 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\mathbb{USCD}$: Improving Code Generation of LLMs by Uncertainty-Aware Selective Contrastive Decoding
Paper and Code
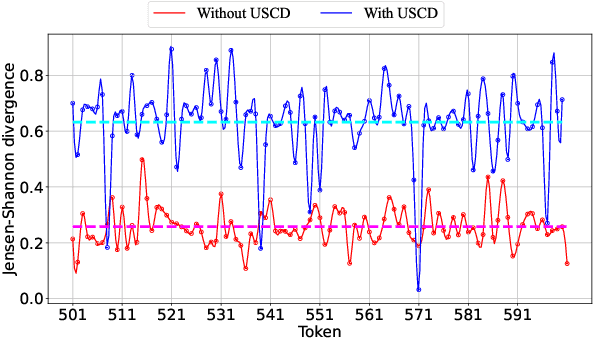
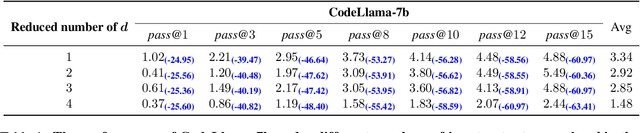
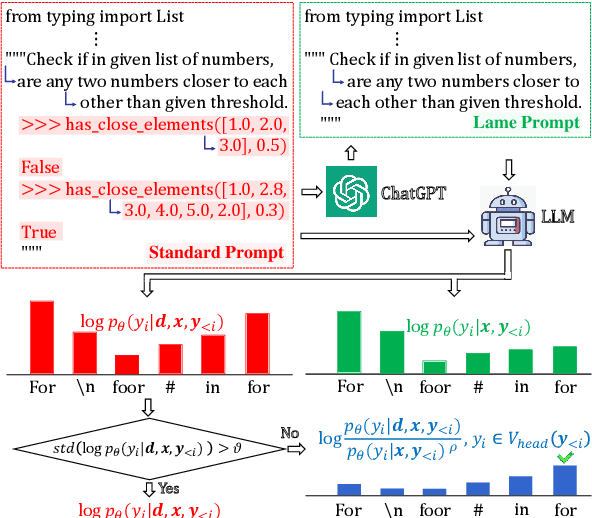
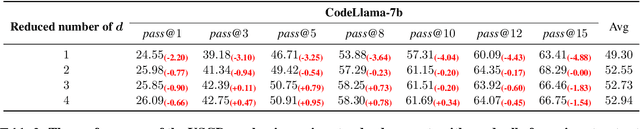
Large language models (LLMs) have shown remarkable capabilities in code generation. However, the effects of hallucinations (e.g., output noise) make it particularly challenging for LLMs to generate high-quality code in one pass. In this work, we propose a simple and effective \textbf{u}ncertainty-aware \textbf{s}elective \textbf{c}ontrastive \textbf{d}ecoding ($\mathbb{USCD}$) mechanism to improve the quality of one-pass code generation in LLMs and reduce the impact of output noise. To be specific, we first elaborately designed a negative prompt (namely lame prompt) to output noise by removing input-output examples from the standard few-shot prompt. Our preliminary study shows that the Jensen-Shannon divergence (JS divergence) between token distribution uncertainty and the output noise is relatively low (approximately $0.25$), indicating their high relevance. Then, we selectively eliminate output noise induced by lame prompts based on the uncertainty of the prediction distribution from the standard prompt. Notably, our proposed plug-and-play mechanism is an inference-only method, enjoying appealing flexibility. Extensive experiments on widely used benchmarks, e.g., HumanEval, MBPP, and MultiPL-E, upon several LLMs (i.e., Inocder-6b, CodeLlama-7b, WizardCoder-15b, StarCoder, and Llama2-7b), demonstrate that our proposed USCD significantly improves one-pass code generation, with an average \textit{pass@$1$} scores increase of 16.59\%. We will release code and data on GitHub.