 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Hardness of Conditional Independence Testing In Practice
Dec 16, 2025Tests of conditional independence (CI) underpin a number of important problems in machine learning and statistics, from causal discovery to evaluation of predictor fairness and out-of-distribution robustness. Shah and Peters (2020) showed that, contrary to the unconditional case, no universally finite-sample valid test can ever achieve nontrivial power. While informative, this result (based on "hiding" dependence) does not seem to explain the frequent practical failures observed with popular CI tests. We investigate the Kernel-based Conditional Independence (KCI) test - of which we show the Generalized Covariance Measure underlying many recent tests is nearly a special case - and identify the major factors underlying its practical behavior. We highlight the key role of errors in the conditional mean embedding estimate for the Type-I error, while pointing out the importance of selecting an appropriate conditioning kernel (not recognized in previous work) as being necessary for good test power but also tending to inflate Type-I error.
Efficient kernelized bandit algorithms via exploration distributions
Jun 11, 2025We consider a kernelized bandit problem with a compact arm set ${X} \subset \mathbb{R}^d $ and a fixed but unknown reward function $f^*$ with a finite norm in some Reproducing Kernel Hilbert Space (RKHS). We propose a class of computationally efficient kernelized bandit algorithms, which we call GP-Generic, based on a novel concept: exploration distributions. This class of algorithms includes Upper Confidence Bound-based approaches as a special case, but also allows for a variety of randomized algorithms. With careful choice of exploration distribution, our proposed generic algorithm realizes a wide range of concrete algorithms that achieve $\tilde{O}(\gamma_T\sqrt{T})$ regret bounds, where $\gamma_T$ characterizes the RKHS complexity. This matches known results for UCB- and Thompson Sampling-based algorithms; we also show that in practice, randomization can yield better practical results.
ELBA-Bench: An Efficient Learning Backdoor Attacks Benchmark for Large Language Models
Feb 22, 2025



Generative large language models are crucial in natural language processing, but they are vulnerable to backdoor attacks, where subtle triggers compromise their behavior. Although backdoor attacks against LLMs are constantly emerging, existing benchmarks remain limited in terms of sufficient coverage of attack, metric system integrity, backdoor attack alignment. And existing pre-trained backdoor attacks are idealized in practice due to resource access constraints. Therefore we establish $\textit{ELBA-Bench}$, a comprehensive and unified framework that allows attackers to inject backdoor through parameter efficient fine-tuning ($\textit{e.g.,}$ LoRA) or without fine-tuning techniques ($\textit{e.g.,}$ In-context-learning). $\textit{ELBA-Bench}$ provides over 1300 experiments encompassing the implementations of 12 attack methods, 18 datasets, and 12 LLMs. Extensive experiments provide new invaluable findings into the strengths and limitations of various attack strategies. For instance, PEFT attack consistently outperform without fine-tuning approaches in classification tasks while showing strong cross-dataset generalization with optimized triggers boosting robustness; Task-relevant backdoor optimization techniques or attack prompts along with clean and adversarial demonstrations can enhance backdoor attack success while preserving model performance on clean samples. Additionally, we introduce a universal toolbox designed for standardized backdoor attack research, with the goal of propelling further progress in this vital area.
Leveraging Metamemory Mechanisms for Enhanced Data-Free Code Generation in LLMs
Jan 14, 2025



Automated code generation using large language models (LLMs) has gained attention due to its efficiency and adaptability. However, real-world coding tasks or benchmarks like HumanEval and StudentEval often lack dedicated training datasets, challenging existing few-shot prompting approaches that rely on reference examples. Inspired by human metamemory-a cognitive process involving recall and evaluation-we present a novel framework (namely M^2WF) for improving LLMs' one-time code generation. This approach enables LLMs to autonomously generate, evaluate, and utilize synthetic examples to enhance reliability and performance. Unlike prior methods, it minimizes dependency on curated data and adapts flexibly to various coding scenarios. Our experiments demonstrate significant improvements in coding benchmarks, offering a scalable and robust solution for data-free environments. The code and framework will be publicly available on GitHub and HuggingFace.
Learning from Ambiguous Data with Hard Labels
Jan 08, 2025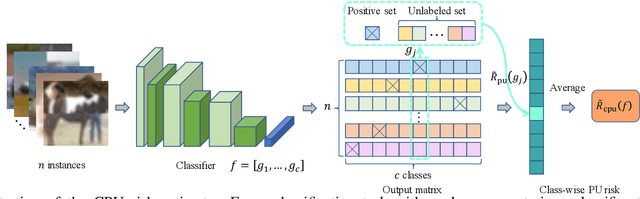

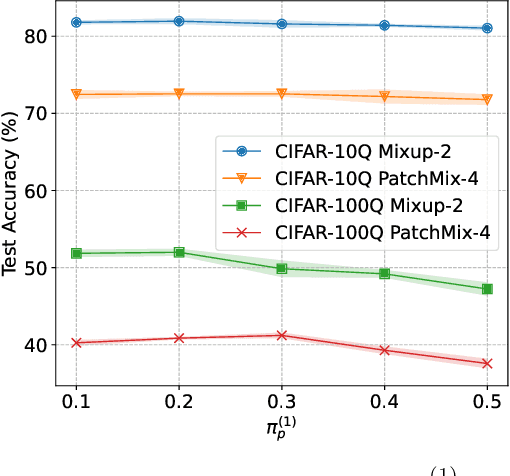
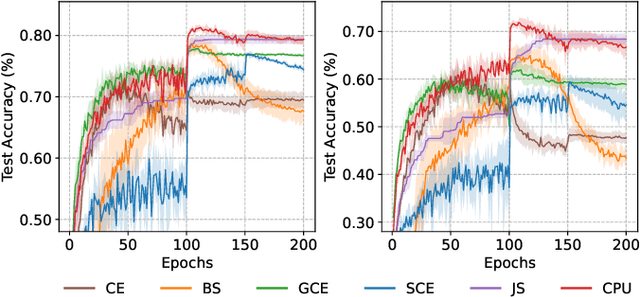
Real-world data often contains intrinsic ambiguity that the common single-hard-label annotation paradigm ignores. Standard training using ambiguous data with these hard labels may produce overly confident models and thus leading to poor generalization. In this paper, we propose a novel framework called Quantized Label Learning (QLL) to alleviate this issue. First, we formulate QLL as learning from (very) ambiguous data with hard labels: ideally, each ambiguous instance should be associated with a ground-truth soft-label distribution describing its corresponding probabilistic weight in each class, however, this is usually not accessible; in practice, we can only observe a quantized label, i.e., a hard label sampled (quantized) from the corresponding ground-truth soft-label distribution, of each instance, which can be seen as a biased approximation of the ground-truth soft-label. Second, we propose a Class-wise Positive-Unlabeled (CPU) risk estimator that allows us to train accurate classifiers from only ambiguous data with quantized labels. Third, to simulate ambiguous datasets with quantized labels in the real world, we design a mixing-based ambiguous data generation procedure for empirical evaluation. Experiments demonstrate that our CPU method can significantly improve model generalization performance and outperform the baselines.
CKSP: Cross-species Knowledge Sharing and Preserving for Universal Animal Activity Recognition
Oct 22, 2024Deep learning techniques are dominating automated animal activity recognition (AAR) tasks with wearable sensors due to their high performance on large-scale labelled data. However, current deep learning-based AAR models are trained solely on datasets of individual animal species, constraining their applicability in practice and performing poorly when training data are limited. In this study, we propose a one-for-many framework, dubbed Cross-species Knowledge Sharing and Preserving (CKSP), based on sensor data of diverse animal species. Given the coexistence of generic and species-specific behavioural patterns among different species, we design a Shared-Preserved Convolution (SPConv) module. This module assigns an individual low-rank convolutional layer to each species for extracting species-specific features and employs a shared full-rank convolutional layer to learn generic features, enabling the CKSP framework to learn inter-species complementarity and alleviating data limitations via increasing data diversity. Considering the training conflict arising from discrepancies in data distributions among species, we devise a Species-specific Batch Normalization (SBN) module, that involves multiple BN layers to separately fit the distributions of different species. To validate CKSP's effectiveness, experiments are performed on three public datasets from horses, sheep, and cattle, respectively. The results show that our approach remarkably boosts the classification performance compared to the baseline method (one-for-one framework) solely trained on individual-species data, with increments of 6.04%, 2.06%, and 3.66% in accuracy, and 10.33%, 3.67%, and 7.90% in F1-score for the horse, sheep, and cattle datasets, respectively. This proves the promising capabilities of our method in leveraging multi-species data to augment classification performance.
$\mathbb{USCD}$: Improving Code Generation of LLMs by Uncertainty-Aware Selective Contrastive Decoding
Sep 09, 2024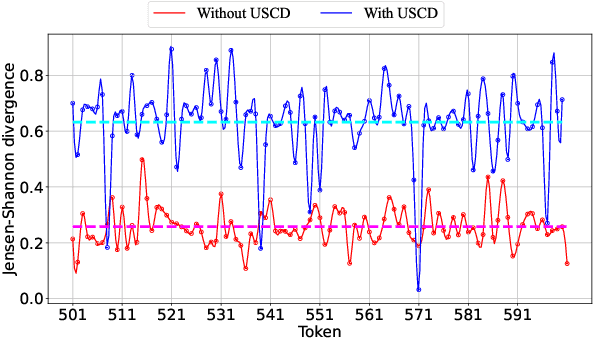
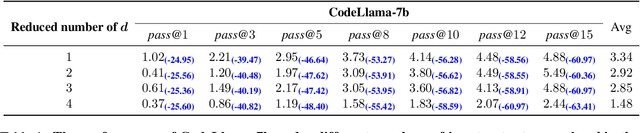
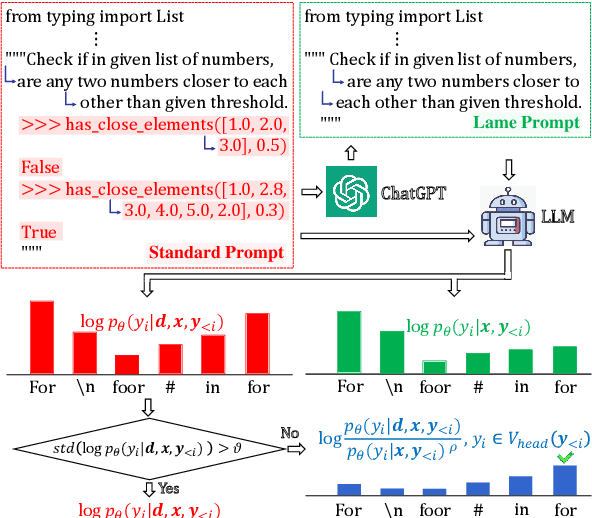
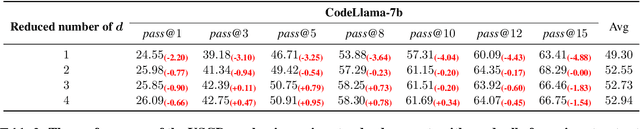
Large language models (LLMs) have shown remarkable capabilities in code generation. However, the effects of hallucinations (e.g., output noise) make it particularly challenging for LLMs to generate high-quality code in one pass. In this work, we propose a simple and effective \textbf{u}ncertainty-aware \textbf{s}elective \textbf{c}ontrastive \textbf{d}ecoding ($\mathbb{USCD}$) mechanism to improve the quality of one-pass code generation in LLMs and reduce the impact of output noise. To be specific, we first elaborately designed a negative prompt (namely lame prompt) to output noise by removing input-output examples from the standard few-shot prompt. Our preliminary study shows that the Jensen-Shannon divergence (JS divergence) between token distribution uncertainty and the output noise is relatively low (approximately $0.25$), indicating their high relevance. Then, we selectively eliminate output noise induced by lame prompts based on the uncertainty of the prediction distribution from the standard prompt. Notably, our proposed plug-and-play mechanism is an inference-only method, enjoying appealing flexibility. Extensive experiments on widely used benchmarks, e.g., HumanEval, MBPP, and MultiPL-E, upon several LLMs (i.e., Inocder-6b, CodeLlama-7b, WizardCoder-15b, StarCoder, and Llama2-7b), demonstrate that our proposed USCD significantly improves one-pass code generation, with an average \textit{pass@$1$} scores increase of 16.59\%. We will release code and data on GitHub.
MTGA: Multi-view Temporal Granularity aligned Aggregation for Event-based Lip-reading
Apr 18, 2024



Lip-reading is to utilize the visual information of the speaker's lip movements to recognize words and sentences. Existing event-based lip-reading solutions integrate different frame rate branches to learn spatio-temporal features of varying granularities. However, aggregating events into event frames inevitably leads to the loss of fine-grained temporal information within frames. To remedy this drawback, we propose a novel framework termed Multi-view Temporal Granularity aligned Aggregation (MTGA). Specifically, we first present a novel event representation method, namely time-segmented voxel graph list, where the most significant local voxels are temporally connected into a graph list. Then we design a spatio-temporal fusion module based on temporal granularity alignment, where the global spatial features extracted from event frames, together with the local relative spatial and temporal features contained in voxel graph list are effectively aligned and integrated. Finally, we design a temporal aggregation module that incorporates positional encoding, which enables the capture of local absolute spatial and global temporal information. Experiments demonstrate that our method outperforms both the event-based and video-based lip-reading counterparts. Our code will be publicly available.
A Protein Structure Prediction Approach Leveraging Transformer and CNN Integration
Mar 08, 2024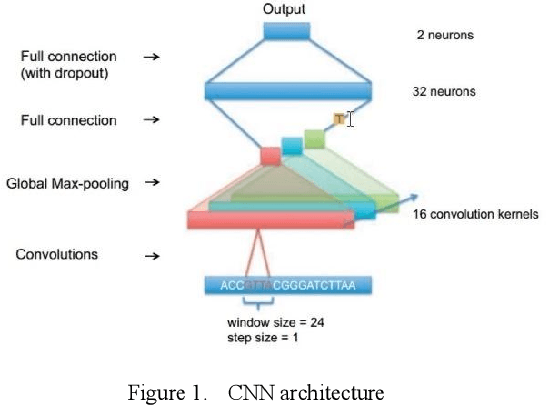
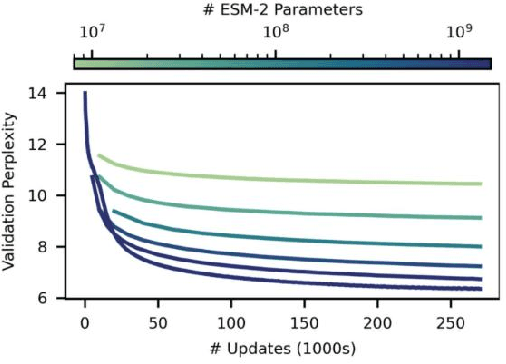
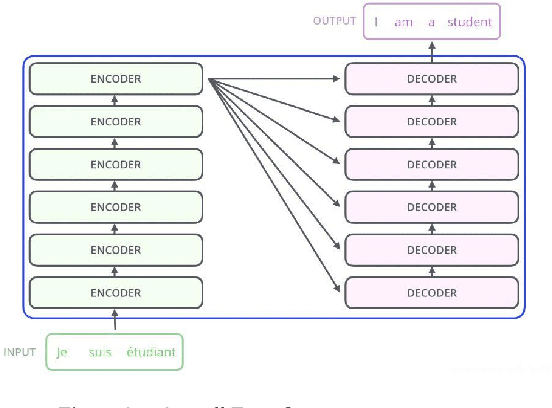
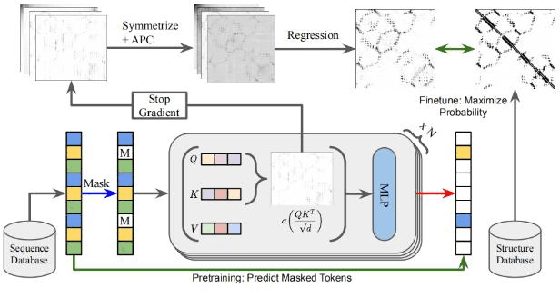
Proteins are essential for life, and their structure determines their function. The protein secondary structure is formed by the folding of the protein primary structure, and the protein tertiary structure is formed by the bending and folding of the secondary structure. Therefore, the study of protein secondary structure is very helpful to the overall understanding of protein structure. Although the accuracy of protein secondary structure prediction has continuously improved with the development of machine learning and deep learning, progress in the field of protein structure prediction, unfortunately, remains insufficient to meet the large demand for protein information. Therefore, based on the advantages of deep learning-based methods in feature extraction and learning ability, this paper adopts a two-dimensional fusion deep neural network model, DstruCCN, which uses Convolutional Neural Networks (CCN) and a supervised Transformer protein language model for single-sequence protein structure prediction. The training features of the two are combined to predict the protein Transformer binding site matrix, and then the three-dimensional structure is reconstructed using energy minimization.
Construction and application of artificial intelligence crowdsourcing map based on multi-track GPS data
Feb 24, 2024



In recent years, the rapid development of high-precision map technology combined with artificial intelligence has ushered in a new development opportunity in the field of intelligent vehicles. High-precision map technology is an important guarantee for intelligent vehicles to achieve autonomous driving. However, due to the lack of research on high-precision map technology, it is difficult to rationally use this technology in the field of intelligent vehicles. Therefore, relevant researchers studied a fast and effective algorithm to generate high-precision GPS data from a large number of low-precision GPS trajectory data fusion, and generated several key data points to simplify the description of GPS trajectory, and realized the "crowdsourced update" model based on a large number of social vehicles for map data collection came into being. This kind of algorithm has the important significance to improve the data accuracy, reduce the measurement cost and reduce the data storage space. On this basis, this paper analyzes the implementation form of crowdsourcing map, so as to improve the various information data in the high-precision map according to the actual situation, and promote the high-precision map can be reasonably applied to the intelligent car.