 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReveal and Release: Iterative LLM Unlearning with Self-generated Data
Sep 18, 2025Large language model (LLM) unlearning has demonstrated effectiveness in removing the influence of undesirable data (also known as forget data). Existing approaches typically assume full access to the forget dataset, overlooking two key challenges: (1) Forget data is often privacy-sensitive, rare, or legally regulated, making it expensive or impractical to obtain (2) The distribution of available forget data may not align with how that information is represented within the model. To address these limitations, we propose a ``Reveal-and-Release'' method to unlearn with self-generated data, where we prompt the model to reveal what it knows using optimized instructions. To fully utilize the self-generated forget data, we propose an iterative unlearning framework, where we make incremental adjustments to the model's weight space with parameter-efficient modules trained on the forget data. Experimental results demonstrate that our method balances the tradeoff between forget quality and utility preservation.
Diffusion Cocktail: Fused Generation from Diffusion Models
Dec 12, 2023Diffusion models excel at generating high-quality images and are easy to extend, making them extremely popular among active users who have created an extensive collection of diffusion models with various styles by fine-tuning base models such as Stable Diffusion. Recent work has focused on uncovering semantic and visual information encoded in various components of a diffusion model, enabling better generation quality and more fine-grained control. However, those methods target improving a single model and overlook the vastly available collection of fine-tuned diffusion models. In this work, we study the combinations of diffusion models. We propose Diffusion Cocktail (Ditail), a training-free method that can accurately transfer content information between two diffusion models. This allows us to perform diverse generations using a set of diffusion models, resulting in novel images that are unlikely to be obtained by a single model alone. We also explore utilizing Ditail for style transfer, with the target style set by a diffusion model instead of an image. Ditail offers a more detailed manipulation of the diffusion generation, thereby enabling the vast community to integrate various styles and contents seamlessly and generate any content of any style.
Towards Personalized Prompt-Model Retrieval for Generative Recommendation
Aug 04, 2023Recommender Systems are built to retrieve relevant items to satisfy users' information needs. The candidate corpus usually consists of a finite set of items that are ready to be served, such as videos, products, or articles. With recent advances in Generative AI such as GPT and Diffusion models, a new form of recommendation task is yet to be explored where items are to be created by generative models with personalized prompts. Taking image generation as an example, with a single prompt from the user and access to a generative model, it is possible to generate hundreds of new images in a few minutes. How shall we attain personalization in the presence of "infinite" items? In this preliminary study, we propose a two-stage framework, namely Prompt-Model Retrieval and Generated Item Ranking, to approach this new task formulation. We release GEMRec-18K, a prompt-model interaction dataset with 18K images generated by 200 publicly-available generative models paired with a diverse set of 90 textual prompts. Our findings demonstrate the promise of generative model recommendation as a novel personalization problem and the limitations of existing evaluation metrics. We highlight future directions for the RecSys community to advance towards generative recommender systems. Our code and dataset are available at https://github.com/MAPS-research/GEMRec.
Evaluating Music Recommendations with Binary Feedback for Multiple Stakeholders
Sep 16, 2021


High quality user feedback data is essential to training and evaluating a successful music recommendation system, particularly one that has to balance the needs of multiple stakeholders. Most existing music datasets suffer from noisy feedback and self-selection biases inherent in the data collected by music platforms. Using the Piki Music dataset of 500k ratings collected over a two-year time period, we evaluate the performance of classic recommendation algorithms on three important stakeholders: consumers, well-known artists and lesser-known artists. We show that a matrix factorization algorithm trained on both likes and dislikes performs significantly better compared to one trained only on likes for all three stakeholders.
Correcting the User Feedback-Loop Bias for Recommendation Systems
Sep 13, 2021

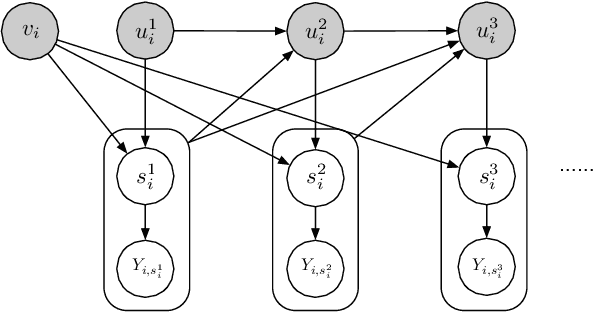
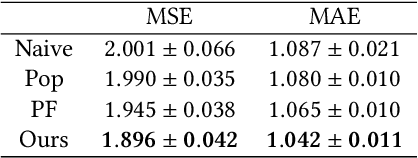
Selection bias is prevalent in the data for training and evaluating recommendation systems with explicit feedback. For example, users tend to rate items they like. However, when rating an item concerning a specific user, most of the recommendation algorithms tend to rely too much on his/her rating (feedback) history. This introduces implicit bias on the recommendation system, which is referred to as user feedback-loop bias in this paper. We propose a systematic and dynamic way to correct such bias and to obtain more diverse and objective recommendations by utilizing temporal rating information. Specifically, our method includes a deep-learning component to learn each user's dynamic rating history embedding for the estimation of the probability distribution of the items that the user rates sequentially. These estimated dynamic exposure probabilities are then used as propensity scores to train an inverse-propensity-scoring (IPS) rating predictor. We empirically validated the existence of such user feedback-loop bias in real world recommendation systems and compared the performance of our method with the baseline models that are either without de-biasing or with propensity scores estimated by other methods. The results show the superiority of our approach.
Revisiting Adversarially Learned Injection Attacks Against Recommender Systems
Aug 28, 2020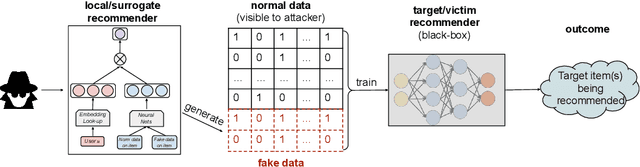

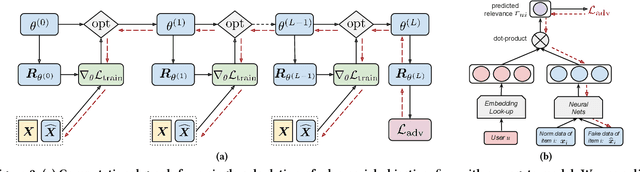

Recommender systems play an important role in modern information and e-commerce applications. While increasing research is dedicated to improving the relevance and diversity of the recommendations, the potential risks of state-of-the-art recommendation models are under-explored, that is, these models could be subject to attacks from malicious third parties, through injecting fake user interactions to achieve their purposes. This paper revisits the adversarially-learned injection attack problem, where the injected fake user `behaviors' are learned locally by the attackers with their own model -- one that is potentially different from the model under attack, but shares similar properties to allow attack transfer. We found that most existing works in literature suffer from two major limitations: (1) they do not solve the optimization problem precisely, making the attack less harmful than it could be, (2) they assume perfect knowledge for the attack, causing the lack of understanding for realistic attack capabilities. We demonstrate that the exact solution for generating fake users as an optimization problem could lead to a much larger impact. Our experiments on a real-world dataset reveal important properties of the attack, including attack transferability and its limitations. These findings can inspire useful defensive methods against this possible existing attack.