 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth Multi-Policy Causal Effect Estimation in Longitudinal Settings
May 14, 2026Comparative evaluation of multiple dynamic treatment policies is essential for healthcare and policy decisions, yet conventional longitudinal causal inference methods estimate each in isolation, preventing information sharing across counterfactuals. We demonstrate that this separate estimation paradigm induces a structurally uncontrolled second-order bias, inflating finite-sample variance even after standard debiasing with longitudinal targeted maximum likelihood estimation(LTMLE). To address this, we propose a policy-aware reparameterization of Iterative Conditional Expectation (ICE) Q-functions that enables joint estimation through shared representations. We implement this approach in the Policy-Encoded Q Network (PEQ-Net), an architecture centered on a shared policy encoder. The encoder is trained using kernel mean embeddings, ensuring that the learned representation space reflects population-level policy dissimilarities. After applying an LTMLE correction step, we prove this design imposes a structural constraint on the second-order remainder, thereby stabilizing finite-sample variance. Experiments on semi-synthetic datasets demonstrate that PEQ-Net consistently outperforms existing ICE-based methods, achieving substantial reductions in root-mean-square error, particularly when evaluating closely related policies.
Deep Doubly Debiased Longitudinal Effect Estimation with ICE G-Computation
Feb 12, 2026Estimating longitudinal treatment effects is essential for sequential decision-making but is challenging due to treatment-confounder feedback. While Iterative Conditional Expectation (ICE) G-computation offers a principled approach, its recursive structure suffers from error propagation, corrupting the learned outcome regression models. We propose D3-Net, a framework that mitigates error propagation in ICE training and then applies a robust final correction. First, to interrupt error propagation during learning, we train the ICE sequence using Sequential Doubly Robust (SDR) pseudo-outcomes, which provide bias-corrected targets for each regression. Second, we employ a multi-task Transformer with a covariate simulator head for auxiliary supervision, regularizing representations against corruption by noisy pseudo-outcomes, and a target network to stabilize training dynamics. For the final estimate, we discard the SDR correction and instead use the uncorrected nuisance models to perform Longitudinal Targeted Minimum Loss-Based Estimation (LTMLE) on the original outcomes. This second-stage, targeted debiasing ensures robustness and optimal finite-sample properties. Comprehensive experiments demonstrate that our model, D3-Net, robustly reduces bias and variance across different horizons, counterfactuals, and time-varying confoundings, compared to existing state-of-the-art ICE-based estimators.
MOSIC: Model-Agnostic Optimal Subgroup Identification with Multi-Constraint for Improved Reliability
Apr 29, 2025
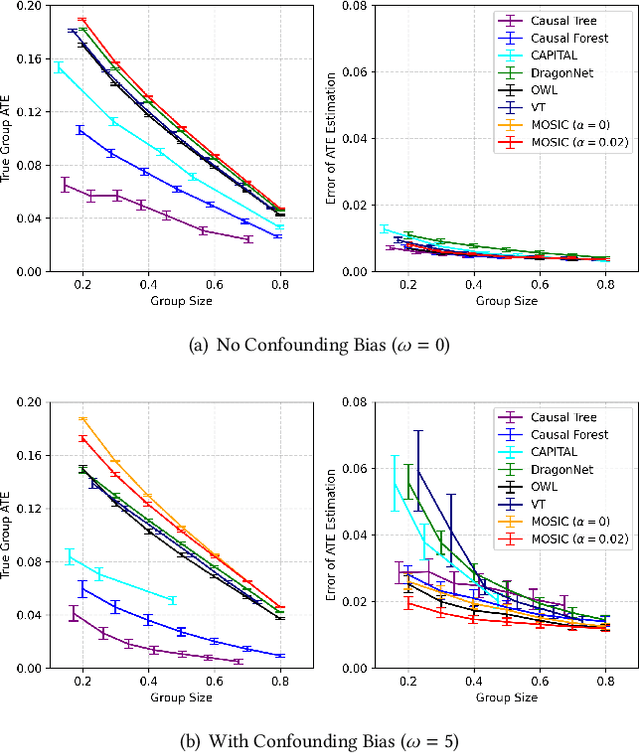


Identifying subgroups that benefit from specific treatments using observational data is a critical challenge in personalized medicine. Most existing approaches solely focus on identifying a subgroup with an improved treatment effect. However, practical considerations, such as ensuring a minimum subgroup size for representativeness or achieving sufficient confounder balance for reliability, are also important for making findings clinically meaningful and actionable. While some studies address these constraints individually, none offer a unified approach to handle them simultaneously. To bridge this gap, we propose a model-agnostic framework for optimal subgroup identification under multiple constraints. We reformulate this combinatorial problem as an unconstrained min-max optimization problem with novel modifications and solve it by a gradient descent ascent algorithm. We further prove its convergence to a feasible and locally optimal solution. Our method is stable and highly flexible, supporting various models and techniques for estimating and optimizing treatment effectiveness with observational data. Extensive experiments on both synthetic and real-world datasets demonstrate its effectiveness in identifying subgroups that satisfy multiple constraints, achieving higher treatment effects and better confounder balancing results across different group sizes.
3DResT: A Strong Baseline for Semi-Supervised 3D Referring Expression Segmentation
Apr 17, 20253D Referring Expression Segmentation (3D-RES) typically requires extensive instance-level annotations, which are time-consuming and costly. Semi-supervised learning (SSL) mitigates this by using limited labeled data alongside abundant unlabeled data, improving performance while reducing annotation costs. SSL uses a teacher-student paradigm where teacher generates high-confidence-filtered pseudo-labels to guide student. However, in the context of 3D-RES, where each label corresponds to a single mask and labeled data is scarce, existing SSL methods treat high-quality pseudo-labels merely as auxiliary supervision, which limits the model's learning potential. The reliance on high-confidence thresholds for filtering often results in potentially valuable pseudo-labels being discarded, restricting the model's ability to leverage the abundant unlabeled data. Therefore, we identify two critical challenges in semi-supervised 3D-RES, namely, inefficient utilization of high-quality pseudo-labels and wastage of useful information from low-quality pseudo-labels. In this paper, we introduce the first semi-supervised learning framework for 3D-RES, presenting a robust baseline method named 3DResT. To address these challenges, we propose two novel designs called Teacher-Student Consistency-Based Sampling (TSCS) and Quality-Driven Dynamic Weighting (QDW). TSCS aids in the selection of high-quality pseudo-labels, integrating them into the labeled dataset to strengthen the labeled supervision signals. QDW preserves low-quality pseudo-labels by dynamically assigning them lower weights, allowing for the effective extraction of useful information rather than discarding them. Extensive experiments conducted on the widely used benchmark demonstrate the effectiveness of our method. Notably, with only 1% labeled data, 3DResT achieves an mIoU improvement of 8.34 points compared to the fully supervised method.
MobiFuse: A High-Precision On-device Depth Perception System with Multi-Data Fusion
Dec 18, 2024



We present MobiFuse, a high-precision depth perception system on mobile devices that combines dual RGB and Time-of-Flight (ToF) cameras. To achieve this, we leverage physical principles from various environmental factors to propose the Depth Error Indication (DEI) modality, characterizing the depth error of ToF and stereo-matching. Furthermore, we employ a progressive fusion strategy, merging geometric features from ToF and stereo depth maps with depth error features from the DEI modality to create precise depth maps. Additionally, we create a new ToF-Stereo depth dataset, RealToF, to train and validate our model. Our experiments demonstrate that MobiFuse excels over baselines by significantly reducing depth measurement errors by up to 77.7%. It also showcases strong generalization across diverse datasets and proves effectiveness in two downstream tasks: 3D reconstruction and 3D segmentation. The demo video of MobiFuse in real-life scenarios is available at the de-identified YouTube link(https://youtu.be/jy-Sp7T1LVs).
Automatic marker-free registration based on similar tetrahedras for single-tree point clouds
Nov 20, 2024



In recent years, terrestrial laser scanning technology has been widely used to collect tree point cloud data, aiding in measurements of diameter at breast height, biomass, and other forestry survey data. Since a single scan from terrestrial laser systems captures data from only one angle, multiple scans must be registered and fused to obtain complete tree point cloud data. This paper proposes a marker-free automatic registration method for single-tree point clouds based on similar tetrahedras. First, two point clouds from two scans of the same tree are used to generate tree skeletons, and key point sets are constructed from these skeletons. Tetrahedra are then filtered and matched according to similarity principles, with the vertices of these two matched tetrahedras selected as matching point pairs, thus completing the coarse registration of the point clouds from the two scans. Subsequently, the ICP method is applied to the coarse-registered leaf point clouds to obtain fine registration parameters, completing the precise registration of the two tree point clouds. Experiments were conducted using terrestrial laser scanning data from eight trees, each from different species and with varying shapes. The proposed method was evaluated using RMSE and Hausdorff distance, compared against the traditional ICP and NDT methods. The experimental results demonstrate that the proposed method significantly outperforms both ICP and NDT in registration accuracy, achieving speeds up to 593 times and 113 times faster than ICP and NDT, respectively. In summary, the proposed method shows good robustness in single-tree point cloud registration, with significant advantages in accuracy and speed compared to traditional ICP and NDT methods, indicating excellent application prospects in practical registration scenarios.
WLC-Net: a robust and fast deep-learning wood-leaf classification method
May 29, 2024



Wood-leaf classification is an essential and fundamental prerequisite in the analysis and estimation of forest attributes from terrestrial laser scanning (TLS) point clouds,including critical measurements such as diameter at breast height(DBH),above-ground biomass(AGB),wood volume.To address this,we introduce the Wood-Leaf Classification Network(WLC-Net),a deep learning model derived from PointNet++,designed to differentiate between wood and leaf points within tree point clouds.WLC-Net enhances classification accuracy,completeness,and speed by incorporating linearity as an inherent feature,refining the input-output framework,and optimizing the centroid sampling technique.WLC-Net was trained and assessed using three distinct tree species datasets,comprising a total of 102 individual tree point clouds:21 Chinese ash trees,21 willow trees,and 60 tropical trees.For comparative evaluation,five alternative methods,including PointNet++,DGCNN,Krishna Moorthy's method,LeWoS, and Sun's method,were also applied to these datasets.The classification accuracy of all six methods was quantified using three metrics:overall accuracy(OA),mean Intersection over Union(mIoU),and F1-score.Across all three datasets,WLC-Net demonstrated superior performance, achieving OA scores of 0.9778, 0.9712, and 0.9508;mIoU scores of 0.9761, 0.9693,and 0.9141;and F1-scores of 0.8628, 0.7938,and 0.9019,respectively.The time costs of WLC-Net were also recorded to evaluate the efficiency.The average processing time was 102.74s per million points for WLC-Net.In terms of visual inspect,accuracy evaluation and efficiency evaluation,the results suggest that WLC-Net presents a promising approach for wood-leaf classification,distinguished by its high accuracy. In addition,WLC-Net also exhibits strong applicability across various tree point clouds and holds promise for further optimization.
Action Concept Grounding Network for Semantically-Consistent Video Generation
Nov 23, 2020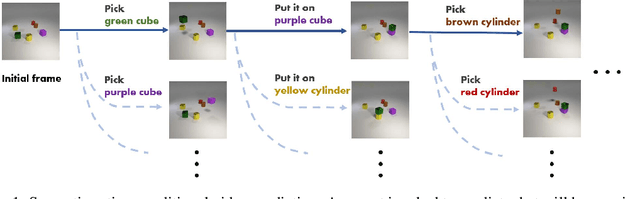
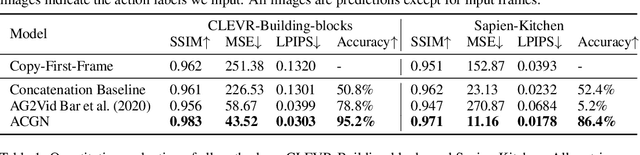
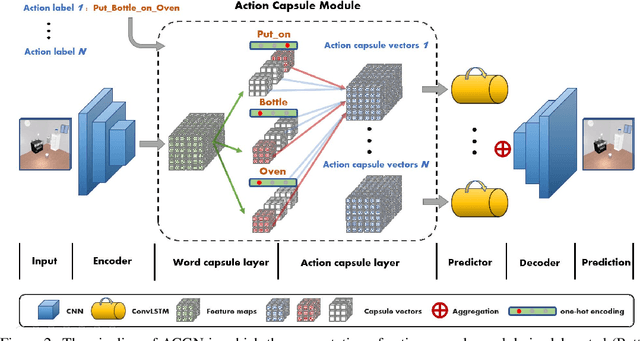

Recent works in self-supervised video prediction have mainly focused on passive forecasting and low-level action-conditional prediction, which sidesteps the problem of semantic learning. We introduce the task of semantic action-conditional video prediction, which can be regarded as an inverse problem of action recognition. The challenge of this new task primarily lies in how to effectively inform the model of semantic action information. To bridge vision and language, we utilize the idea of capsule and propose a novel video prediction model Action Concept Grounding Network (AGCN). Our method is evaluated on two newly designed synthetic datasets, CLEVR-Building-Blocks and Sapien-Kitchen, and experiments show that given different action labels, our ACGN can correctly condition on instructions and generate corresponding future frames without need of bounding boxes. We further demonstrate our trained model can make out-of-distribution predictions for concurrent actions, be quickly adapted to new object categories and exploit its learnt features for object detection. Additional visualizations can be found at https://iclr-acgn.github.io/ACGN/.