 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIVID: Unified Vision-Language Model for Video Moderation
Jun 04, 2026Global-scale video moderation faces a dual challenge: the need for fine-grained multi-modal reasoning and the demand for interpretable outputs to support downstream enforcement. Traditional moderation systems often rely on fragmented black-box classifiers that are difficult to maintain and lack transparency. In this paper, we present UNIVID, a UNIfied VIsion-language model for video moDeration. Unlike standard classification models, UNIVID generates policy-aware captions that serve as an interpretable intermediate representation, enabling human-verifiable decisions and multi-task reusability. While existing open-source and commercial VLMs often suffer from safety-guardrail refusals and lack fine-grained policy alignment, we develop a specialized training data recipe that combines expert human-refined labels with synthetic data to align the model with our safety guidelines. By integrating UNIVID as the core captioner, we design a novel end-to-end video moderation system that reduces violation leakage by 42.7% and overkill rate by 37.0% relatively. Meanwhile, by replacing over 1,000 policy-specific models with a single UNIVID backbone, we recycled extensive computation resources while reducing engineering maintenance overhead. To our knowledge, this is one of the first reports of a high-efficiency captioning VLM successfully supporting industrial-scale moderation and cross-functional business.
CPFD: Confidence-aware Privileged Feature Distillation for Short Video Classification
Oct 07, 2024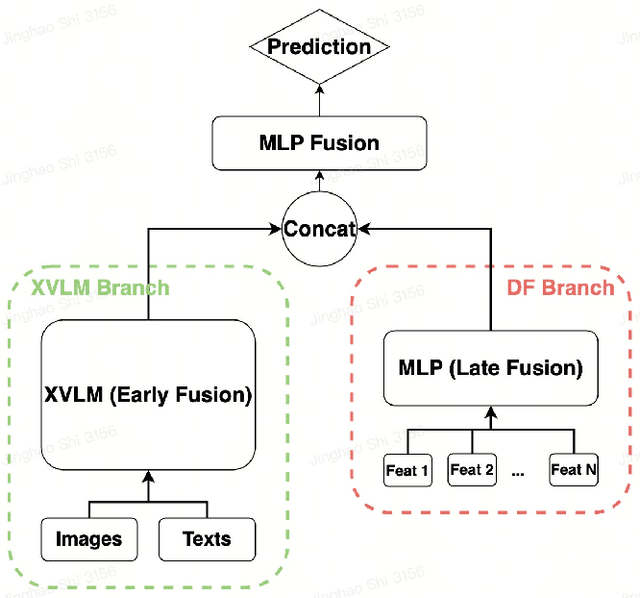
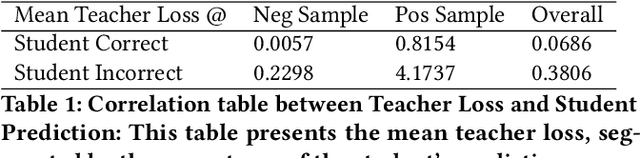
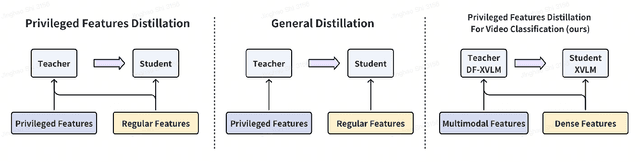

Dense features, customized for different business scenarios, are essential in short video classification. However, their complexity, specific adaptation requirements, and high computational costs make them resource-intensive and less accessible during online inference. Consequently, these dense features are categorized as `Privileged Dense Features'.Meanwhile, end-to-end multi-modal models have shown promising results in numerous computer vision tasks. In industrial applications, prioritizing end-to-end multi-modal features, can enhance efficiency but often leads to the loss of valuable information from historical privileged dense features. To integrate both features while maintaining efficiency and manageable resource costs, we present Confidence-aware Privileged Feature Distillation (CPFD), which empowers features of an end-to-end multi-modal model by adaptively distilling privileged features during training. Unlike existing privileged feature distillation (PFD) methods, which apply uniform weights to all instances during distillation, potentially causing unstable performance across different business scenarios and a notable performance gap between teacher model (Dense Feature enhanced multimodal-model DF-X-VLM) and student model (multimodal-model only X-VLM), our CPFD leverages confidence scores derived from the teacher model to adaptively mitigate the performance variance with the student model. We conducted extensive offline experiments on five diverse tasks demonstrating that CPFD improves the video classification F1 score by 6.76% compared with end-to-end multimodal-model (X-VLM) and by 2.31% with vanilla PFD on-average. And it reduces the performance gap by 84.6% and achieves results comparable to teacher model DF-X-VLM. The effectiveness of CPFD is further substantiated by online experiments, and our framework has been deployed in production systems for over a dozen models.
Alignment-Uniformity aware Representation Learning for Zero-shot Video Classification
Mar 29, 2022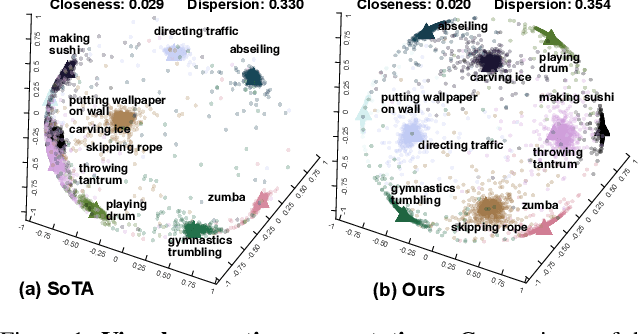
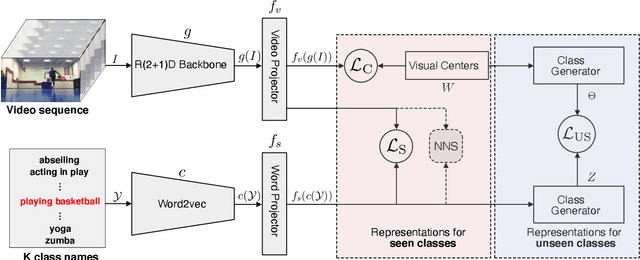
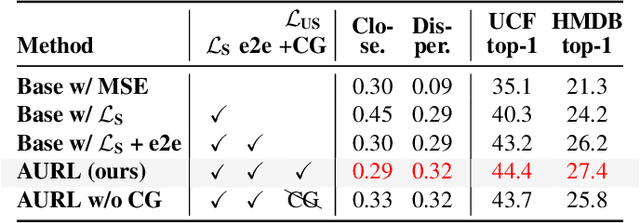
Most methods tackle zero-shot video classification by aligning visual-semantic representations within seen classes, which limits generalization to unseen classes. To enhance model generalizability, this paper presents an end-to-end framework that preserves alignment and uniformity properties for representations on both seen and unseen classes. Specifically, we formulate a supervised contrastive loss to simultaneously align visual-semantic features (i.e., alignment) and encourage the learned features to distribute uniformly (i.e., uniformity). Unlike existing methods that only consider the alignment, we propose uniformity to preserve maximal-info of existing features, which improves the probability that unobserved features fall around observed data. Further, we synthesize features of unseen classes by proposing a class generator that interpolates and extrapolates the features of seen classes. Besides, we introduce two metrics, closeness and dispersion, to quantify the two properties and serve as new measurements of model generalizability. Experiments show that our method significantly outperforms SoTA by relative improvements of 28.1% on UCF101 and 27.0% on HMDB51. Code is available.
Graph Regularized Non-negative Matrix Factorization By Maximizing Correntropy
May 09, 2014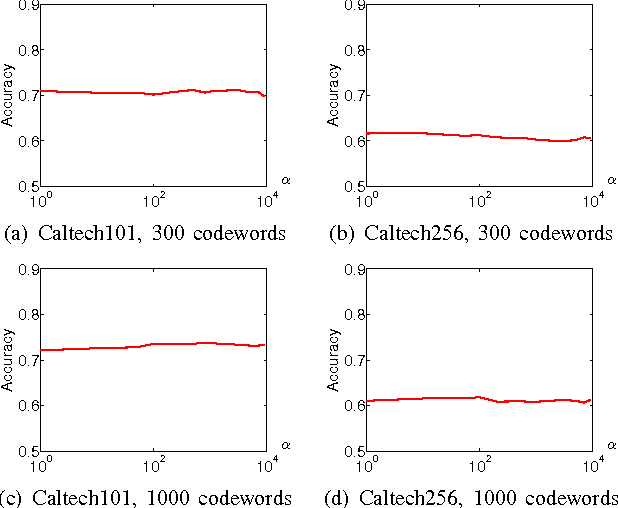
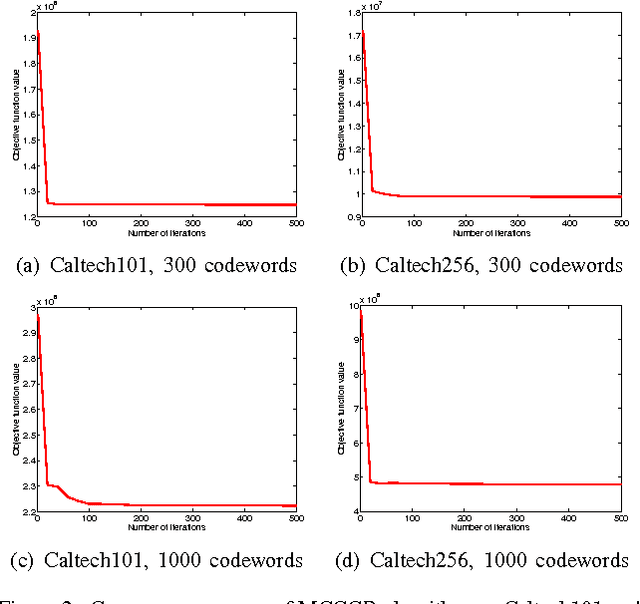
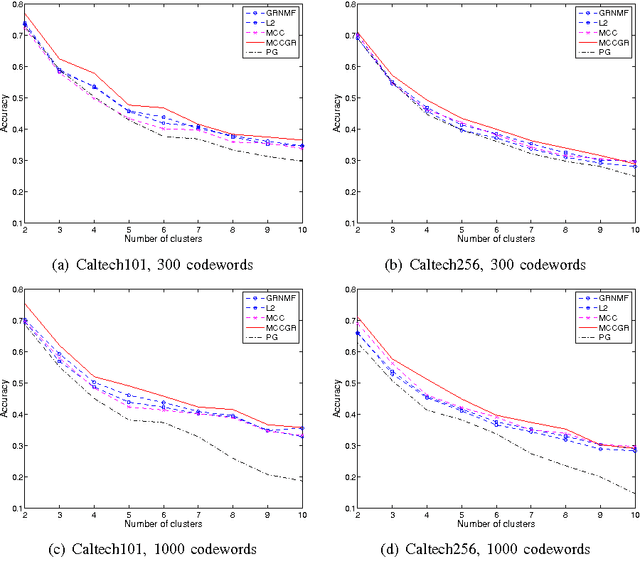
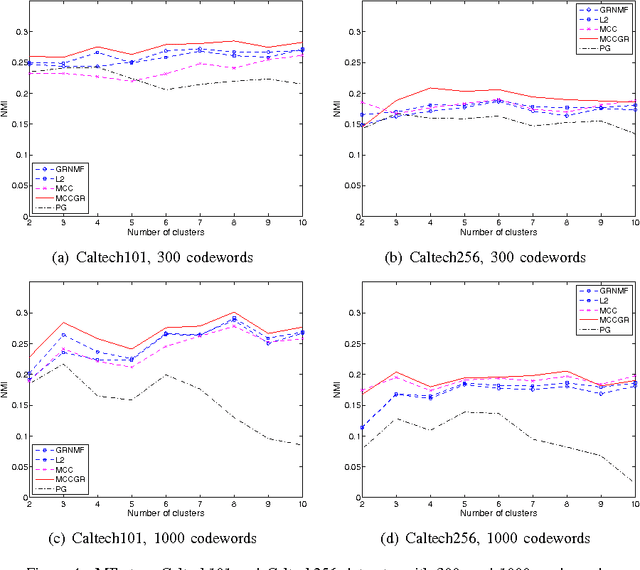
Non-negative matrix factorization (NMF) has proved effective in many clustering and classification tasks. The classic ways to measure the errors between the original and the reconstructed matrix are $l_2$ distance or Kullback-Leibler (KL) divergence. However, nonlinear cases are not properly handled when we use these error measures. As a consequence, alternative measures based on nonlinear kernels, such as correntropy, are proposed. However, the current correntropy-based NMF only targets on the low-level features without considering the intrinsic geometrical distribution of data. In this paper, we propose a new NMF algorithm that preserves local invariance by adding graph regularization into the process of max-correntropy-based matrix factorization. Meanwhile, each feature can learn corresponding kernel from the data. The experiment results of Caltech101 and Caltech256 show the benefits of such combination against other NMF algorithms for the unsupervised image clustering.