 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeCtrl: Region-Aware Safety Control for Text-to-Image Diffusion via Detect-Then-Suppress
Apr 05, 2026The widespread deployment of text-to-image diffusion models is significantly challenged by the generation of visually harmful content, such as sexually explicit content, violence, and horror imagery. Common safety interventions, ranging from input filtering to model concept erasure, often suffer from two critical limitations: (1) a severe trade-off between safety and context preservation, where removing unsafe concepts degrades the fidelity of the safe content, and (2) vulnerability to adversarial attacks, where safety mechanisms are easily bypassed. To address these challenges, we propose SafeCtrl, a Region-Aware safety control framework operating on a Detect-Then-Suppress paradigm. Unlike global safety interventions, SafeCtrl first employs an attention-guided Detect module to precisely localize specific risk regions. Subsequently, a localized Suppress module, optimized via image-level Direct Preference Optimization (DPO), neutralizes harmful semantics only within the detected areas, effectively transforming unsafe objects into safe alternatives while leaving the surrounding context intact. Extensive experiments across multiple risk categories demonstrate that SafeCtrl achieves a superior trade-off between safety and fidelity compared to state-of-the-art methods. Crucially, our approach exhibits improved resilience against adversarial prompt attacks, offering a precise and robust solution for responsible generation.
IdentityGuard: Context-Aware Restriction and Provenance for Personalized Synthesis
Mar 14, 2026The nature of personalized text-to-image models poses a unique safety challenge that generic context-blind methods are ill-equipped to handle. Such global filters create a dilemma: to prevent misuse, they are forced to damage the model's broader utility by erasing concepts entirely, causing unacceptable collateral damage.Our work presents a more precisely targeted approach, built on the principle that security should be as context-aware as the threat itself, intrinsically bound to the personalized concept. We present IDENTITYGUARD, which realizes this principle through a conditional restriction that blocks harmful content only when combined with the personalized identity, and a concept-specific watermark for precise traceability. Experiments show our approach prevents misuse while preserving the model's utility and enabling robust traceability. By moving beyond blunt, global filters, our work demonstrates a more effective and responsible path toward AI safety.
Concept Replacer: Replacing Sensitive Concepts in Diffusion Models via Precision Localization
Dec 03, 2024As large-scale diffusion models continue to advance, they excel at producing high-quality images but often generate unwanted content, such as sexually explicit or violent content. Existing methods for concept removal generally guide the image generation process but can unintentionally modify unrelated regions, leading to inconsistencies with the original model. We propose a novel approach for targeted concept replacing in diffusion models, enabling specific concepts to be removed without affecting non-target areas. Our method introduces a dedicated concept localizer for precisely identifying the target concept during the denoising process, trained with few-shot learning to require minimal labeled data. Within the identified region, we introduce a training-free Dual Prompts Cross-Attention (DPCA) module to substitute the target concept, ensuring minimal disruption to surrounding content. We evaluate our method on concept localization precision and replacement efficiency. Experimental results demonstrate that our method achieves superior precision in localizing target concepts and performs coherent concept replacement with minimal impact on non-target areas, outperforming existing approaches.
Automatic marker-free registration based on similar tetrahedras for single-tree point clouds
Nov 20, 2024



In recent years, terrestrial laser scanning technology has been widely used to collect tree point cloud data, aiding in measurements of diameter at breast height, biomass, and other forestry survey data. Since a single scan from terrestrial laser systems captures data from only one angle, multiple scans must be registered and fused to obtain complete tree point cloud data. This paper proposes a marker-free automatic registration method for single-tree point clouds based on similar tetrahedras. First, two point clouds from two scans of the same tree are used to generate tree skeletons, and key point sets are constructed from these skeletons. Tetrahedra are then filtered and matched according to similarity principles, with the vertices of these two matched tetrahedras selected as matching point pairs, thus completing the coarse registration of the point clouds from the two scans. Subsequently, the ICP method is applied to the coarse-registered leaf point clouds to obtain fine registration parameters, completing the precise registration of the two tree point clouds. Experiments were conducted using terrestrial laser scanning data from eight trees, each from different species and with varying shapes. The proposed method was evaluated using RMSE and Hausdorff distance, compared against the traditional ICP and NDT methods. The experimental results demonstrate that the proposed method significantly outperforms both ICP and NDT in registration accuracy, achieving speeds up to 593 times and 113 times faster than ICP and NDT, respectively. In summary, the proposed method shows good robustness in single-tree point cloud registration, with significant advantages in accuracy and speed compared to traditional ICP and NDT methods, indicating excellent application prospects in practical registration scenarios.
HARE: HumAn pRiors, a key to small language model Efficiency
Jun 18, 2024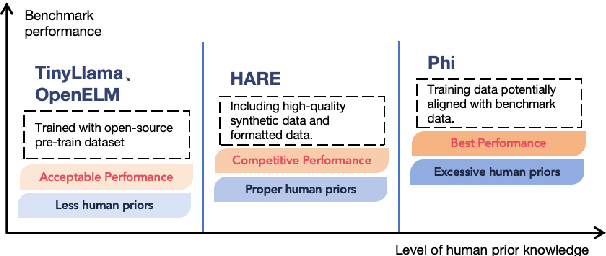
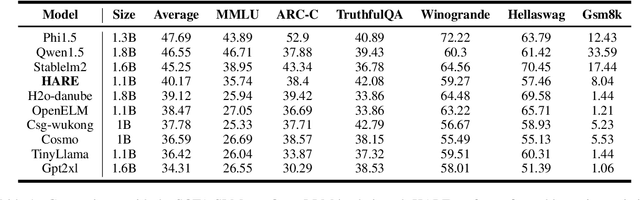
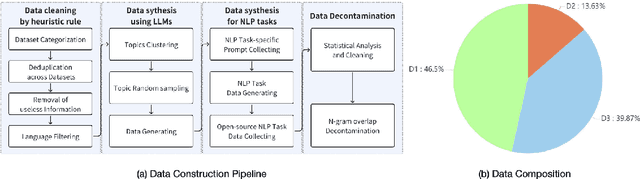
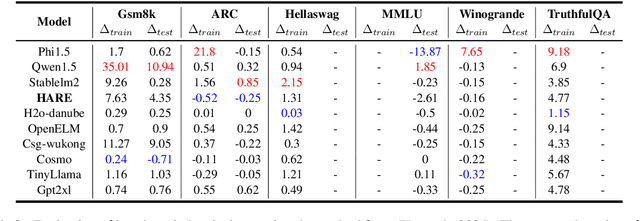
Human priors play a crucial role in efficiently utilizing data in deep learning. However, with the development of large language models (LLMs), there is an increasing emphasis on scaling both model size and data volume, which often diminishes the importance of human priors in data construction. Influenced by these trends, existing Small Language Models (SLMs) mainly rely on web-scraped large-scale training data, neglecting the proper incorporation of human priors. This oversight limits the training efficiency of language models in resource-constrained settings. In this paper, we propose a principle to leverage human priors for data construction. This principle emphasizes achieving high-performance SLMs by training on a concise dataset that accommodates both semantic diversity and data quality consistency, while avoiding benchmark data leakage. Following this principle, we train an SLM named HARE-1.1B. Extensive experiments on large-scale benchmark datasets demonstrate that HARE-1.1B performs favorably against state-of-the-art SLMs, validating the effectiveness of the proposed principle. Additionally, this provides new insights into efficient language model training in resource-constrained environments from the view of human priors.
WLC-Net: a robust and fast deep-learning wood-leaf classification method
May 29, 2024



Wood-leaf classification is an essential and fundamental prerequisite in the analysis and estimation of forest attributes from terrestrial laser scanning (TLS) point clouds,including critical measurements such as diameter at breast height(DBH),above-ground biomass(AGB),wood volume.To address this,we introduce the Wood-Leaf Classification Network(WLC-Net),a deep learning model derived from PointNet++,designed to differentiate between wood and leaf points within tree point clouds.WLC-Net enhances classification accuracy,completeness,and speed by incorporating linearity as an inherent feature,refining the input-output framework,and optimizing the centroid sampling technique.WLC-Net was trained and assessed using three distinct tree species datasets,comprising a total of 102 individual tree point clouds:21 Chinese ash trees,21 willow trees,and 60 tropical trees.For comparative evaluation,five alternative methods,including PointNet++,DGCNN,Krishna Moorthy's method,LeWoS, and Sun's method,were also applied to these datasets.The classification accuracy of all six methods was quantified using three metrics:overall accuracy(OA),mean Intersection over Union(mIoU),and F1-score.Across all three datasets,WLC-Net demonstrated superior performance, achieving OA scores of 0.9778, 0.9712, and 0.9508;mIoU scores of 0.9761, 0.9693,and 0.9141;and F1-scores of 0.8628, 0.7938,and 0.9019,respectively.The time costs of WLC-Net were also recorded to evaluate the efficiency.The average processing time was 102.74s per million points for WLC-Net.In terms of visual inspect,accuracy evaluation and efficiency evaluation,the results suggest that WLC-Net presents a promising approach for wood-leaf classification,distinguished by its high accuracy. In addition,WLC-Net also exhibits strong applicability across various tree point clouds and holds promise for further optimization.