 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSENet: Hybrid Spatial Encoding Network for 3D Medical Vision-Language Understanding
Jun 11, 2025Automated 3D CT diagnosis empowers clinicians to make timely, evidence-based decisions by enhancing diagnostic accuracy and workflow efficiency. While multimodal large language models (MLLMs) exhibit promising performance in visual-language understanding, existing methods mainly focus on 2D medical images, which fundamentally limits their ability to capture complex 3D anatomical structures. This limitation often leads to misinterpretation of subtle pathologies and causes diagnostic hallucinations. In this paper, we present Hybrid Spatial Encoding Network (HSENet), a framework that exploits enriched 3D medical visual cues by effective visual perception and projection for accurate and robust vision-language understanding. Specifically, HSENet employs dual-3D vision encoders to perceive both global volumetric contexts and fine-grained anatomical details, which are pre-trained by dual-stage alignment with diagnostic reports. Furthermore, we propose Spatial Packer, an efficient multimodal projector that condenses high-resolution 3D spatial regions into a compact set of informative visual tokens via centroid-based compression. By assigning spatial packers with dual-3D vision encoders, HSENet can seamlessly perceive and transfer hybrid visual representations to LLM's semantic space, facilitating accurate diagnostic text generation. Experimental results demonstrate that our method achieves state-of-the-art performance in 3D language-visual retrieval (39.85% of R@100, +5.96% gain), 3D medical report generation (24.01% of BLEU-4, +8.01% gain), and 3D visual question answering (73.60% of Major Class Accuracy, +1.99% gain), confirming its effectiveness. Our code is available at https://github.com/YanzhaoShi/HSENet.
See Detail Say Clear: Towards Brain CT Report Generation via Pathological Clue-driven Representation Learning
Sep 29, 2024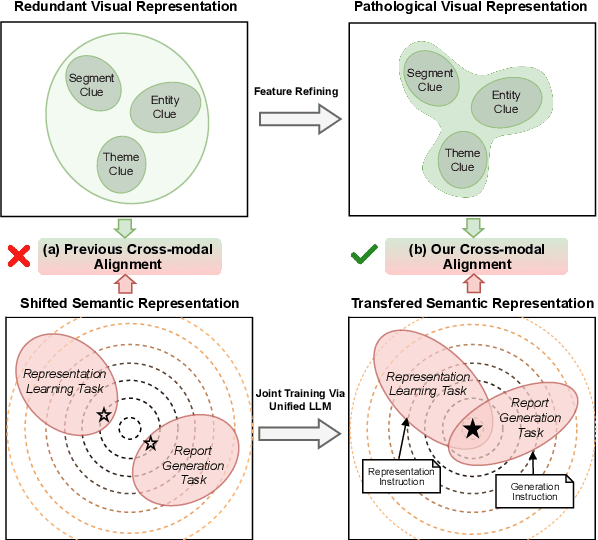
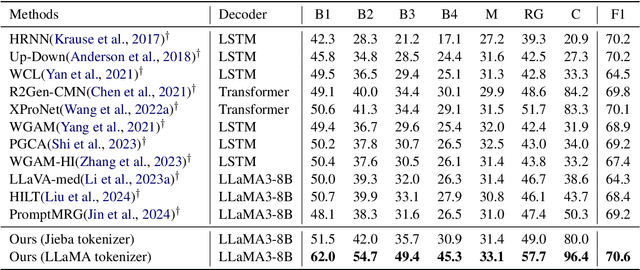
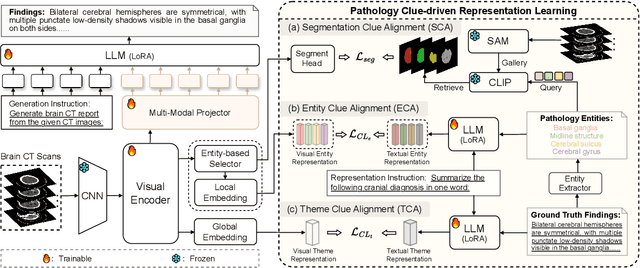
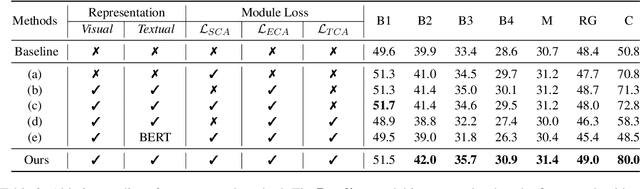
Brain CT report generation is significant to aid physicians in diagnosing cranial diseases. Recent studies concentrate on handling the consistency between visual and textual pathological features to improve the coherence of report. However, there exist some challenges: 1) Redundant visual representing: Massive irrelevant areas in 3D scans distract models from representing salient visual contexts. 2) Shifted semantic representing: Limited medical corpus causes difficulties for models to transfer the learned textual representations to generative layers. This study introduces a Pathological Clue-driven Representation Learning (PCRL) model to build cross-modal representations based on pathological clues and naturally adapt them for accurate report generation. Specifically, we construct pathological clues from perspectives of segmented regions, pathological entities, and report themes, to fully grasp visual pathological patterns and learn cross-modal feature representations. To adapt the representations for the text generation task, we bridge the gap between representation learning and report generation by using a unified large language model (LLM) with task-tailored instructions. These crafted instructions enable the LLM to be flexibly fine-tuned across tasks and smoothly transfer the semantic representation for report generation. Experiments demonstrate that our method outperforms previous methods and achieves SoTA performance. Our code is available at https://github.com/Chauncey-Jheng/PCRL-MRG.