 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Concept Grounding Network for Semantically-Consistent Video Generation
Nov 23, 2020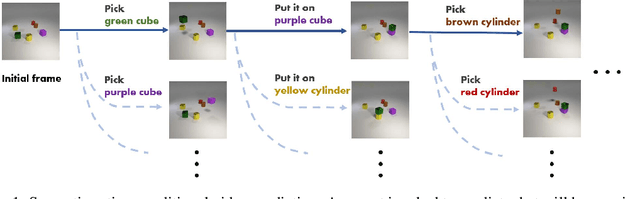
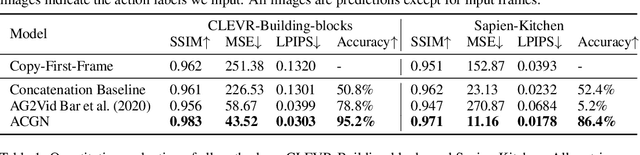
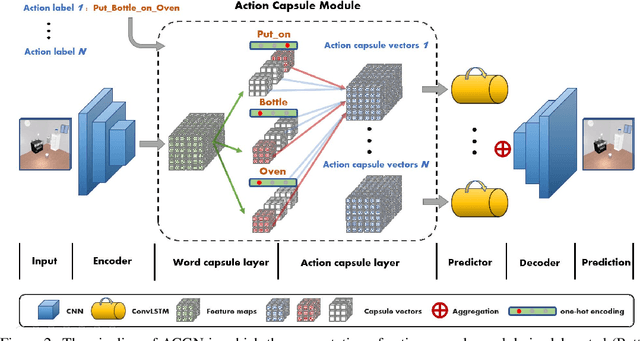

Recent works in self-supervised video prediction have mainly focused on passive forecasting and low-level action-conditional prediction, which sidesteps the problem of semantic learning. We introduce the task of semantic action-conditional video prediction, which can be regarded as an inverse problem of action recognition. The challenge of this new task primarily lies in how to effectively inform the model of semantic action information. To bridge vision and language, we utilize the idea of capsule and propose a novel video prediction model Action Concept Grounding Network (AGCN). Our method is evaluated on two newly designed synthetic datasets, CLEVR-Building-Blocks and Sapien-Kitchen, and experiments show that given different action labels, our ACGN can correctly condition on instructions and generate corresponding future frames without need of bounding boxes. We further demonstrate our trained model can make out-of-distribution predictions for concurrent actions, be quickly adapted to new object categories and exploit its learnt features for object detection. Additional visualizations can be found at https://iclr-acgn.github.io/ACGN/.
CrevNet: Conditionally Reversible Video Prediction
Oct 25, 2019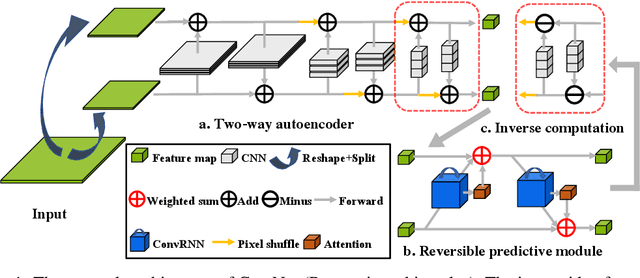

Applying resolution-preserving blocks is a common practice to maximize information preservation in video prediction, yet their high memory consumption greatly limits their application scenarios. We propose CrevNet, a Conditionally Reversible Network that uses reversible architectures to build a bijective two-way autoencoder and its complementary recurrent predictor. Our model enjoys the theoretically guaranteed property of no information loss during the feature extraction, much lower memory consumption and computational efficiency.
Recovering the parameters underlying the Lorenz-96 chaotic dynamics
Jun 16, 2019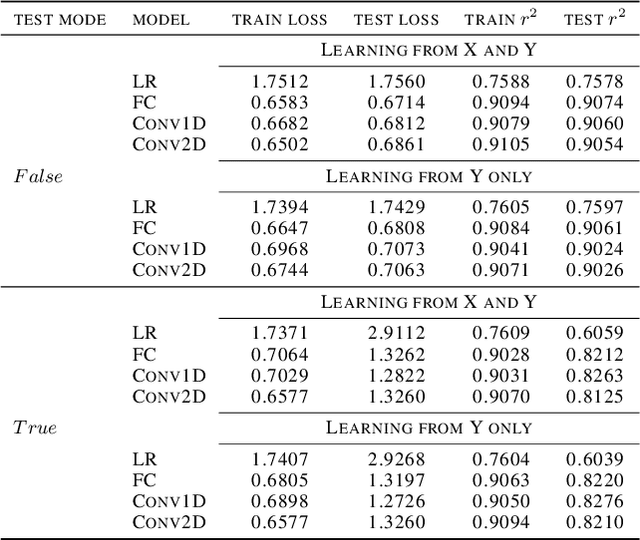
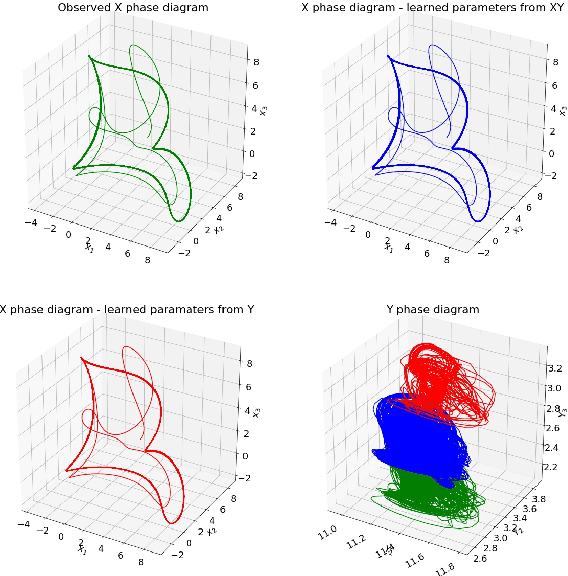
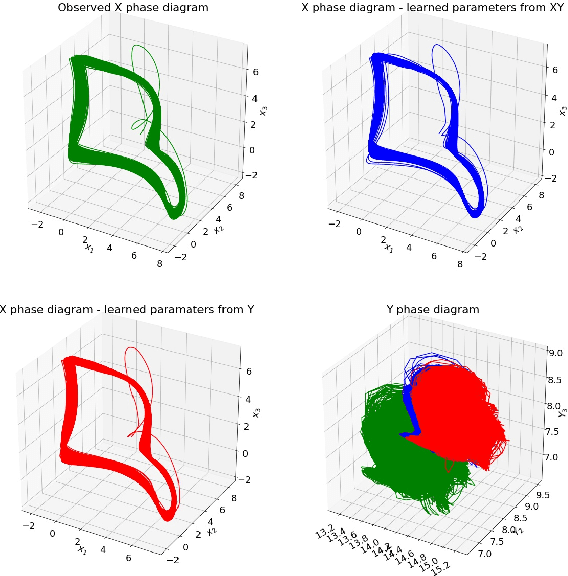
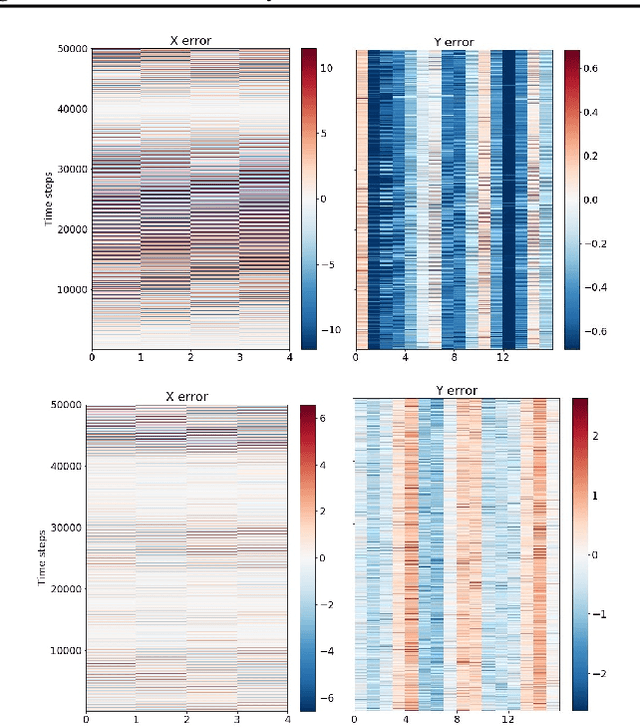
Climate projections suffer from uncertain equilibrium climate sensitivity. The reason behind this uncertainty is the resolution of global climate models, which is too coarse to resolve key processes such as clouds and convection. These processes are approximated using heuristics in a process called parameterization. The selection of these parameters can be subjective, leading to significant uncertainties in the way clouds are represented in global climate models. Here, we explore three deep network algorithms to infer these parameters in an objective and data-driven way. We compare the performance of a fully-connected network, a one-dimensional and, a two-dimensional convolutional networks to recover the underlying parameters of the Lorenz-96 model, a non-linear dynamical system that has similar behavior to the climate system.