 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth Multi-Policy Causal Effect Estimation in Longitudinal Settings
May 14, 2026Comparative evaluation of multiple dynamic treatment policies is essential for healthcare and policy decisions, yet conventional longitudinal causal inference methods estimate each in isolation, preventing information sharing across counterfactuals. We demonstrate that this separate estimation paradigm induces a structurally uncontrolled second-order bias, inflating finite-sample variance even after standard debiasing with longitudinal targeted maximum likelihood estimation(LTMLE). To address this, we propose a policy-aware reparameterization of Iterative Conditional Expectation (ICE) Q-functions that enables joint estimation through shared representations. We implement this approach in the Policy-Encoded Q Network (PEQ-Net), an architecture centered on a shared policy encoder. The encoder is trained using kernel mean embeddings, ensuring that the learned representation space reflects population-level policy dissimilarities. After applying an LTMLE correction step, we prove this design imposes a structural constraint on the second-order remainder, thereby stabilizing finite-sample variance. Experiments on semi-synthetic datasets demonstrate that PEQ-Net consistently outperforms existing ICE-based methods, achieving substantial reductions in root-mean-square error, particularly when evaluating closely related policies.
Deep Doubly Debiased Longitudinal Effect Estimation with ICE G-Computation
Feb 12, 2026Estimating longitudinal treatment effects is essential for sequential decision-making but is challenging due to treatment-confounder feedback. While Iterative Conditional Expectation (ICE) G-computation offers a principled approach, its recursive structure suffers from error propagation, corrupting the learned outcome regression models. We propose D3-Net, a framework that mitigates error propagation in ICE training and then applies a robust final correction. First, to interrupt error propagation during learning, we train the ICE sequence using Sequential Doubly Robust (SDR) pseudo-outcomes, which provide bias-corrected targets for each regression. Second, we employ a multi-task Transformer with a covariate simulator head for auxiliary supervision, regularizing representations against corruption by noisy pseudo-outcomes, and a target network to stabilize training dynamics. For the final estimate, we discard the SDR correction and instead use the uncorrected nuisance models to perform Longitudinal Targeted Minimum Loss-Based Estimation (LTMLE) on the original outcomes. This second-stage, targeted debiasing ensures robustness and optimal finite-sample properties. Comprehensive experiments demonstrate that our model, D3-Net, robustly reduces bias and variance across different horizons, counterfactuals, and time-varying confoundings, compared to existing state-of-the-art ICE-based estimators.
Efficient Imputation for Patch-based Missing Single-cell Data via Cluster-regularized Optimal Transport
Jan 21, 2026Missing data in single-cell sequencing datasets poses significant challenges for extracting meaningful biological insights. However, existing imputation approaches, which often assume uniformity and data completeness, struggle to address cases with large patches of missing data. In this paper, we present CROT, an optimal transport-based imputation algorithm designed to handle patch-based missing data in tabular formats. Our approach effectively captures the underlying data structure in the presence of significant missingness. Notably, it achieves superior imputation accuracy while significantly reducing runtime, demonstrating its scalability and efficiency for large-scale datasets. This work introduces a robust solution for imputation in heterogeneous, high-dimensional datasets with structured data absence, addressing critical challenges in both biological and clinical data analysis. Our code is available at Anomalous Github.
MOSIC: Model-Agnostic Optimal Subgroup Identification with Multi-Constraint for Improved Reliability
Apr 29, 2025
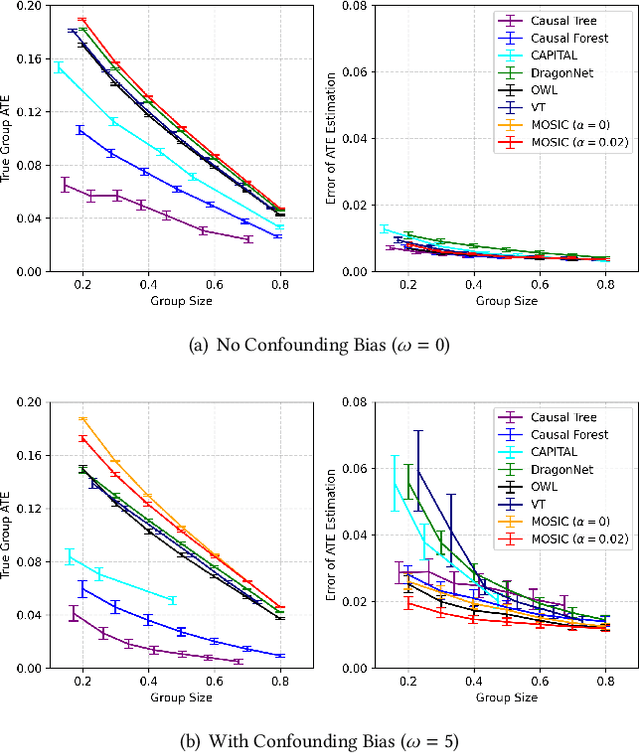


Identifying subgroups that benefit from specific treatments using observational data is a critical challenge in personalized medicine. Most existing approaches solely focus on identifying a subgroup with an improved treatment effect. However, practical considerations, such as ensuring a minimum subgroup size for representativeness or achieving sufficient confounder balance for reliability, are also important for making findings clinically meaningful and actionable. While some studies address these constraints individually, none offer a unified approach to handle them simultaneously. To bridge this gap, we propose a model-agnostic framework for optimal subgroup identification under multiple constraints. We reformulate this combinatorial problem as an unconstrained min-max optimization problem with novel modifications and solve it by a gradient descent ascent algorithm. We further prove its convergence to a feasible and locally optimal solution. Our method is stable and highly flexible, supporting various models and techniques for estimating and optimizing treatment effectiveness with observational data. Extensive experiments on both synthetic and real-world datasets demonstrate its effectiveness in identifying subgroups that satisfy multiple constraints, achieving higher treatment effects and better confounder balancing results across different group sizes.
Augmented Risk Prediction for the Onset of Alzheimer's Disease from Electronic Health Records with Large Language Models
May 26, 2024



Alzheimer's disease (AD) is the fifth-leading cause of death among Americans aged 65 and older. Screening and early detection of AD and related dementias (ADRD) are critical for timely intervention and for identifying clinical trial participants. The widespread adoption of electronic health records (EHRs) offers an important resource for developing ADRD screening tools such as machine learning based predictive models. Recent advancements in large language models (LLMs) demonstrate their unprecedented capability of encoding knowledge and performing reasoning, which offers them strong potential for enhancing risk prediction. This paper proposes a novel pipeline that augments risk prediction by leveraging the few-shot inference power of LLMs to make predictions on cases where traditional supervised learning methods (SLs) may not excel. Specifically, we develop a collaborative pipeline that combines SLs and LLMs via a confidence-driven decision-making mechanism, leveraging the strengths of SLs in clear-cut cases and LLMs in more complex scenarios. We evaluate this pipeline using a real-world EHR data warehouse from Oregon Health \& Science University (OHSU) Hospital, encompassing EHRs from over 2.5 million patients and more than 20 million patient encounters. Our results show that our proposed approach effectively combines the power of SLs and LLMs, offering significant improvements in predictive performance. This advancement holds promise for revolutionizing ADRD screening and early detection practices, with potential implications for better strategies of patient management and thus improving healthcare.
Joint Analysis of Single-Cell Data across Cohorts with Missing Modalities
May 18, 2024



Joint analysis of multi-omic single-cell data across cohorts has significantly enhanced the comprehensive analysis of cellular processes. However, most of the existing approaches for this purpose require access to samples with complete modality availability, which is impractical in many real-world scenarios. In this paper, we propose (Single-Cell Cross-Cohort Cross-Category) integration, a novel framework that learns unified cell representations under domain shift without requiring full-modality reference samples. Our generative approach learns rich cross-modal and cross-domain relationships that enable imputation of these missing modalities. Through experiments on real-world multi-omic datasets, we demonstrate that offers a robust solution to single-cell tasks such as cell type clustering, cell type classification, and feature imputation.
Local Discovery by Partitioning: Polynomial-Time Causal Discovery Around Exposure-Outcome Pairs
Oct 25, 2023



This work addresses the problem of automated covariate selection under limited prior knowledge. Given an exposure-outcome pair {X,Y} and a variable set Z of unknown causal structure, the Local Discovery by Partitioning (LDP) algorithm partitions Z into subsets defined by their relation to {X,Y}. We enumerate eight exhaustive and mutually exclusive partitions of any arbitrary Z and leverage this taxonomy to differentiate confounders from other variable types. LDP is motivated by valid adjustment set identification, but avoids the pretreatment assumption commonly made by automated covariate selection methods. We provide theoretical guarantees that LDP returns a valid adjustment set for any Z that meets sufficient graphical conditions. Under stronger conditions, we prove that partition labels are asymptotically correct. Total independence tests is worst-case quadratic in |Z|, with sub-quadratic runtimes observed empirically. We numerically validate our theoretical guarantees on synthetic and semi-synthetic graphs. Adjustment sets from LDP yield less biased and more precise average treatment effect estimates than baselines, with LDP outperforming on confounder recall, test count, and runtime for valid adjustment set discovery.
Bipartite Ranking Fairness through a Model Agnostic Ordering Adjustment
Jul 27, 2023



Algorithmic fairness has been a serious concern and received lots of interest in machine learning community. In this paper, we focus on the bipartite ranking scenario, where the instances come from either the positive or negative class and the goal is to learn a ranking function that ranks positive instances higher than negative ones. While there could be a trade-off between fairness and performance, we propose a model agnostic post-processing framework xOrder for achieving fairness in bipartite ranking and maintaining the algorithm classification performance. In particular, we optimize a weighted sum of the utility as identifying an optimal warping path across different protected groups and solve it through a dynamic programming process. xOrder is compatible with various classification models and ranking fairness metrics, including supervised and unsupervised fairness metrics. In addition to binary groups, xOrder can be applied to multiple protected groups. We evaluate our proposed algorithm on four benchmark data sets and two real-world patient electronic health record repositories. xOrder consistently achieves a better balance between the algorithm utility and ranking fairness on a variety of datasets with different metrics. From the visualization of the calibrated ranking scores, xOrder mitigates the score distribution shifts of different groups compared with baselines. Moreover, additional analytical results verify that xOrder achieves a robust performance when faced with fewer samples and a bigger difference between training and testing ranking score distributions.
InfoDiffusion: Representation Learning Using Information Maximizing Diffusion Models
Jun 14, 2023



While diffusion models excel at generating high-quality samples, their latent variables typically lack semantic meaning and are not suitable for representation learning. Here, we propose InfoDiffusion, an algorithm that augments diffusion models with low-dimensional latent variables that capture high-level factors of variation in the data. InfoDiffusion relies on a learning objective regularized with the mutual information between observed and hidden variables, which improves latent space quality and prevents the latents from being ignored by expressive diffusion-based decoders. Empirically, we find that InfoDiffusion learns disentangled and human-interpretable latent representations that are competitive with state-of-the-art generative and contrastive methods, while retaining the high sample quality of diffusion models. Our method enables manipulating the attributes of generated images and has the potential to assist tasks that require exploring a learned latent space to generate quality samples, e.g., generative design.
Patchwork Learning: A Paradigm Towards Integrative Analysis across Diverse Biomedical Data Sources
May 13, 2023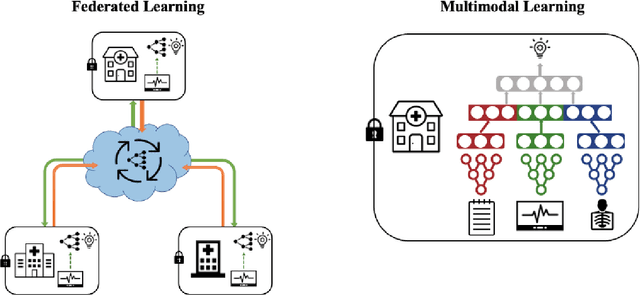


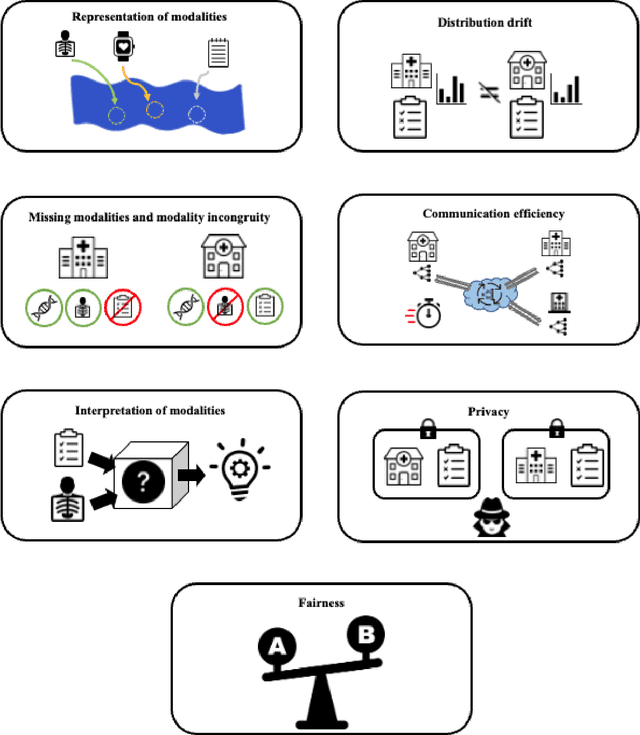
Machine learning (ML) in healthcare presents numerous opportunities for enhancing patient care, population health, and healthcare providers' workflows. However, the real-world clinical and cost benefits remain limited due to challenges in data privacy, heterogeneous data sources, and the inability to fully leverage multiple data modalities. In this perspective paper, we introduce "patchwork learning" (PL), a novel paradigm that addresses these limitations by integrating information from disparate datasets composed of different data modalities (e.g., clinical free-text, medical images, omics) and distributed across separate and secure sites. PL allows the simultaneous utilization of complementary data sources while preserving data privacy, enabling the development of more holistic and generalizable ML models. We present the concept of patchwork learning and its current implementations in healthcare, exploring the potential opportunities and applicable data sources for addressing various healthcare challenges. PL leverages bridging modalities or overlapping feature spaces across sites to facilitate information sharing and impute missing data, thereby addressing related prediction tasks. We discuss the challenges associated with PL, many of which are shared by federated and multimodal learning, and provide recommendations for future research in this field. By offering a more comprehensive approach to healthcare data integration, patchwork learning has the potential to revolutionize the clinical applicability of ML models. This paradigm promises to strike a balance between personalization and generalizability, ultimately enhancing patient experiences, improving population health, and optimizing healthcare providers' workflows.