 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Linear Speedup for Composite Federated Learning
Feb 03, 2026This paper proposes FedNMap, a normal map-based method for composite federated learning, where the objective consists of a smooth loss and a possibly nonsmooth regularizer. FedNMap leverages a normal map-based update scheme to handle the nonsmooth term and incorporates a local correction strategy to mitigate the impact of data heterogeneity across clients. Under standard assumptions, including smooth local losses, weak convexity of the regularizer, and bounded stochastic gradient variance, FedNMap achieves linear speedup with respect to both the number of clients $n$ and the number of local updates $Q$ for nonconvex losses, both with and without the Polyak-Łojasiewicz (PL) condition. To our knowledge, this is the first result establishing linear speedup for nonconvex composite federated learning.
Accelerating Decentralized Optimization via Overlapping Local Steps
Jan 04, 2026Decentralized optimization has emerged as a critical paradigm for distributed learning, enabling scalable training while preserving data privacy through peer-to-peer collaboration. However, existing methods often suffer from communication bottlenecks due to frequent synchronization between nodes. We present Overlapping Local Decentralized SGD (OLDSGD), a novel approach to accelerate decentralized training by computation-communication overlapping, significantly reducing network idle time. With a deliberately designed update, OLDSGD preserves the same average update as Local SGD while avoiding communication-induced stalls. Theoretically, we establish non-asymptotic convergence rates for smooth non-convex objectives, showing that OLDSGD retains the same iteration complexity as standard Local Decentralized SGD while improving per-iteration runtime. Empirical results demonstrate OLDSGD's consistent improvements in wall-clock time convergence under different levels of communication delays. With minimal modifications to existing frameworks, OLDSGD offers a practical solution for faster decentralized learning without sacrificing theoretical guarantees.
FedSUM Family: Efficient Federated Learning Methods under Arbitrary Client Participation
Dec 20, 2025Federated Learning (FL) methods are often designed for specific client participation patterns, limiting their applicability in practical deployments. We introduce the FedSUM family of algorithms, which supports arbitrary client participation without additional assumptions on data heterogeneity. Our framework models participation variability with two delay metrics, the maximum delay $τ_{\max}$ and the average delay $τ_{\text{avg}}$. The FedSUM family comprises three variants: FedSUM-B (basic version), FedSUM (standard version), and FedSUM-CR (communication-reduced version). We provide unified convergence guarantees demonstrating the effectiveness of our approach across diverse participation patterns, thereby broadening the applicability of FL in real-world scenarios.
Asynchronous Decentralized SGD under Non-Convexity: A Block-Coordinate Descent Framework
May 15, 2025Decentralized optimization has become vital for leveraging distributed data without central control, enhancing scalability and privacy. However, practical deployments face fundamental challenges due to heterogeneous computation speeds and unpredictable communication delays. This paper introduces a refined model of Asynchronous Decentralized Stochastic Gradient Descent (ADSGD) under practical assumptions of bounded computation and communication times. To understand the convergence of ADSGD, we first analyze Asynchronous Stochastic Block Coordinate Descent (ASBCD) as a tool, and then show that ADSGD converges under computation-delay-independent step sizes. The convergence result is established without assuming bounded data heterogeneity. Empirical experiments reveal that ADSGD outperforms existing methods in wall-clock convergence time across various scenarios. With its simplicity, efficiency in memory and communication, and resilience to communication and computation delays, ADSGD is well-suited for real-world decentralized learning tasks.
Distributed Learning over Arbitrary Topology: Linear Speed-Up with Polynomial Transient Time
Mar 20, 2025

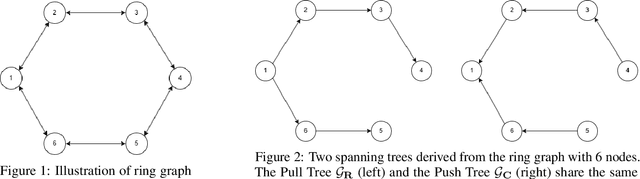

We study a distributed learning problem in which $n$ agents, each with potentially heterogeneous local data, collaboratively minimize the sum of their local cost functions via peer-to-peer communication. We propose a novel algorithm, Spanning Tree Push-Pull (STPP), which employs two spanning trees extracted from a general communication graph to distribute both model parameters and stochastic gradients. Unlike prior approaches that rely heavily on spectral gap properties, STPP leverages a more flexible topological characterization, enabling robust information flow and efficient updates. Theoretically, we prove that STPP achieves linear speedup and polynomial transient iteration complexity, up to $O(n^7)$ for smooth nonconvex objectives and $\tilde{O}(n^3)$ for smooth strongly convex objectives, under arbitrary network topologies. Moreover, compared with the existing methods, STPP achieves faster convergence rates on sparse and non-regular topologies (e.g., directed ring) and reduces communication overhead on dense networks (e.g., static exponential graph). These results significantly advance the state of the art, especially when $n$ is large. Numerical experiments further demonstrate the strong performance of STPP and confirm the practical relevance of its theoretical convergence rates across various common graph architectures. Our code is available at https://anonymous.4open.science/r/SpanningTreePushPull-5D3E.
HARE: HumAn pRiors, a key to small language model Efficiency
Jun 18, 2024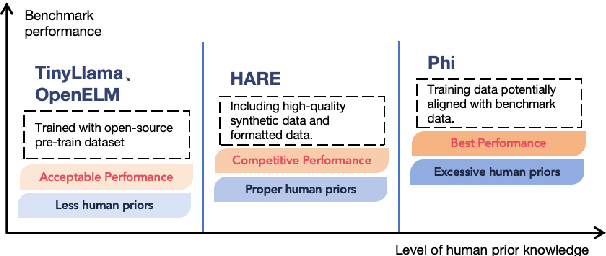
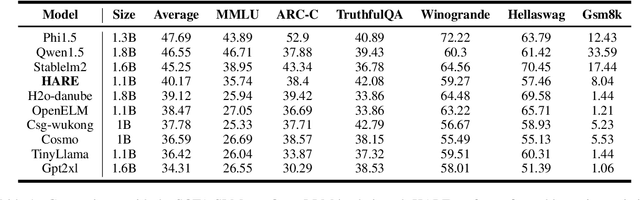
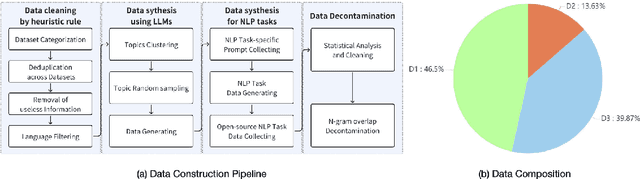
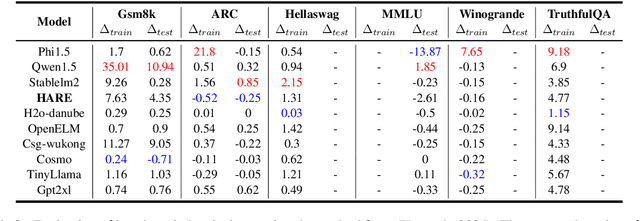
Human priors play a crucial role in efficiently utilizing data in deep learning. However, with the development of large language models (LLMs), there is an increasing emphasis on scaling both model size and data volume, which often diminishes the importance of human priors in data construction. Influenced by these trends, existing Small Language Models (SLMs) mainly rely on web-scraped large-scale training data, neglecting the proper incorporation of human priors. This oversight limits the training efficiency of language models in resource-constrained settings. In this paper, we propose a principle to leverage human priors for data construction. This principle emphasizes achieving high-performance SLMs by training on a concise dataset that accommodates both semantic diversity and data quality consistency, while avoiding benchmark data leakage. Following this principle, we train an SLM named HARE-1.1B. Extensive experiments on large-scale benchmark datasets demonstrate that HARE-1.1B performs favorably against state-of-the-art SLMs, validating the effectiveness of the proposed principle. Additionally, this provides new insights into efficient language model training in resource-constrained environments from the view of human priors.
Distributed Random Reshuffling Methods with Improved Convergence
Jun 21, 2023This paper proposes two distributed random reshuffling methods, namely Gradient Tracking with Random Reshuffling (GT-RR) and Exact Diffusion with Random Reshuffling (ED-RR), to solve the distributed optimization problem over a connected network, where a set of agents aim to minimize the average of their local cost functions. Both algorithms invoke random reshuffling (RR) update for each agent, inherit favorable characteristics of RR for minimizing smooth nonconvex objective functions, and improve the performance of previous distributed random reshuffling methods both theoretically and empirically. Specifically, both GT-RR and ED-RR achieve the convergence rate of $O(1/[(1-\lambda)^{1/3}m^{1/3}T^{2/3}])$ in driving the (minimum) expected squared norm of the gradient to zero, where $T$ denotes the number of epochs, $m$ is the sample size for each agent, and $1-\lambda$ represents the spectral gap of the mixing matrix. When the objective functions further satisfy the Polyak-{\L}ojasiewicz (PL) condition, we show GT-RR and ED-RR both achieve $O(1/[(1-\lambda)mT^2])$ convergence rate in terms of the averaged expected differences between the agents' function values and the global minimum value. Notably, both results are comparable to the convergence rates of centralized RR methods (up to constant factors depending on the network topology) and outperform those of previous distributed random reshuffling algorithms. Moreover, we support the theoretical findings with a set of numerical experiments.
Text-to-Image Diffusion Models can be Easily Backdoored through Multimodal Data Poisoning
May 07, 2023With the help of conditioning mechanisms, the state-of-the-art diffusion models have achieved tremendous success in guided image generation, particularly in text-to-image synthesis. To gain a better understanding of the training process and potential risks of text-to-image synthesis, we perform a systematic investigation of backdoor attack on text-to-image diffusion models and propose BadT2I, a general multimodal backdoor attack framework that tampers with image synthesis in diverse semantic levels. Specifically, we perform backdoor attacks on three levels of the vision semantics: Pixel-Backdoor, Object-Backdoor and Style-Backdoor. By utilizing a regularization loss, our methods efficiently inject backdoors into a large-scale text-to-image diffusion model while preserving its utility with benign inputs. We conduct empirical experiments on Stable Diffusion, the widely-used text-to-image diffusion model, demonstrating that the large-scale diffusion model can be easily backdoored within a few fine-tuning steps. We conduct additional experiments to explore the impact of different types of textual triggers. Besides, we discuss the backdoor persistence during further training, the findings of which provide insights for the development of backdoor defense methods.
One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
Mar 12, 2023

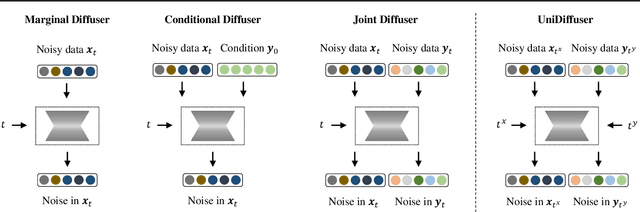

This paper proposes a unified diffusion framework (dubbed UniDiffuser) to fit all distributions relevant to a set of multi-modal data in one model. Our key insight is -- learning diffusion models for marginal, conditional, and joint distributions can be unified as predicting the noise in the perturbed data, where the perturbation levels (i.e. timesteps) can be different for different modalities. Inspired by the unified view, UniDiffuser learns all distributions simultaneously with a minimal modification to the original diffusion model -- perturbs data in all modalities instead of a single modality, inputs individual timesteps in different modalities, and predicts the noise of all modalities instead of a single modality. UniDiffuser is parameterized by a transformer for diffusion models to handle input types of different modalities. Implemented on large-scale paired image-text data, UniDiffuser is able to perform image, text, text-to-image, image-to-text, and image-text pair generation by setting proper timesteps without additional overhead. In particular, UniDiffuser is able to produce perceptually realistic samples in all tasks and its quantitative results (e.g., the FID and CLIP score) are not only superior to existing general-purpose models but also comparable to the bespoken models (e.g., Stable Diffusion and DALL-E 2) in representative tasks (e.g., text-to-image generation).
Distributed Stochastic Optimization under a General Variance Condition
Jan 30, 2023Distributed stochastic optimization has drawn great attention recently due to its effectiveness in solving large-scale machine learning problems. However, despite that numerous algorithms have been proposed with empirical successes, their theoretical guarantees are restrictive and rely on certain boundedness conditions on the stochastic gradients, varying from uniform boundedness to the relaxed growth condition. In addition, how to characterize the data heterogeneity among the agents and its impacts on the algorithmic performance remains challenging. In light of such motivations, we revisit the classical FedAvg algorithm for solving the distributed stochastic optimization problem and establish the convergence results under only a mild variance condition on the stochastic gradients for smooth nonconvex objective functions. Almost sure convergence to a stationary point is also established under the condition. Moreover, we discuss a more informative measurement for data heterogeneity as well as its implications.