 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPO:Reinforcement Fine-Tuning with Partial Reasoning Optimization
Jan 27, 2026Within the domain of large language models, reinforcement fine-tuning algorithms necessitate the generation of a complete reasoning trajectory beginning from the input query, which incurs significant computational overhead during the rollout phase of training. To address this issue, we analyze the impact of different segments of the reasoning path on the correctness of the final result and, based on these insights, propose Reinforcement Fine-Tuning with Partial Reasoning Optimization (RPO), a plug-and-play reinforcement fine-tuning algorithm. Unlike traditional reinforcement fine-tuning algorithms that generate full reasoning paths, RPO trains the model by generating suffixes of the reasoning path using experience cache. During the rollout phase of training, RPO reduces token generation in this phase by approximately 95%, greatly lowering the theoretical time overhead. Compared with full-path reinforcement fine-tuning algorithms, RPO reduces the training time of the 1.5B model by 90% and the 7B model by 72%. At the same time, it can be integrated with typical algorithms such as GRPO and DAPO, enabling them to achieve training acceleration while maintaining performance comparable to the original algorithms. Our code is open-sourced at https://github.com/yhz5613813/RPO.
FAIRGAMER: Evaluating Biases in the Application of Large Language Models to Video Games
Aug 25, 2025Leveraging their advanced capabilities, Large Language Models (LLMs) demonstrate vast application potential in video games--from dynamic scene generation and intelligent NPC interactions to adaptive opponents--replacing or enhancing traditional game mechanics. However, LLMs' trustworthiness in this application has not been sufficiently explored. In this paper, we reveal that the models' inherent social biases can directly damage game balance in real-world gaming environments. To this end, we present FairGamer, the first bias evaluation Benchmark for LLMs in video game scenarios, featuring six tasks and a novel metrics ${D_lstd}$. It covers three key scenarios in games where LLMs' social biases are particularly likely to manifest: Serving as Non-Player Characters, Interacting as Competitive Opponents, and Generating Game Scenes. FairGamer utilizes both reality-grounded and fully fictional game content, covering a variety of video game genres. Experiments reveal: (1) Decision biases directly cause game balance degradation, with Grok-3 (average ${D_lstd}$ score=0.431) exhibiting the most severe degradation; (2) LLMs demonstrate isomorphic social/cultural biases toward both real and virtual world content, suggesting their biases nature may stem from inherent model characteristics. These findings expose critical reliability gaps in LLMs' gaming applications. Our code and data are available at anonymous GitHub https://github.com/Anonymous999-xxx/FairGamer .
JTCSE: Joint Tensor-Modulus Constraints and Cross-Attention for Unsupervised Contrastive Learning of Sentence Embeddings
May 05, 2025Unsupervised contrastive learning has become a hot research topic in natural language processing. Existing works usually aim at constraining the orientation distribution of the representations of positive and negative samples in the high-dimensional semantic space in contrastive learning, but the semantic representation tensor possesses both modulus and orientation features, and the existing works ignore the modulus feature of the representations and cause insufficient contrastive learning. % Therefore, we firstly propose a training objective that aims at modulus constraints on the semantic representation tensor, to strengthen the alignment between the positive samples in contrastive learning. Therefore, we first propose a training objective that is designed to impose modulus constraints on the semantic representation tensor, to strengthen the alignment between positive samples in contrastive learning. Then, the BERT-like model suffers from the phenomenon of sinking attention, leading to a lack of attention to CLS tokens that aggregate semantic information. In response, we propose a cross-attention structure among the twin-tower ensemble models to enhance the model's attention to CLS token and optimize the quality of CLS Pooling. Combining the above two motivations, we propose a new \textbf{J}oint \textbf{T}ensor representation modulus constraint and \textbf{C}ross-attention unsupervised contrastive learning \textbf{S}entence \textbf{E}mbedding representation framework JTCSE, which we evaluate in seven semantic text similarity computation tasks, and the experimental results show that JTCSE's twin-tower ensemble model and single-tower distillation model outperform the other baselines and become the current SOTA. In addition, we have conducted an extensive zero-shot downstream task evaluation, which shows that JTCSE outperforms other baselines overall on more than 130 tasks.
TNCSE: Tensor's Norm Constraints for Unsupervised Contrastive Learning of Sentence Embeddings
Mar 17, 2025

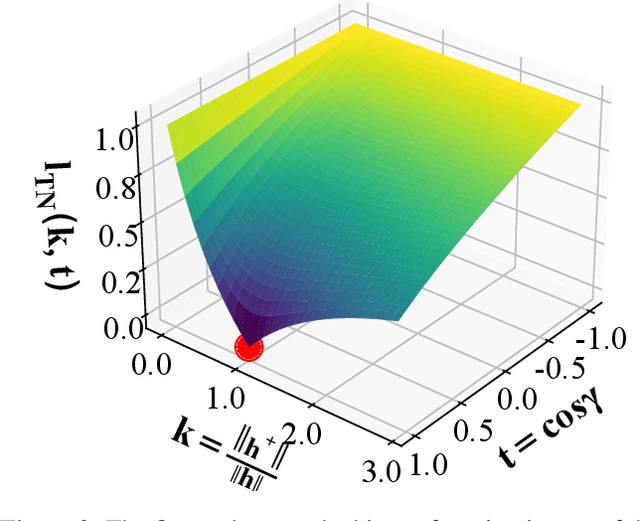

Unsupervised sentence embedding representation has become a hot research topic in natural language processing. As a tensor, sentence embedding has two critical properties: direction and norm. Existing works have been limited to constraining only the orientation of the samples' representations while ignoring the features of their module lengths. To address this issue, we propose a new training objective that optimizes the training of unsupervised contrastive learning by constraining the module length features between positive samples. We combine the training objective of Tensor's Norm Constraints with ensemble learning to propose a new Sentence Embedding representation framework, TNCSE. We evaluate seven semantic text similarity tasks, and the results show that TNCSE and derived models are the current state-of-the-art approach; in addition, we conduct extensive zero-shot evaluations, and the results show that TNCSE outperforms other baselines.
General Phrase Debiaser: Debiasing Masked Language Models at a Multi-Token Level
Nov 23, 2023The social biases and unwelcome stereotypes revealed by pretrained language models are becoming obstacles to their application. Compared to numerous debiasing methods targeting word level, there has been relatively less attention on biases present at phrase level, limiting the performance of debiasing in discipline domains. In this paper, we propose an automatic multi-token debiasing pipeline called \textbf{General Phrase Debiaser}, which is capable of mitigating phrase-level biases in masked language models. Specifically, our method consists of a \textit{phrase filter stage} that generates stereotypical phrases from Wikipedia pages as well as a \textit{model debias stage} that can debias models at the multi-token level to tackle bias challenges on phrases. The latter searches for prompts that trigger model's bias, and then uses them for debiasing. State-of-the-art results on standard datasets and metrics show that our approach can significantly reduce gender biases on both career and multiple disciplines, across models with varying parameter sizes.