 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALM: Consensus-Aware Localized Merging for Multi-Task Learning
Jun 16, 2025Model merging aims to integrate the strengths of multiple fine-tuned models into a unified model while preserving task-specific capabilities. Existing methods, represented by task arithmetic, are typically classified into global- and local-aware methods. However, global-aware methods inevitably cause parameter interference, while local-aware methods struggle to maintain the effectiveness of task-specific details in the merged model. To address these limitations, we propose a Consensus-Aware Localized Merging (CALM) method which incorporates localized information aligned with global task consensus, ensuring its effectiveness post-merging. CALM consists of three key components: (1) class-balanced entropy minimization sampling, providing a more flexible and reliable way to leverage unsupervised data; (2) an efficient-aware framework, selecting a small set of tasks for sequential merging with high scalability; (3) a consensus-aware mask optimization, aligning localized binary masks with global task consensus and merging them conflict-free. Experiments demonstrate the superiority and robustness of our CALM, significantly outperforming existing methods and achieving performance close to traditional MTL.
Accurate Forgetting for Heterogeneous Federated Continual Learning
Feb 20, 2025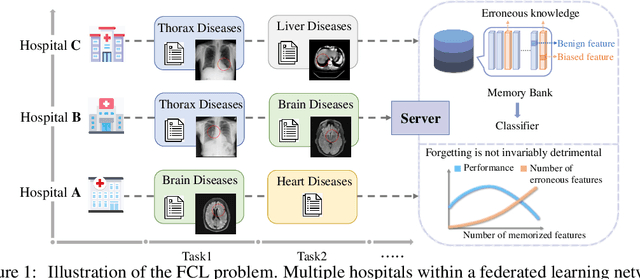
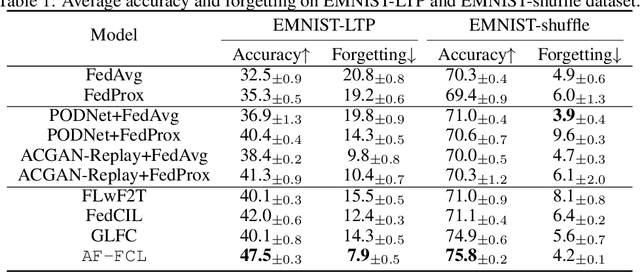
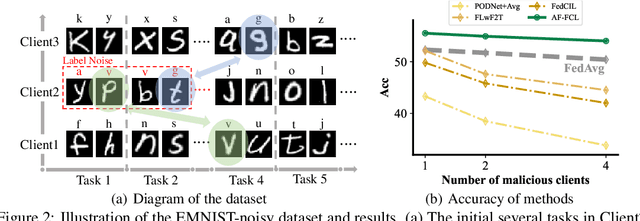
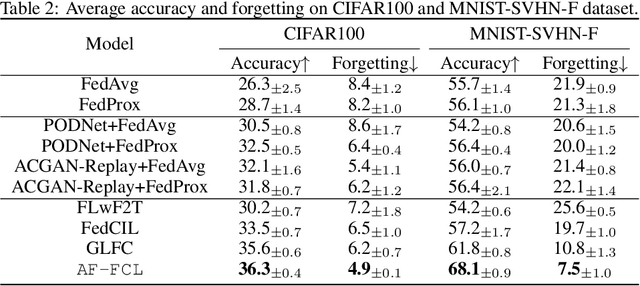
Recent years have witnessed a burgeoning interest in federated learning (FL). However, the contexts in which clients engage in sequential learning remain under-explored. Bridging FL and continual learning (CL) gives rise to a challenging practical problem: federated continual learning (FCL). Existing research in FCL primarily focuses on mitigating the catastrophic forgetting issue of continual learning while collaborating with other clients. We argue that the forgetting phenomena are not invariably detrimental. In this paper, we consider a more practical and challenging FCL setting characterized by potentially unrelated or even antagonistic data/tasks across different clients. In the FL scenario, statistical heterogeneity and data noise among clients may exhibit spurious correlations which result in biased feature learning. While existing CL strategies focus on a complete utilization of previous knowledge, we found that forgetting biased information is beneficial in our study. Therefore, we propose a new concept accurate forgetting (AF) and develop a novel generative-replay method~\method~which selectively utilizes previous knowledge in federated networks. We employ a probabilistic framework based on a normalizing flow model to quantify the credibility of previous knowledge. Comprehensive experiments affirm the superiority of our method over baselines.
Beyond Similarity: Personalized Federated Recommendation with Composite Aggregation
Jun 06, 2024Federated recommendation aims to collect global knowledge by aggregating local models from massive devices, to provide recommendations while ensuring privacy. Current methods mainly leverage aggregation functions invented by federated vision community to aggregate parameters from similar clients, e.g., clustering aggregation. Despite considerable performance, we argue that it is suboptimal to apply them to federated recommendation directly. This is mainly reflected in the disparate model architectures. Different from structured parameters like convolutional neural networks in federated vision, federated recommender models usually distinguish itself by employing one-to-one item embedding table. Such a discrepancy induces the challenging embedding skew issue, which continually updates the trained embeddings but ignores the non-trained ones during aggregation, thus failing to predict future items accurately. To this end, we propose a personalized Federated recommendation model with Composite Aggregation (FedCA), which not only aggregates similar clients to enhance trained embeddings, but also aggregates complementary clients to update non-trained embeddings. Besides, we formulate the overall learning process into a unified optimization algorithm to jointly learn the similarity and complementarity. Extensive experiments on several real-world datasets substantiate the effectiveness of our proposed model. The source codes are available at https://github.com/hongleizhang/FedCA.
Balancing Similarity and Complementarity for Federated Learning
May 16, 2024



In mobile and IoT systems, Federated Learning (FL) is increasingly important for effectively using data while maintaining user privacy. One key challenge in FL is managing statistical heterogeneity, such as non-i.i.d. data, arising from numerous clients and diverse data sources. This requires strategic cooperation, often with clients having similar characteristics. However, we are interested in a fundamental question: does achieving optimal cooperation necessarily entail cooperating with the most similar clients? Typically, significant model performance improvements are often realized not by partnering with the most similar models, but through leveraging complementary data. Our theoretical and empirical analyses suggest that optimal cooperation is achieved by enhancing complementarity in feature distribution while restricting the disparity in the correlation between features and targets. Accordingly, we introduce a novel framework, \texttt{FedSaC}, which balances similarity and complementarity in FL cooperation. Our framework aims to approximate an optimal cooperation network for each client by optimizing a weighted sum of model similarity and feature complementarity. The strength of \texttt{FedSaC} lies in its adaptability to various levels of data heterogeneity and multimodal scenarios. Our comprehensive unimodal and multimodal experiments demonstrate that \texttt{FedSaC} markedly surpasses other state-of-the-art FL methods.