 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIRGAMER: Evaluating Biases in the Application of Large Language Models to Video Games
Aug 25, 2025Leveraging their advanced capabilities, Large Language Models (LLMs) demonstrate vast application potential in video games--from dynamic scene generation and intelligent NPC interactions to adaptive opponents--replacing or enhancing traditional game mechanics. However, LLMs' trustworthiness in this application has not been sufficiently explored. In this paper, we reveal that the models' inherent social biases can directly damage game balance in real-world gaming environments. To this end, we present FairGamer, the first bias evaluation Benchmark for LLMs in video game scenarios, featuring six tasks and a novel metrics ${D_lstd}$. It covers three key scenarios in games where LLMs' social biases are particularly likely to manifest: Serving as Non-Player Characters, Interacting as Competitive Opponents, and Generating Game Scenes. FairGamer utilizes both reality-grounded and fully fictional game content, covering a variety of video game genres. Experiments reveal: (1) Decision biases directly cause game balance degradation, with Grok-3 (average ${D_lstd}$ score=0.431) exhibiting the most severe degradation; (2) LLMs demonstrate isomorphic social/cultural biases toward both real and virtual world content, suggesting their biases nature may stem from inherent model characteristics. These findings expose critical reliability gaps in LLMs' gaming applications. Our code and data are available at anonymous GitHub https://github.com/Anonymous999-xxx/FairGamer .
HSENet: Hybrid Spatial Encoding Network for 3D Medical Vision-Language Understanding
Jun 11, 2025Automated 3D CT diagnosis empowers clinicians to make timely, evidence-based decisions by enhancing diagnostic accuracy and workflow efficiency. While multimodal large language models (MLLMs) exhibit promising performance in visual-language understanding, existing methods mainly focus on 2D medical images, which fundamentally limits their ability to capture complex 3D anatomical structures. This limitation often leads to misinterpretation of subtle pathologies and causes diagnostic hallucinations. In this paper, we present Hybrid Spatial Encoding Network (HSENet), a framework that exploits enriched 3D medical visual cues by effective visual perception and projection for accurate and robust vision-language understanding. Specifically, HSENet employs dual-3D vision encoders to perceive both global volumetric contexts and fine-grained anatomical details, which are pre-trained by dual-stage alignment with diagnostic reports. Furthermore, we propose Spatial Packer, an efficient multimodal projector that condenses high-resolution 3D spatial regions into a compact set of informative visual tokens via centroid-based compression. By assigning spatial packers with dual-3D vision encoders, HSENet can seamlessly perceive and transfer hybrid visual representations to LLM's semantic space, facilitating accurate diagnostic text generation. Experimental results demonstrate that our method achieves state-of-the-art performance in 3D language-visual retrieval (39.85% of R@100, +5.96% gain), 3D medical report generation (24.01% of BLEU-4, +8.01% gain), and 3D visual question answering (73.60% of Major Class Accuracy, +1.99% gain), confirming its effectiveness. Our code is available at https://github.com/YanzhaoShi/HSENet.
A survey of using EHR as real-world evidence for discovering and validating new drug indications
May 30, 2025Electronic Health Records (EHRs) have been increasingly used as real-world evidence (RWE) to support the discovery and validation of new drug indications. This paper surveys current approaches to EHR-based drug repurposing, covering data sources, processing methodologies, and representation techniques. It discusses study designs and statistical frameworks for evaluating drug efficacy. Key challenges in validation are discussed, with emphasis on the role of large language models (LLMs) and target trial emulation. By synthesizing recent developments and methodological advances, this work provides a foundational resource for researchers aiming to translate real-world data into actionable drug-repurposing evidence.
Align Beyond Prompts: Evaluating World Knowledge Alignment in Text-to-Image Generation
May 24, 2025Recent text-to-image (T2I) generation models have advanced significantly, enabling the creation of high-fidelity images from textual prompts. However, existing evaluation benchmarks primarily focus on the explicit alignment between generated images and prompts, neglecting the alignment with real-world knowledge beyond prompts. To address this gap, we introduce Align Beyond Prompts (ABP), a comprehensive benchmark designed to measure the alignment of generated images with real-world knowledge that extends beyond the explicit user prompts. ABP comprises over 2,000 meticulously crafted prompts, covering real-world knowledge across six distinct scenarios. We further introduce ABPScore, a metric that utilizes existing Multimodal Large Language Models (MLLMs) to assess the alignment between generated images and world knowledge beyond prompts, which demonstrates strong correlations with human judgments. Through a comprehensive evaluation of 8 popular T2I models using ABP, we find that even state-of-the-art models, such as GPT-4o, face limitations in integrating simple real-world knowledge into generated images. To mitigate this issue, we introduce a training-free strategy within ABP, named Inference-Time Knowledge Injection (ITKI). By applying this strategy to optimize 200 challenging samples, we achieved an improvement of approximately 43% in ABPScore. The dataset and code are available in https://github.com/smile365317/ABP.
A New Federated Learning Framework Against Gradient Inversion Attacks
Dec 10, 2024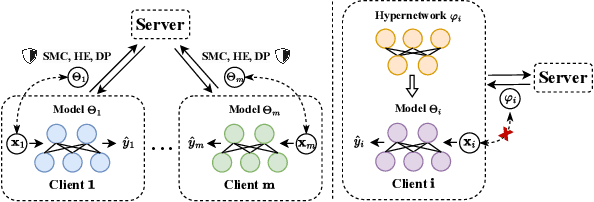
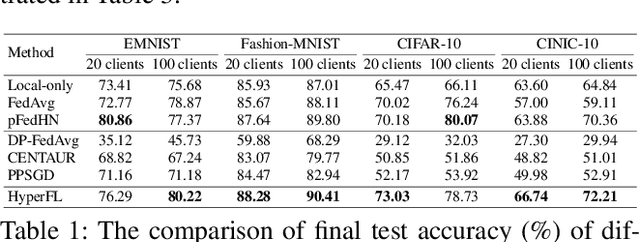
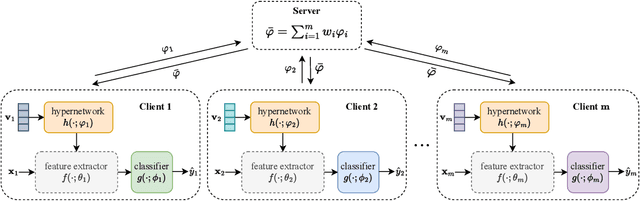
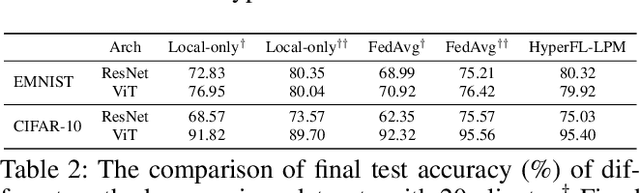
Federated Learning (FL) aims to protect data privacy by enabling clients to collectively train machine learning models without sharing their raw data. However, recent studies demonstrate that information exchanged during FL is subject to Gradient Inversion Attacks (GIA) and, consequently, a variety of privacy-preserving methods have been integrated into FL to thwart such attacks, such as Secure Multi-party Computing (SMC), Homomorphic Encryption (HE), and Differential Privacy (DP). Despite their ability to protect data privacy, these approaches inherently involve substantial privacy-utility trade-offs. By revisiting the key to privacy exposure in FL under GIA, which lies in the frequent sharing of model gradients that contain private data, we take a new perspective by designing a novel privacy preserve FL framework that effectively ``breaks the direct connection'' between the shared parameters and the local private data to defend against GIA. Specifically, we propose a Hypernetwork Federated Learning (HyperFL) framework that utilizes hypernetworks to generate the parameters of the local model and only the hypernetwork parameters are uploaded to the server for aggregation. Theoretical analyses demonstrate the convergence rate of the proposed HyperFL, while extensive experimental results show the privacy-preserving capability and comparable performance of HyperFL. Code is available at https://github.com/Pengxin-Guo/HyperFL.
Semantic Segmentation Prior for Diffusion-Based Real-World Super-Resolution
Dec 04, 2024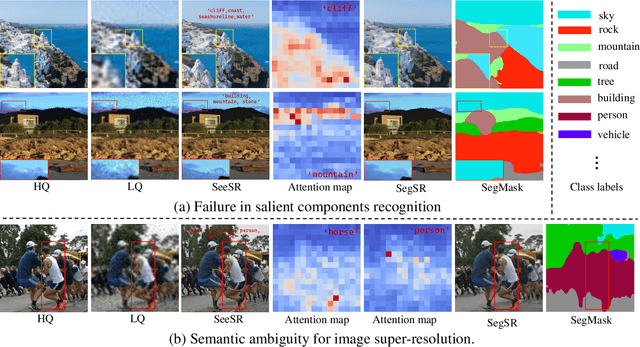
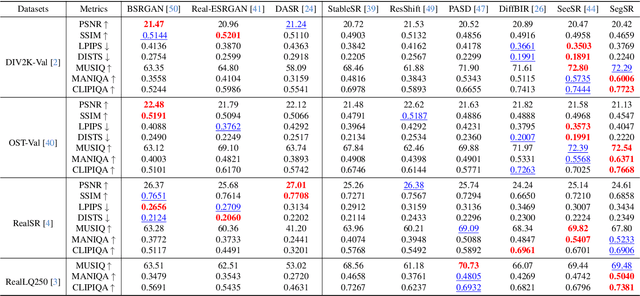
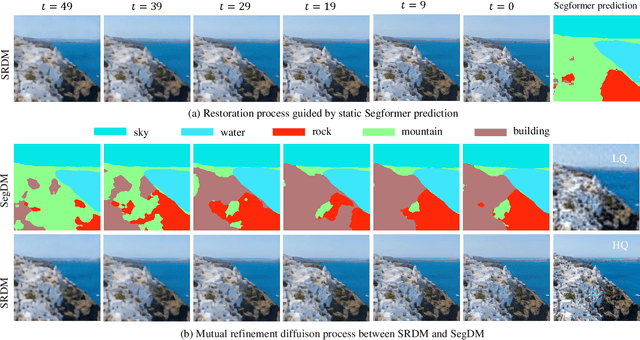

Real-world image super-resolution (Real-ISR) has achieved a remarkable leap by leveraging large-scale text-to-image models, enabling realistic image restoration from given recognition textual prompts. However, these methods sometimes fail to recognize some salient objects, resulting in inaccurate semantic restoration in these regions. Additionally, the same region may have a strong response to more than one prompt and it will lead to semantic ambiguity for image super-resolution. To alleviate the above two issues, in this paper, we propose to consider semantic segmentation as an additional control condition into diffusion-based image super-resolution. Compared to textual prompt conditions, semantic segmentation enables a more comprehensive perception of salient objects within an image by assigning class labels to each pixel. It also mitigates the risks of semantic ambiguities by explicitly allocating objects to their respective spatial regions. In practice, inspired by the fact that image super-resolution and segmentation can benefit each other, we propose SegSR which introduces a dual-diffusion framework to facilitate interaction between the image super-resolution and segmentation diffusion models. Specifically, we develop a Dual-Modality Bridge module to enable updated information flow between these two diffusion models, achieving mutual benefit during the reverse diffusion process. Extensive experiments show that SegSR can generate realistic images while preserving semantic structures more effectively.
See Detail Say Clear: Towards Brain CT Report Generation via Pathological Clue-driven Representation Learning
Sep 29, 2024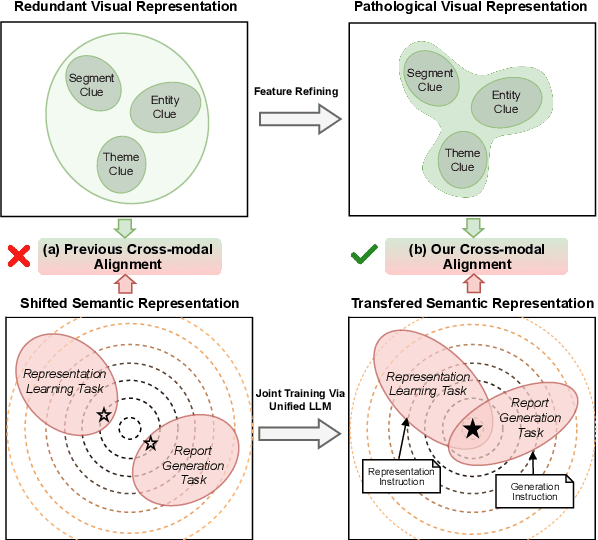
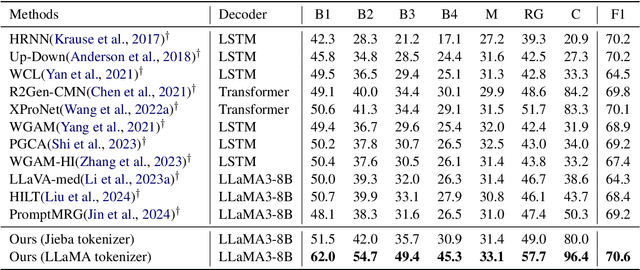
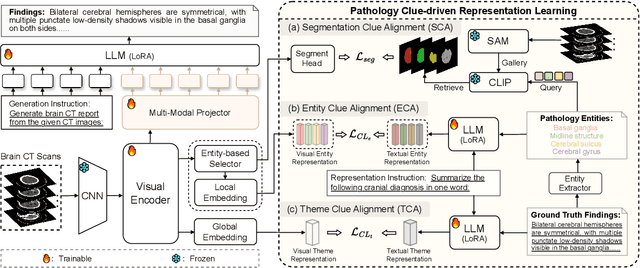
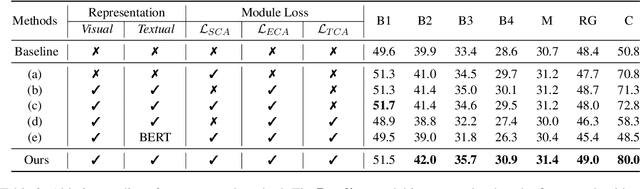
Brain CT report generation is significant to aid physicians in diagnosing cranial diseases. Recent studies concentrate on handling the consistency between visual and textual pathological features to improve the coherence of report. However, there exist some challenges: 1) Redundant visual representing: Massive irrelevant areas in 3D scans distract models from representing salient visual contexts. 2) Shifted semantic representing: Limited medical corpus causes difficulties for models to transfer the learned textual representations to generative layers. This study introduces a Pathological Clue-driven Representation Learning (PCRL) model to build cross-modal representations based on pathological clues and naturally adapt them for accurate report generation. Specifically, we construct pathological clues from perspectives of segmented regions, pathological entities, and report themes, to fully grasp visual pathological patterns and learn cross-modal feature representations. To adapt the representations for the text generation task, we bridge the gap between representation learning and report generation by using a unified large language model (LLM) with task-tailored instructions. These crafted instructions enable the LLM to be flexibly fine-tuned across tasks and smoothly transfer the semantic representation for report generation. Experiments demonstrate that our method outperforms previous methods and achieves SoTA performance. Our code is available at https://github.com/Chauncey-Jheng/PCRL-MRG.
Augmented Risk Prediction for the Onset of Alzheimer's Disease from Electronic Health Records with Large Language Models
May 26, 2024



Alzheimer's disease (AD) is the fifth-leading cause of death among Americans aged 65 and older. Screening and early detection of AD and related dementias (ADRD) are critical for timely intervention and for identifying clinical trial participants. The widespread adoption of electronic health records (EHRs) offers an important resource for developing ADRD screening tools such as machine learning based predictive models. Recent advancements in large language models (LLMs) demonstrate their unprecedented capability of encoding knowledge and performing reasoning, which offers them strong potential for enhancing risk prediction. This paper proposes a novel pipeline that augments risk prediction by leveraging the few-shot inference power of LLMs to make predictions on cases where traditional supervised learning methods (SLs) may not excel. Specifically, we develop a collaborative pipeline that combines SLs and LLMs via a confidence-driven decision-making mechanism, leveraging the strengths of SLs in clear-cut cases and LLMs in more complex scenarios. We evaluate this pipeline using a real-world EHR data warehouse from Oregon Health \& Science University (OHSU) Hospital, encompassing EHRs from over 2.5 million patients and more than 20 million patient encounters. Our results show that our proposed approach effectively combines the power of SLs and LLMs, offering significant improvements in predictive performance. This advancement holds promise for revolutionizing ADRD screening and early detection practices, with potential implications for better strategies of patient management and thus improving healthcare.
Can LLMs Deeply Detect Complex Malicious Queries? A Framework for Jailbreaking via Obfuscating Intent
May 07, 2024



To demonstrate and address the underlying maliciousness, we propose a theoretical hypothesis and analytical approach, and introduce a new black-box jailbreak attack methodology named IntentObfuscator, exploiting this identified flaw by obfuscating the true intentions behind user prompts.This approach compels LLMs to inadvertently generate restricted content, bypassing their built-in content security measures. We detail two implementations under this framework: "Obscure Intention" and "Create Ambiguity", which manipulate query complexity and ambiguity to evade malicious intent detection effectively. We empirically validate the effectiveness of the IntentObfuscator method across several models, including ChatGPT-3.5, ChatGPT-4, Qwen and Baichuan, achieving an average jailbreak success rate of 69.21\%. Notably, our tests on ChatGPT-3.5, which claims 100 million weekly active users, achieved a remarkable success rate of 83.65\%. We also extend our validation to diverse types of sensitive content like graphic violence, racism, sexism, political sensitivity, cybersecurity threats, and criminal skills, further proving the substantial impact of our findings on enhancing 'Red Team' strategies against LLM content security frameworks.
Spatially Non-Stationary XL-MIMO Channel Estimation: A Three-Layer Generalized Approximate Message Passing Method
Mar 05, 2024



In this paper, channel estimation problem for extremely large-scale multi-input multi-output (XL-MIMO) systems is investigated with the considerations of the spherical wavefront effect and the spatially non-stationary (SnS) property. Due to the diversities of SnS characteristics among different propagation paths, the concurrent channel estimation of multiple paths becomes intractable. To address this challenge, we propose a two-phase channel estimation scheme. In the first phase, the angles of departure (AoDs) on the user side are estimated, and a carefully designed pilot transmission scheme enables the decomposition of the received signal from different paths. In the second phase, the subchannel estimation corresponding to different paths is formulated as a three-layer Bayesian inference problem. Specifically, the first layer captures block sparsity in the angular domain, the second layer promotes SnS property in the antenna domain, and the third layer decouples the subchannels from the observed signals. To efficiently facilitate Bayesian inference, we propose a novel three-layer generalized approximate message passing (TL-GAMP) algorithm based on structured variational massage passing and belief propagation rules. Simulation results validate the convergence and effectiveness of the proposed algorithm, showcasing its robustness to different channel scenarios.