 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeliberate Evolution: Agentic Reasoning for Sample-Efficient Symbolic Regression with LLMs
Jun 03, 2026Symbolic regression (SR) discovers compact mathematical expressions from data, yet recent LLM-based evolutionary methods remain sample-inefficient because they rely mainly on scalar feedback such as MSE. We identify a core limitation: existing methods conflate candidate proposal with search guidance, requiring the LLM to infer how to evolve an expression, diagnose its errors, and reuse past experience from a single score. To address this, we propose Deliberate Evolution (DE), an agentic framework that decouples symbolic generation from search control. DE guides LLM proposals with adaptive operators for search direction, analytical tools for structural diagnosis, and reflective memory for trajectory-level experience. Experiments on LLM-SRBench show that DE consistently outperforms representative LLM-based SR baselines across diverse scientific domains while using only 40% of the standard sample budget.
Guideline-grounded retrieval-augmented generation for ophthalmic clinical decision support
Mar 23, 2026In this work, we propose Oph-Guid-RAG, a multimodal visual RAG system for ophthalmology clinical question answering and decision support. We treat each guideline page as an independent evidence unit and directly retrieve page images, preserving tables, flowcharts, and layout information. We further design a controllable retrieval framework with routing and filtering, which selectively introduces external evidence and reduces noise. The system integrates query decomposition, query rewriting, retrieval, reranking, and multimodal reasoning, and provides traceable outputs with guideline page references. We evaluate our method on HealthBench using a doctor-based scoring protocol. On the hard subset, our approach improves the overall score from 0.2969 to 0.3861 (+0.0892, +30.0%) compared to GPT-5.2, and achieves higher accuracy, improving from 0.5956 to 0.6576 (+0.0620, +10.4%). Compared to GPT-5.4, our method achieves a larger accuracy gain of +0.1289 (+24.4%). These results show that our method is more effective on challenging cases that require precise, evidence-based reasoning. Ablation studies further show that reranking, routing, and retrieval design are critical for stable performance, especially under difficult settings. Overall, we show how combining visionbased retrieval with controllable reasoning can improve evidence grounding and robustness in clinical AI applications,while pointing out that further work is needed to be more complete.
FATE: Closed-Loop Feasibility-Aware Task Generation with Active Repair for Physically Grounded Robotic Curricula
Mar 02, 2026Recent breakthroughs in generative simulation have harnessed Large Language Models (LLMs) to generate diverse robotic task curricula, yet these open-loop paradigms frequently produce linguistically coherent but physically infeasible goals, stemming from ungrounded task specifications or misaligned objective formulations. To address this critical limitation, we propose FATE (Feasibility-Aware Task gEneration), a closed-loop, self-correcting framework that reimagines task generation as an iterative validation-and-refinement process. Unlike conventional methods that decouple generation and verification into discrete stages, FATE embeds a generalist embodied agent directly into the generation loop to proactively guarantee the physical groundedness of the resulting curriculum. FATE instantiates a sequential auditing pipeline: it first validates static scene attributes (e.g., object affordances, layout compatibility) and subsequently verifies execution feasibility via simulated embodied interaction. Critical to its performance, upon detecting an infeasible task, FATE deploys an active repair module that autonomously adapts scene configurations or policy specifications, converting unworkable proposals into physically valid task instances. Extensive experiments validate that FATE generates semantically diverse, physically grounded task curricula while achieving a substantial reduction in execution failure rates relative to state-of-the-art generative baselines.
Affordance-Graphed Task Worlds: Self-Evolving Task Generation for Scalable Embodied Learning
Feb 12, 2026Training robotic policies directly in the real world is expensive and unscalable. Although generative simulation enables large-scale data synthesis, current approaches often fail to generate logically coherent long-horizon tasks and struggle with dynamic physical uncertainties due to open-loop execution. To address these challenges, we propose Affordance-Graphed Task Worlds (AGT-World), a unified framework that autonomously constructs interactive simulated environments and corresponding robot task policies based on real-world observations. Unlike methods relying on random proposals or static replication, AGT-World formalizes the task space as a structured graph, enabling the precise, hierarchical decomposition of complex goals into theoretically grounded atomic primitives. Furthermore, we introduce a Self-Evolution mechanism with hybrid feedback to autonomously refine policies, combining Vision-Language Model reasoning and geometric verification. Extensive experiments demonstrate that our method significantly outperforms in success rates and generalization, achieving a self-improving cycle of proposal, execution, and correction for scalable robot learning.
Reversible Diffusion Decoding for Diffusion Language Models
Jan 29, 2026Diffusion language models enable parallel token generation through block-wise decoding, but their irreversible commitments can lead to stagnation, where the reverse diffusion process fails to make further progress under a suboptimal context.We propose Reversible Diffusion Decoding (RDD), a decoding framework that introduces reversibility into block-wise diffusion generation. RDD detects stagnation as a state-dependent failure of the reverse process and enables efficient backtracking to earlier blocks without recomputation via cached model states. To avoid repeated failure trajectories, RDD applies confidence-guided re-masking to selectively reinitialize uncertain tokens while preserving reliable context.This reversible formulation allows decoding to recover from early commitment errors while maintaining the parallel efficiency of diffusion-based generation. Experiments show that RDD improves generation robustness and quality over baselines with minimal computational overhead.
Think Consistently, Reason Efficiently: Energy-Based Calibration for Implicit Chain-of-Thought
Nov 10, 2025Large Language Models (LLMs) have demonstrated strong reasoning capabilities through \emph{Chain-of-Thought} (CoT) prompting, which enables step-by-step intermediate reasoning. However, explicit CoT methods rely on discrete token-level reasoning processes that are prone to error propagation and limited by vocabulary expressiveness, often resulting in rigid and inconsistent reasoning trajectories. Recent research has explored implicit or continuous reasoning in latent spaces, allowing models to perform internal reasoning before generating explicit output. Although such approaches alleviate some limitations of discrete CoT, they generally lack explicit mechanisms to enforce consistency among reasoning steps, leading to divergent reasoning paths and unstable outcomes. To address this issue, we propose EBM-CoT, an Energy-Based Chain-of-Thought Calibration framework that refines latent thought representations through an energy-based model (EBM). Our method dynamically adjusts latent reasoning trajectories toward lower-energy, high-consistency regions in the embedding space, improving both reasoning accuracy and consistency without modifying the base language model. Extensive experiments across mathematical, commonsense, and symbolic reasoning benchmarks demonstrate that the proposed framework significantly enhances the consistency and efficiency of multi-step reasoning in LLMs.
CALM: Consensus-Aware Localized Merging for Multi-Task Learning
Jun 16, 2025Model merging aims to integrate the strengths of multiple fine-tuned models into a unified model while preserving task-specific capabilities. Existing methods, represented by task arithmetic, are typically classified into global- and local-aware methods. However, global-aware methods inevitably cause parameter interference, while local-aware methods struggle to maintain the effectiveness of task-specific details in the merged model. To address these limitations, we propose a Consensus-Aware Localized Merging (CALM) method which incorporates localized information aligned with global task consensus, ensuring its effectiveness post-merging. CALM consists of three key components: (1) class-balanced entropy minimization sampling, providing a more flexible and reliable way to leverage unsupervised data; (2) an efficient-aware framework, selecting a small set of tasks for sequential merging with high scalability; (3) a consensus-aware mask optimization, aligning localized binary masks with global task consensus and merging them conflict-free. Experiments demonstrate the superiority and robustness of our CALM, significantly outperforming existing methods and achieving performance close to traditional MTL.
Learning without Isolation: Pathway Protection for Continual Learning
May 24, 2025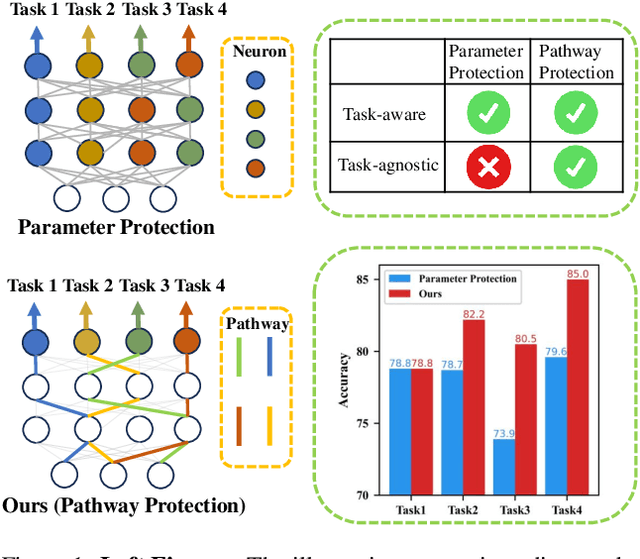
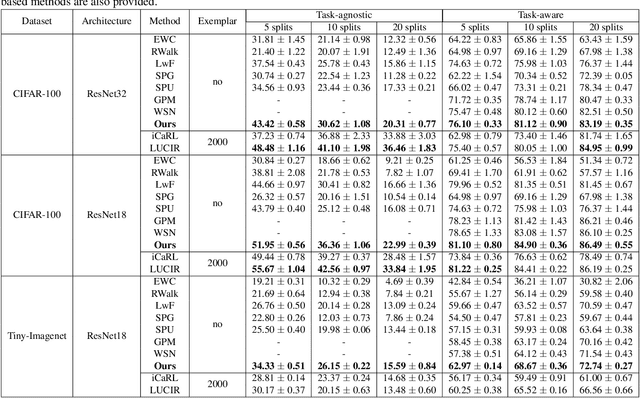
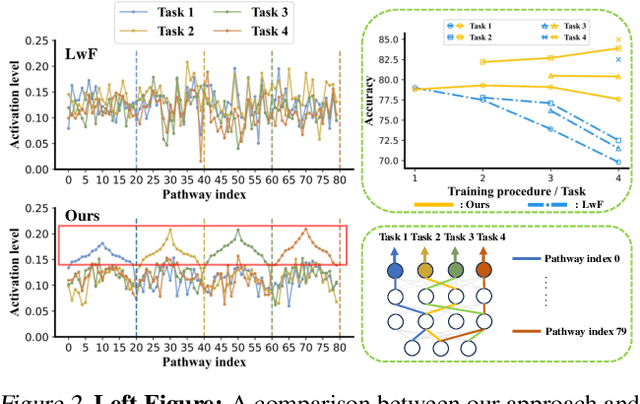
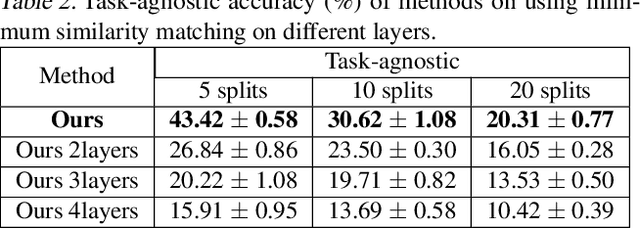
Deep networks are prone to catastrophic forgetting during sequential task learning, i.e., losing the knowledge about old tasks upon learning new tasks. To this end, continual learning(CL) has emerged, whose existing methods focus mostly on regulating or protecting the parameters associated with the previous tasks. However, parameter protection is often impractical, since the size of parameters for storing the old-task knowledge increases linearly with the number of tasks, otherwise it is hard to preserve the parameters related to the old-task knowledge. In this work, we bring a dual opinion from neuroscience and physics to CL: in the whole networks, the pathways matter more than the parameters when concerning the knowledge acquired from the old tasks. Following this opinion, we propose a novel CL framework, learning without isolation(LwI), where model fusion is formulated as graph matching and the pathways occupied by the old tasks are protected without being isolated. Thanks to the sparsity of activation channels in a deep network, LwI can adaptively allocate available pathways for a new task, realizing pathway protection and addressing catastrophic forgetting in a parameter-efficient manner. Experiments on popular benchmark datasets demonstrate the superiority of the proposed LwI.
Accurate Forgetting for Heterogeneous Federated Continual Learning
Feb 20, 2025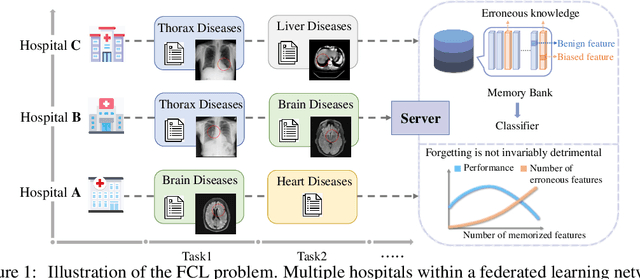
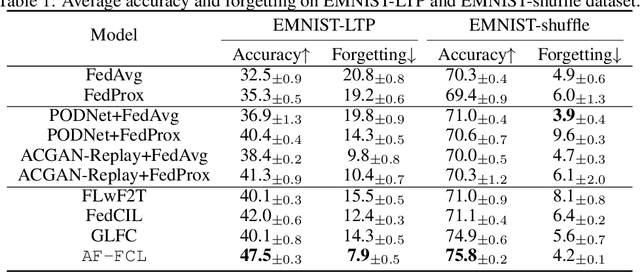
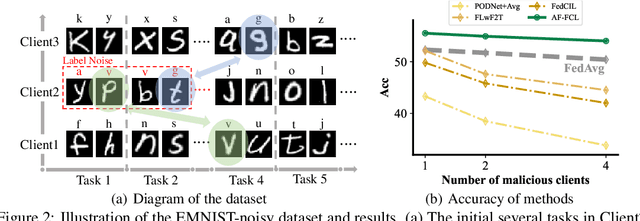
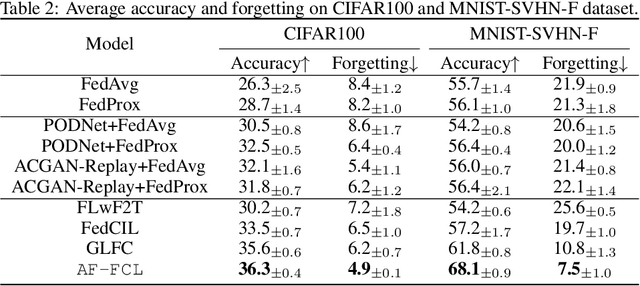
Recent years have witnessed a burgeoning interest in federated learning (FL). However, the contexts in which clients engage in sequential learning remain under-explored. Bridging FL and continual learning (CL) gives rise to a challenging practical problem: federated continual learning (FCL). Existing research in FCL primarily focuses on mitigating the catastrophic forgetting issue of continual learning while collaborating with other clients. We argue that the forgetting phenomena are not invariably detrimental. In this paper, we consider a more practical and challenging FCL setting characterized by potentially unrelated or even antagonistic data/tasks across different clients. In the FL scenario, statistical heterogeneity and data noise among clients may exhibit spurious correlations which result in biased feature learning. While existing CL strategies focus on a complete utilization of previous knowledge, we found that forgetting biased information is beneficial in our study. Therefore, we propose a new concept accurate forgetting (AF) and develop a novel generative-replay method~\method~which selectively utilizes previous knowledge in federated networks. We employ a probabilistic framework based on a normalizing flow model to quantify the credibility of previous knowledge. Comprehensive experiments affirm the superiority of our method over baselines.
Beyond Similarity: Personalized Federated Recommendation with Composite Aggregation
Jun 06, 2024Federated recommendation aims to collect global knowledge by aggregating local models from massive devices, to provide recommendations while ensuring privacy. Current methods mainly leverage aggregation functions invented by federated vision community to aggregate parameters from similar clients, e.g., clustering aggregation. Despite considerable performance, we argue that it is suboptimal to apply them to federated recommendation directly. This is mainly reflected in the disparate model architectures. Different from structured parameters like convolutional neural networks in federated vision, federated recommender models usually distinguish itself by employing one-to-one item embedding table. Such a discrepancy induces the challenging embedding skew issue, which continually updates the trained embeddings but ignores the non-trained ones during aggregation, thus failing to predict future items accurately. To this end, we propose a personalized Federated recommendation model with Composite Aggregation (FedCA), which not only aggregates similar clients to enhance trained embeddings, but also aggregates complementary clients to update non-trained embeddings. Besides, we formulate the overall learning process into a unified optimization algorithm to jointly learn the similarity and complementarity. Extensive experiments on several real-world datasets substantiate the effectiveness of our proposed model. The source codes are available at https://github.com/hongleizhang/FedCA.