 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYouZhi: Towards High-Concurrency Financial LLMs via Adaptive GQA-to-MLA Transition
Jun 04, 2026Large language models (LLMs) drive significant financial innovations, yet their high-concurrency deployment is severely bottlenecked by KV cache memory overhead, which inflates infrastructure costs and throttles scalability. To address this, we propose YouZhi-LLM, a highly efficient financial LLM empowered by a comprehensive structural transition and training pipeline natively built on the Huawei Ascend ecosystem. At its algorithmic core, YouZhi-LLM features a layer-adaptive GQA-to-MLA transition framework that dynamically assigns per-layer FreqFold sizes, maximizing KV-cache compression while minimizing perplexity degradation. To recover representation capacity and inject domain expertise, the Ascend-based training pipeline seamlessly integrates generalized knowledge distillation with financial-specific supervised fine-tuning. Evaluations demonstrate the superiority of this systematic approach, with the adaptive transition reducing perplexity degradation by up to 35% over uniform baselines. Crucially, when evaluated on Ascend NPUs via vLLM-Ascend, the massive KV-cache reduction translates directly into deployment efficiency. Compared to their respective base models, YouZhi-7B yields a 12.3% improvement in average financial benchmark score alongside a 2.69$\times$ increase in maximum concurrency; similarly, YouZhi-14B achieves a 7.0% accuracy gain and a 2.43$\times$ concurrency boost, establishing a new paradigm for cost-effective, high-throughput financial inference.
SID: Sliding into Distribution for Robust Few-Demonstration Manipulation
May 13, 2026Generalizing robotic manipulation across object poses, viewpoints, and dynamic disturbances is difficult, especially with only a few demonstrations. End-to-end visuomotor policies are expressive but data-hungry, while planning and optimization satisfy explicit constraints but do not directly capture the interaction strategies demonstrated by humans. We propose Sliding into Distribution (SID), a structured framework that learns an object-centric motion field from canonicalized demonstrations to iteratively slide the system toward the demonstrated manifold and into the reliable operating region of a lightweight egocentric execution policy, mitigating out-of-distribution (OOD) execution. The motion field provides large corrective motions when far from the demonstration manifold and naturally vanishes near convergence, enabling robust reaching under substantial pose and viewpoint shifts. Within the reached regime, an egocentric policy trained with conditioned flow matching performs task-specific manipulation, supported by kinematically consistent point-cloud reprojection augmentation that preserves action-observation consistency. Across six real-world tasks, SID achieves approximately 90% success under OOD initializations with only two demonstrations, with under a 10% drop under distractors and external disturbances. Overall, SID provides a new paradigm for few-shot manipulation: explicitly managing distribution shift via online distribution recovery.
Active MIMO Sensing With Exploration-Exploitation Tradeoff
Apr 19, 2026This paper develops an active sensing framework for designing the transmit and receive beamformers of a multiple-input multiple-output (MIMO) radar system. In the proposed technique, the beamformers are adaptively designed in each sensing stage based on the measurements made in the previous sensing stages. The beamformers are determined by minimizing the Bayesian Cram{é}r-Rao bound (BCRB) for the estimation of the unknown sensing parameters at each stage via Lagrangian dual optimization. To address the exploration-exploitation tradeoff that is inherent to such an adaptive design, this paper proposes two variants of the BCRB optimization problem: an exploration-centric variant, that ensures that multiple orthogonal beamforming directions are probed in each sensing stage, and an exploitation-centric variant, that does not restrict the number of optimal beamformers. Each variant of the optimization problem is solved via an alternating optimization algorithm that alternates between solving for the transmit beamformers and solving for the receive beamformers. The algorithm is shown to converge to a stationary point provided that each optimization problem is solved to global optimality. Moreover, this paper studies each of the two BCRB optimization sub-problems in the Lagrangian dual domain and shows that despite the non-convexity, global optimality is guaranteed provided that certain sufficient conditions hold. The conditions pertain to the multiplicity of the eigenvalues of a specific direction matrix that can be analytically written in terms of the optimal dual variables. These conditions further imply the tightness of the semidefinite relaxation of the optimization problems. Simulation results demonstrate the benefits of the proposed BCRB-based design compared to state-of-the-art adaptive beamforming strategies.
Site-Specific Channel Modeling and Optimization of RIS-Assisted Multiuser MISO Systems
Mar 22, 2026This paper presents a physics-based channel modeling and optimization framework for reconfigurable intelligent surface (RIS)-assisted downlink multi-user multiple-input single-output (MU-MISO) communication systems in site-specific environments. A hybrid ray-tracing (RT) and full-wave electromagnetic analysis approach is developed to construct a deterministic channel model that explicitly captures multipath propagation, RIS scattering behavior, and mutual coupling effects through a non-diagonal load impedance representation. Based on this model, an alternating optimization scheme jointly updates the base-station (BS) beamformer and RIS load impedances to maximize the minimum achievable rate under a total transmit power constraint and practical capacitance limits. The objective of the proposed framework is to provide a reliable initial assessment of the system-level impact of RIS deployment in realistic propagation scenarios. To evaluate this capability, the RIS is operated in a column-paired 1-bit control mode that enables exhaustive evaluation of all realizable configurations in both simulation and measurement. Performance is compared at the distribution level through achievable-rate histograms across all configurations and further examined under small user-location variations. The observed agreement between simulation and measurement demonstrates that the proposed framework reliably captures practical performance trends and provides useful guidance for the design and deployment of RIS-assisted MU-MISO systems in site-specific environments.
MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
Mar 17, 2026Video diffusion models are moving beyond short, plausible clips toward world simulators that must remain consistent under camera motion, revisits, and intervention. Yet spatial memory remains a key bottleneck: explicit 3D structures can improve reprojection-based consistency but struggle to depict moving objects, while implicit memory often produces inaccurate camera motion even with correct poses. We propose Mosaic Memory (MosaicMem), a hybrid spatial memory that lifts patches into 3D for reliable localization and targeted retrieval, while exploiting the model's native conditioning to preserve prompt-following generation. MosaicMem composes spatially aligned patches in the queried view via a patch-and-compose interface, preserving what should persist while allowing the model to inpaint what should evolve. With PRoPE camera conditioning and two new memory alignment methods, experiments show improved pose adherence compared to implicit memory and stronger dynamic modeling than explicit baselines. MosaicMem further enables minute-level navigation, memory-based scene editing, and autoregressive rollout.
Meta-Cognitive Reinforcement Learning with Self-Doubt and Recovery
Jan 28, 2026Robust reinforcement learning methods typically focus on suppressing unreliable experiences or corrupted rewards, but they lack the ability to reason about the reliability of their own learning process. As a result, such methods often either overreact to noise by becoming overly conservative or fail catastrophically when uncertainty accumulates. In this work, we propose a meta-cognitive reinforcement learning framework that enables an agent to assess, regulate, and recover its learning behavior based on internally estimated reliability signals. The proposed method introduces a meta-trust variable driven by Value Prediction Error Stability (VPES), which modulates learning dynamics via fail-safe regulation and gradual trust recovery. Experiments on continuous-control benchmarks with reward corruption demonstrate that recovery-enabled meta-cognitive control achieves higher average returns and significantly reduces late-stage training failures compared to strong robustness baselines.
Rationale-Grounded In-Context Learning for Time Series Reasoning with Multimodal Large Language Models
Jan 06, 2026The underperformance of existing multimodal large language models for time series reasoning lies in the absence of rationale priors that connect temporal observations to their downstream outcomes, which leads models to rely on superficial pattern matching rather than principled reasoning. We therefore propose the rationale-grounded in-context learning for time series reasoning, where rationales work as guiding reasoning units rather than post-hoc explanations, and develop the RationaleTS method. Specifically, we firstly induce label-conditioned rationales, composed of reasoning paths from observable evidence to the potential outcomes. Then, we design the hybrid retrieval by balancing temporal patterns and semantic contexts to retrieve correlated rationale priors for the final in-context inference on new samples. We conduct extensive experiments to demonstrate the effectiveness and efficiency of our proposed RationaleTS on three-domain time series reasoning tasks. We will release our code for reproduction.
TwinSegNet: A Digital Twin-Enabled Federated Learning Framework for Brain Tumor Analysis
Dec 19, 2025Brain tumor segmentation is critical in diagnosis and treatment planning for the disease. Yet, current deep learning methods rely on centralized data collection, which raises privacy concerns and limits generalization across diverse institutions. In this paper, we propose TwinSegNet, which is a privacy-preserving federated learning framework that integrates a hybrid ViT-UNet model with personalized digital twins for accurate and real-time brain tumor segmentation. Our architecture combines convolutional encoders with Vision Transformer bottlenecks to capture local and global context. Each institution fine-tunes the global model of private data to form its digital twin. Evaluated on nine heterogeneous MRI datasets, including BraTS 2019-2021 and custom tumor collections, TwinSegNet achieves high Dice scores (up to 0.90%) and sensitivity/specificity exceeding 90%, demonstrating robustness across non-independent and identically distributed (IID) client distributions. Comparative results against centralized models such as TumorVisNet highlight TwinSegNet's effectiveness in preserving privacy without sacrificing performance. Our approach enables scalable, personalized segmentation for multi-institutional clinical settings while adhering to strict data confidentiality requirements.
Adaptive Dropout: Unleashing Dropout across Layers for Generalizable Image Super-Resolution
Jun 15, 2025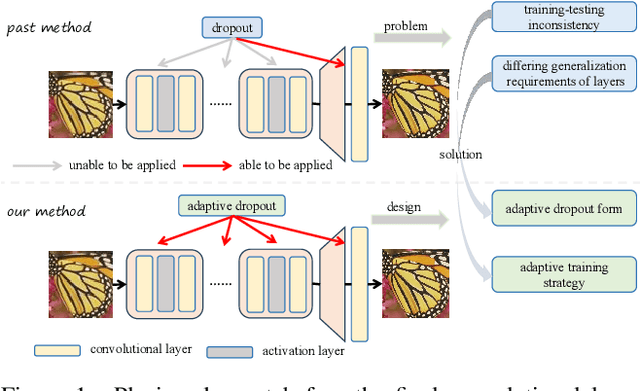



Blind Super-Resolution (blind SR) aims to enhance the model's generalization ability with unknown degradation, yet it still encounters severe overfitting issues. Some previous methods inspired by dropout, which enhances generalization by regularizing features, have shown promising results in blind SR. Nevertheless, these methods focus solely on regularizing features before the final layer and overlook the need for generalization in features at intermediate layers. Without explicit regularization of features at intermediate layers, the blind SR network struggles to obtain well-generalized feature representations. However, the key challenge is that directly applying dropout to intermediate layers leads to a significant performance drop, which we attribute to the inconsistency in training-testing and across layers it introduced. Therefore, we propose Adaptive Dropout, a new regularization method for blind SR models, which mitigates the inconsistency and facilitates application across intermediate layers of networks. Specifically, for training-testing inconsistency, we re-design the form of dropout and integrate the features before and after dropout adaptively. For inconsistency in generalization requirements across different layers, we innovatively design an adaptive training strategy to strengthen feature propagation by layer-wise annealing. Experimental results show that our method outperforms all past regularization methods on both synthetic and real-world benchmark datasets, also highly effective in other image restoration tasks. Code is available at \href{https://github.com/xuhang07/Adpative-Dropout}{https://github.com/xuhang07/Adpative-Dropout}.
Non-Intrusive Load Monitoring Based on Image Load Signatures and Continual Learning
Jun 07, 2025


Non-Intrusive Load Monitoring (NILM) identifies the operating status and energy consumption of each electrical device in the circuit by analyzing the electrical signals at the bus, which is of great significance for smart power management. However, the complex and changeable load combinations and application environments lead to the challenges of poor feature robustness and insufficient model generalization of traditional NILM methods. To this end, this paper proposes a new non-intrusive load monitoring method that integrates "image load signature" and continual learning. This method converts multi-dimensional power signals such as current, voltage, and power factor into visual image load feature signatures, and combines deep convolutional neural networks to realize the identification and classification of multiple devices; at the same time, self-supervised pre-training is introduced to improve feature generalization, and continual online learning strategies are used to overcome model forgetting to adapt to the emergence of new loads. This paper conducts a large number of experiments on high-sampling rate load datasets, and compares a variety of existing methods and model variants. The results show that the proposed method has achieved significant improvements in recognition accuracy.