 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Segmentation Prior for Diffusion-Based Real-World Super-Resolution
Paper and Code
Dec 04, 2024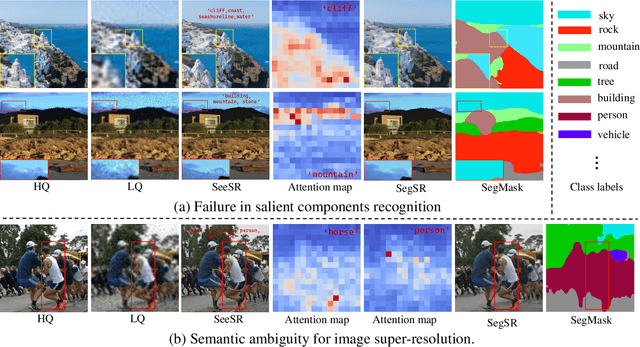
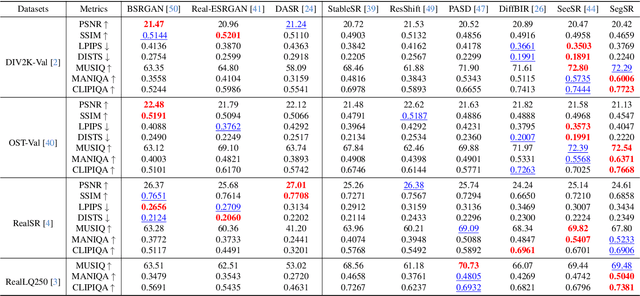
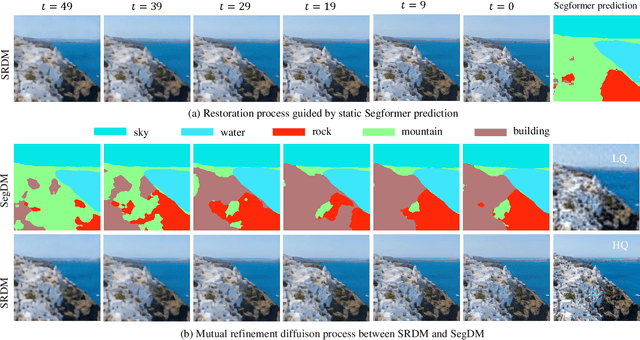

Real-world image super-resolution (Real-ISR) has achieved a remarkable leap by leveraging large-scale text-to-image models, enabling realistic image restoration from given recognition textual prompts. However, these methods sometimes fail to recognize some salient objects, resulting in inaccurate semantic restoration in these regions. Additionally, the same region may have a strong response to more than one prompt and it will lead to semantic ambiguity for image super-resolution. To alleviate the above two issues, in this paper, we propose to consider semantic segmentation as an additional control condition into diffusion-based image super-resolution. Compared to textual prompt conditions, semantic segmentation enables a more comprehensive perception of salient objects within an image by assigning class labels to each pixel. It also mitigates the risks of semantic ambiguities by explicitly allocating objects to their respective spatial regions. In practice, inspired by the fact that image super-resolution and segmentation can benefit each other, we propose SegSR which introduces a dual-diffusion framework to facilitate interaction between the image super-resolution and segmentation diffusion models. Specifically, we develop a Dual-Modality Bridge module to enable updated information flow between these two diffusion models, achieving mutual benefit during the reverse diffusion process. Extensive experiments show that SegSR can generate realistic images while preserving semantic structures more effectively.