has shown that appropriate reliance is the key to achieving complementary team performance in AI-assisted decision making. This paper addresses an under-explored problem of whether the Dunning-Kruger Effect (DKE) among people can hinder their appropriate reliance on AI systems. DKE is a metacognitive bias due to which less-competent individuals overestimate their own skill and performance. Through an empirical study (N = 249), we explored the impact of DKE on human reliance on an AI system, and whether such effects can be mitigated using a tutorial intervention that reveals the fallibility of AI advice, and exploiting logic units-based explanations to improve user understanding of AI advice. We found that participants who overestimate their performance tend to exhibit under-reliance on AI systems, which hinders optimal team performance. Logic units-based explanations did not help users in either improving the calibration of their competence or facilitating appropriate reliance. While the tutorial intervention was highly effective in helping users calibrate their self-assessment and facilitating appropriate reliance among participants with overestimated self-assessment, we found that it can potentially hurt the appropriate reliance of participants with underestimated self-assessment. Our work has broad implications on the design of methods to tackle user cognitive biases while facilitating appropriate reliance on AI systems. Our findings advance the current understanding of the role of self-assessment in shaping trust and reliance in human-AI decision making. This lays out promising future directions for relevant HCI research in this community.
Complex Knowledge Base Question Answering: A Survey
Aug 15, 2021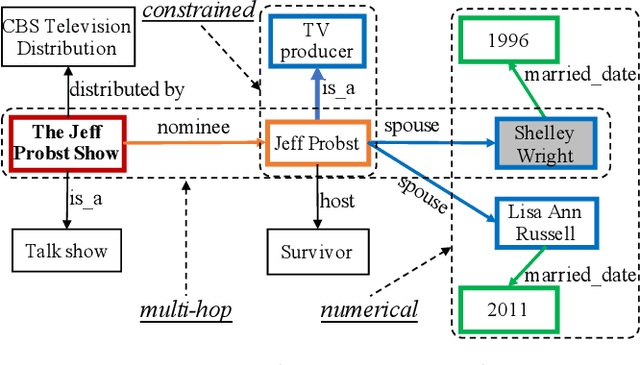
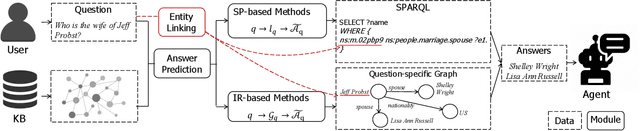

Knowledge base question answering (KBQA) aims to answer a question over a knowledge base (KB). Early studies mainly focused on answering simple questions over KBs and achieved great success. However, their performance on complex questions is still far from satisfactory. Therefore, in recent years, researchers propose a large number of novel methods, which looked into the challenges of answering complex questions. In this survey, we review recent advances on KBQA with the focus on solving complex questions, which usually contain multiple subjects, express compound relations, or involve numerical operations. In detail, we begin with introducing the complex KBQA task and relevant background. Then, we describe benchmark datasets for complex KBQA task and introduce the construction process of these datasets. Next, we present two mainstream categories of methods for complex KBQA, namely semantic parsing-based (SP-based) methods and information retrieval-based (IR-based) methods. Specifically, we illustrate their procedures with flow designs and discuss their major differences and similarities. After that, we summarize the challenges that these two categories of methods encounter when answering complex questions, and explicate advanced solutions and techniques used in existing work. Finally, we conclude and discuss several promising directions related to complex KBQA for future research.
A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions
May 25, 2021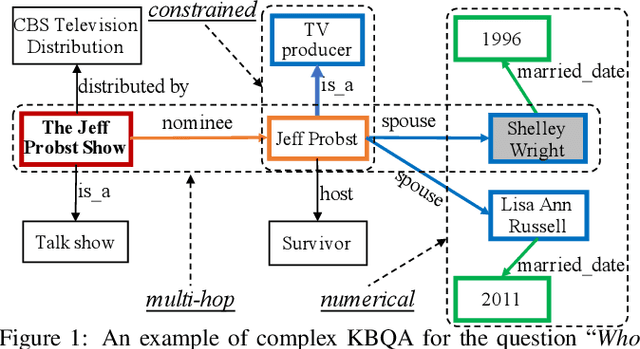



Knowledge base question answering (KBQA) aims to answer a question over a knowledge base (KB). Recently, a large number of studies focus on semantically or syntactically complicated questions. In this paper, we elaborately summarize the typical challenges and solutions for complex KBQA. We begin with introducing the background about the KBQA task. Next, we present the two mainstream categories of methods for complex KBQA, namely semantic parsing-based (SP-based) methods and information retrieval-based (IR-based) methods. We then review the advanced methods comprehensively from the perspective of the two categories. Specifically, we explicate their solutions to the typical challenges. Finally, we conclude and discuss some promising directions for future research.