 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Align: Structured Reasoning-guided Alignment for In-Context Image Generation and Editing
Jan 08, 2026In-context image generation and editing (ICGE) enables users to specify visual concepts through interleaved image-text prompts, demanding precise understanding and faithful execution of user intent. Although recent unified multimodal models exhibit promising understanding capabilities, these strengths often fail to transfer effectively to image generation. We introduce Re-Align, a unified framework that bridges the gap between understanding and generation through structured reasoning-guided alignment. At its core lies the In-Context Chain-of-Thought (IC-CoT), a structured reasoning paradigm that decouples semantic guidance and reference association, providing clear textual target and mitigating confusion among reference images. Furthermore, Re-Align introduces an effective RL training scheme that leverages a surrogate reward to measure the alignment between structured reasoning text and the generated image, thereby improving the model's overall performance on ICGE tasks. Extensive experiments verify that Re-Align outperforms competitive methods of comparable model scale and resources on both in-context image generation and editing tasks.
Align Beyond Prompts: Evaluating World Knowledge Alignment in Text-to-Image Generation
May 24, 2025Recent text-to-image (T2I) generation models have advanced significantly, enabling the creation of high-fidelity images from textual prompts. However, existing evaluation benchmarks primarily focus on the explicit alignment between generated images and prompts, neglecting the alignment with real-world knowledge beyond prompts. To address this gap, we introduce Align Beyond Prompts (ABP), a comprehensive benchmark designed to measure the alignment of generated images with real-world knowledge that extends beyond the explicit user prompts. ABP comprises over 2,000 meticulously crafted prompts, covering real-world knowledge across six distinct scenarios. We further introduce ABPScore, a metric that utilizes existing Multimodal Large Language Models (MLLMs) to assess the alignment between generated images and world knowledge beyond prompts, which demonstrates strong correlations with human judgments. Through a comprehensive evaluation of 8 popular T2I models using ABP, we find that even state-of-the-art models, such as GPT-4o, face limitations in integrating simple real-world knowledge into generated images. To mitigate this issue, we introduce a training-free strategy within ABP, named Inference-Time Knowledge Injection (ITKI). By applying this strategy to optimize 200 challenging samples, we achieved an improvement of approximately 43% in ABPScore. The dataset and code are available in https://github.com/smile365317/ABP.
Multimodal Music Generation with Explicit Bridges and Retrieval Augmentation
Dec 12, 2024Multimodal music generation aims to produce music from diverse input modalities, including text, videos, and images. Existing methods use a common embedding space for multimodal fusion. Despite their effectiveness in other modalities, their application in multimodal music generation faces challenges of data scarcity, weak cross-modal alignment, and limited controllability. This paper addresses these issues by using explicit bridges of text and music for multimodal alignment. We introduce a novel method named Visuals Music Bridge (VMB). Specifically, a Multimodal Music Description Model converts visual inputs into detailed textual descriptions to provide the text bridge; a Dual-track Music Retrieval module that combines broad and targeted retrieval strategies to provide the music bridge and enable user control. Finally, we design an Explicitly Conditioned Music Generation framework to generate music based on the two bridges. We conduct experiments on video-to-music, image-to-music, text-to-music, and controllable music generation tasks, along with experiments on controllability. The results demonstrate that VMB significantly enhances music quality, modality, and customization alignment compared to previous methods. VMB sets a new standard for interpretable and expressive multimodal music generation with applications in various multimedia fields. Demos and code are available at https://github.com/wbs2788/VMB.
FreeEdit: Mask-free Reference-based Image Editing with Multi-modal Instruction
Sep 26, 2024Introducing user-specified visual concepts in image editing is highly practical as these concepts convey the user's intent more precisely than text-based descriptions. We propose FreeEdit, a novel approach for achieving such reference-based image editing, which can accurately reproduce the visual concept from the reference image based on user-friendly language instructions. Our approach leverages the multi-modal instruction encoder to encode language instructions to guide the editing process. This implicit way of locating the editing area eliminates the need for manual editing masks. To enhance the reconstruction of reference details, we introduce the Decoupled Residual ReferAttention (DRRA) module. This module is designed to integrate fine-grained reference features extracted by a detail extractor into the image editing process in a residual way without interfering with the original self-attention. Given that existing datasets are unsuitable for reference-based image editing tasks, particularly due to the difficulty in constructing image triplets that include a reference image, we curate a high-quality dataset, FreeBench, using a newly developed twice-repainting scheme. FreeBench comprises the images before and after editing, detailed editing instructions, as well as a reference image that maintains the identity of the edited object, encompassing tasks such as object addition, replacement, and deletion. By conducting phased training on FreeBench followed by quality tuning, FreeEdit achieves high-quality zero-shot editing through convenient language instructions. We conduct extensive experiments to evaluate the effectiveness of FreeEdit across multiple task types, demonstrating its superiority over existing methods. The code will be available at: https://freeedit.github.io/.
Learning to Discover Forgery Cues for Face Forgery Detection
Sep 02, 2024



Locating manipulation maps, i.e., pixel-level annotation of forgery cues, is crucial for providing interpretable detection results in face forgery detection. Related learning objects have also been widely adopted as auxiliary tasks to improve the classification performance of detectors whereas they require comparisons between paired real and forged faces to obtain manipulation maps as supervision. This requirement restricts their applicability to unpaired faces and contradicts real-world scenarios. Moreover, the used comparison methods annotate all changed pixels, including noise introduced by compression and upsampling. Using such maps as supervision hinders the learning of exploitable cues and makes models prone to overfitting. To address these issues, we introduce a weakly supervised model in this paper, named Forgery Cue Discovery (FoCus), to locate forgery cues in unpaired faces. Unlike some detectors that claim to locate forged regions in attention maps, FoCus is designed to sidestep their shortcomings of capturing partial and inaccurate forgery cues. Specifically, we propose a classification attentive regions proposal module to locate forgery cues during classification and a complementary learning module to facilitate the learning of richer cues. The produced manipulation maps can serve as better supervision to enhance face forgery detectors. Visualization of the manipulation maps of the proposed FoCus exhibits superior interpretability and robustness compared to existing methods. Experiments on five datasets and four multi-task models demonstrate the effectiveness of FoCus in both in-dataset and cross-dataset evaluations.
Unveiling Structural Memorization: Structural Membership Inference Attack for Text-to-Image Diffusion Models
Jul 18, 2024With the rapid advancements of large-scale text-to-image diffusion models, various practical applications have emerged, bringing significant convenience to society. However, model developers may misuse the unauthorized data to train diffusion models. These data are at risk of being memorized by the models, thus potentially violating citizens' privacy rights. Therefore, in order to judge whether a specific image is utilized as a member of a model's training set, Membership Inference Attack (MIA) is proposed to serve as a tool for privacy protection. Current MIA methods predominantly utilize pixel-wise comparisons as distinguishing clues, considering the pixel-level memorization characteristic of diffusion models. However, it is practically impossible for text-to-image models to memorize all the pixel-level information in massive training sets. Therefore, we move to the more advanced structure-level memorization. Observations on the diffusion process show that the structures of members are better preserved compared to those of nonmembers, indicating that diffusion models possess the capability to remember the structures of member images from training sets. Drawing on these insights, we propose a simple yet effective MIA method tailored for text-to-image diffusion models. Extensive experimental results validate the efficacy of our approach. Compared to current pixel-level baselines, our approach not only achieves state-of-the-art performance but also demonstrates remarkable robustness against various distortions.
Explicit Correlation Learning for Generalizable Cross-Modal Deepfake Detection
Apr 30, 2024



With the rising prevalence of deepfakes, there is a growing interest in developing generalizable detection methods for various types of deepfakes. While effective in their specific modalities, traditional detection methods fall short in addressing the generalizability of detection across diverse cross-modal deepfakes. This paper aims to explicitly learn potential cross-modal correlation to enhance deepfake detection towards various generation scenarios. Our approach introduces a correlation distillation task, which models the inherent cross-modal correlation based on content information. This strategy helps to prevent the model from overfitting merely to audio-visual synchronization. Additionally, we present the Cross-Modal Deepfake Dataset (CMDFD), a comprehensive dataset with four generation methods to evaluate the detection of diverse cross-modal deepfakes. The experimental results on CMDFD and FakeAVCeleb datasets demonstrate the superior generalizability of our method over existing state-of-the-art methods. Our code and data can be found at \url{https://github.com/ljj898/CMDFD-Dataset-and-Deepfake-Detection}.
Model Will Tell: Training Membership Inference for Diffusion Models
Mar 13, 2024
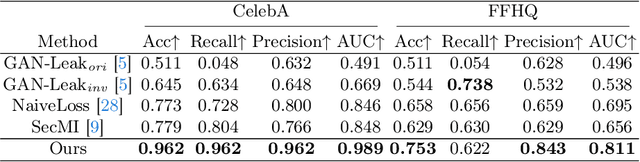
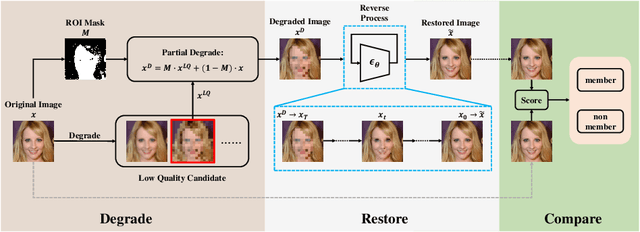
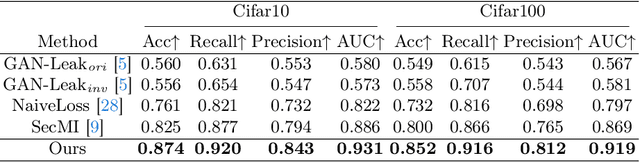
Diffusion models pose risks of privacy breaches and copyright disputes, primarily stemming from the potential utilization of unauthorized data during the training phase. The Training Membership Inference (TMI) task aims to determine whether a specific sample has been used in the training process of a target model, representing a critical tool for privacy violation verification. However, the increased stochasticity inherent in diffusion renders traditional shadow-model-based or metric-based methods ineffective when applied to diffusion models. Moreover, existing methods only yield binary classification labels which lack necessary comprehensibility in practical applications. In this paper, we explore a novel perspective for the TMI task by leveraging the intrinsic generative priors within the diffusion model. Compared with unseen samples, training samples exhibit stronger generative priors within the diffusion model, enabling the successful reconstruction of substantially degraded training images. Consequently, we propose the Degrade Restore Compare (DRC) framework. In this framework, an image undergoes sequential degradation and restoration, and its membership is determined by comparing it with the restored counterpart. Experimental results verify that our approach not only significantly outperforms existing methods in terms of accuracy but also provides comprehensible decision criteria, offering evidence for potential privacy violations.
Customize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global Iterative Training
Dec 04, 2023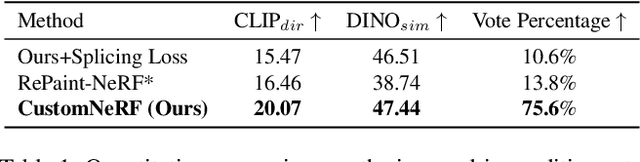
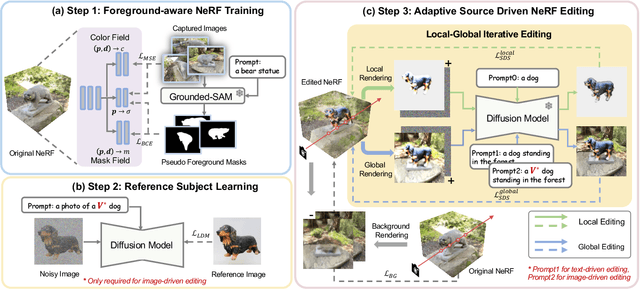


In this paper, we target the adaptive source driven 3D scene editing task by proposing a CustomNeRF model that unifies a text description or a reference image as the editing prompt. However, obtaining desired editing results conformed with the editing prompt is nontrivial since there exist two significant challenges, including accurate editing of only foreground regions and multi-view consistency given a single-view reference image. To tackle the first challenge, we propose a Local-Global Iterative Editing (LGIE) training scheme that alternates between foreground region editing and full-image editing, aimed at foreground-only manipulation while preserving the background. For the second challenge, we also design a class-guided regularization that exploits class priors within the generation model to alleviate the inconsistency problem among different views in image-driven editing. Extensive experiments show that our CustomNeRF produces precise editing results under various real scenes for both text- and image-driven settings.
Enriching Phrases with Coupled Pixel and Object Contexts for Panoptic Narrative Grounding
Nov 02, 2023Panoptic narrative grounding (PNG) aims to segment things and stuff objects in an image described by noun phrases of a narrative caption. As a multimodal task, an essential aspect of PNG is the visual-linguistic interaction between image and caption. The previous two-stage method aggregates visual contexts from offline-generated mask proposals to phrase features, which tend to be noisy and fragmentary. The recent one-stage method aggregates only pixel contexts from image features to phrase features, which may incur semantic misalignment due to lacking object priors. To realize more comprehensive visual-linguistic interaction, we propose to enrich phrases with coupled pixel and object contexts by designing a Phrase-Pixel-Object Transformer Decoder (PPO-TD), where both fine-grained part details and coarse-grained entity clues are aggregated to phrase features. In addition, we also propose a PhraseObject Contrastive Loss (POCL) to pull closer the matched phrase-object pairs and push away unmatched ones for aggregating more precise object contexts from more phrase-relevant object tokens. Extensive experiments on the PNG benchmark show our method achieves new state-of-the-art performance with large margins.