 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Open-World Lottery Ticket for Out-of-Domain Intent Classification
Paper and Code
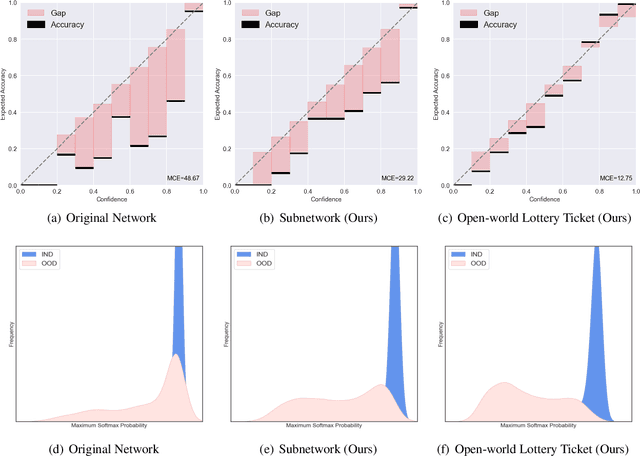
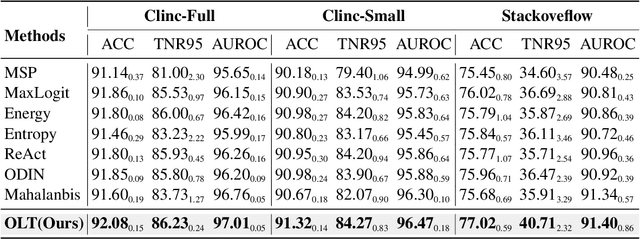

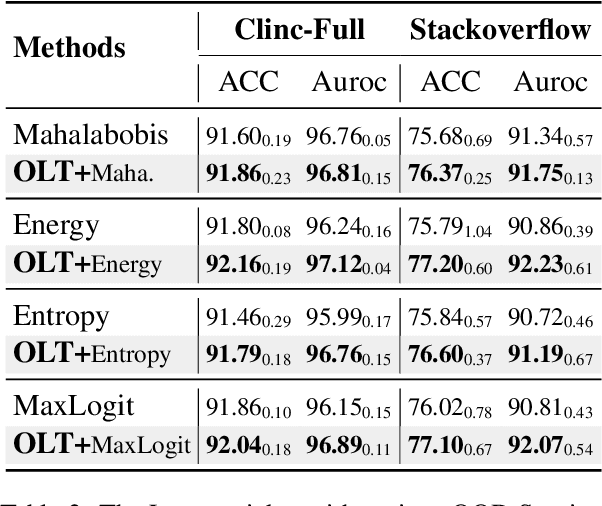
Most existing methods of Out-of-Domain (OOD) intent classification, which rely on extensive auxiliary OOD corpora or specific training paradigms, are underdeveloped in the underlying principle that the models should have differentiated confidence in In- and Out-of-domain intent. In this work, we demonstrate that calibrated subnetworks can be uncovered by pruning the (poor-calibrated) overparameterized model. Calibrated confidence provided by the subnetwork can better distinguish In- and Out-of-domain. Furthermore, we theoretically bring new insights into why temperature scaling can differentiate In- and Out-of-Domain intent and empirically extend the Lottery Ticket Hypothesis to the open-world setting. Extensive experiments on three real-world datasets demonstrate our approach can establish consistent improvements compared with a suite of competitive baselines.