 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELBA-Bench: An Efficient Learning Backdoor Attacks Benchmark for Large Language Models
Feb 22, 2025



Generative large language models are crucial in natural language processing, but they are vulnerable to backdoor attacks, where subtle triggers compromise their behavior. Although backdoor attacks against LLMs are constantly emerging, existing benchmarks remain limited in terms of sufficient coverage of attack, metric system integrity, backdoor attack alignment. And existing pre-trained backdoor attacks are idealized in practice due to resource access constraints. Therefore we establish $\textit{ELBA-Bench}$, a comprehensive and unified framework that allows attackers to inject backdoor through parameter efficient fine-tuning ($\textit{e.g.,}$ LoRA) or without fine-tuning techniques ($\textit{e.g.,}$ In-context-learning). $\textit{ELBA-Bench}$ provides over 1300 experiments encompassing the implementations of 12 attack methods, 18 datasets, and 12 LLMs. Extensive experiments provide new invaluable findings into the strengths and limitations of various attack strategies. For instance, PEFT attack consistently outperform without fine-tuning approaches in classification tasks while showing strong cross-dataset generalization with optimized triggers boosting robustness; Task-relevant backdoor optimization techniques or attack prompts along with clean and adversarial demonstrations can enhance backdoor attack success while preserving model performance on clean samples. Additionally, we introduce a universal toolbox designed for standardized backdoor attack research, with the goal of propelling further progress in this vital area.
PartSeg: Few-shot Part Segmentation via Part-aware Prompt Learning
Aug 24, 2023In this work, we address the task of few-shot part segmentation, which aims to segment the different parts of an unseen object using very few labeled examples. It is found that leveraging the textual space of a powerful pre-trained image-language model (such as CLIP) can be beneficial in learning visual features. Therefore, we develop a novel method termed PartSeg for few-shot part segmentation based on multimodal learning. Specifically, we design a part-aware prompt learning method to generate part-specific prompts that enable the CLIP model to better understand the concept of ``part'' and fully utilize its textual space. Furthermore, since the concept of the same part under different object categories is general, we establish relationships between these parts during the prompt learning process. We conduct extensive experiments on the PartImageNet and Pascal$\_$Part datasets, and the experimental results demonstrated that our proposed method achieves state-of-the-art performance.
Not All Instances Contribute Equally: Instance-adaptive Class Representation Learning for Few-Shot Visual Recognition
Sep 07, 2022
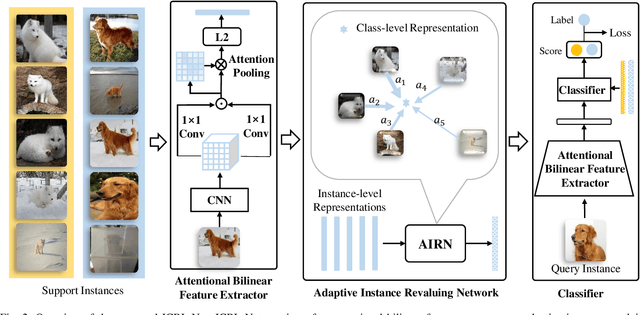
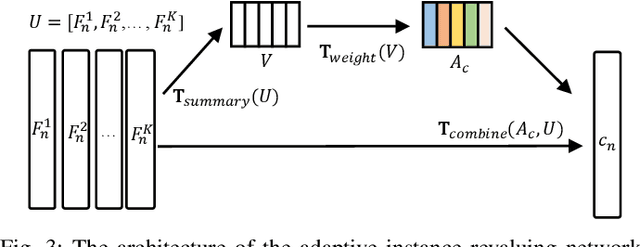
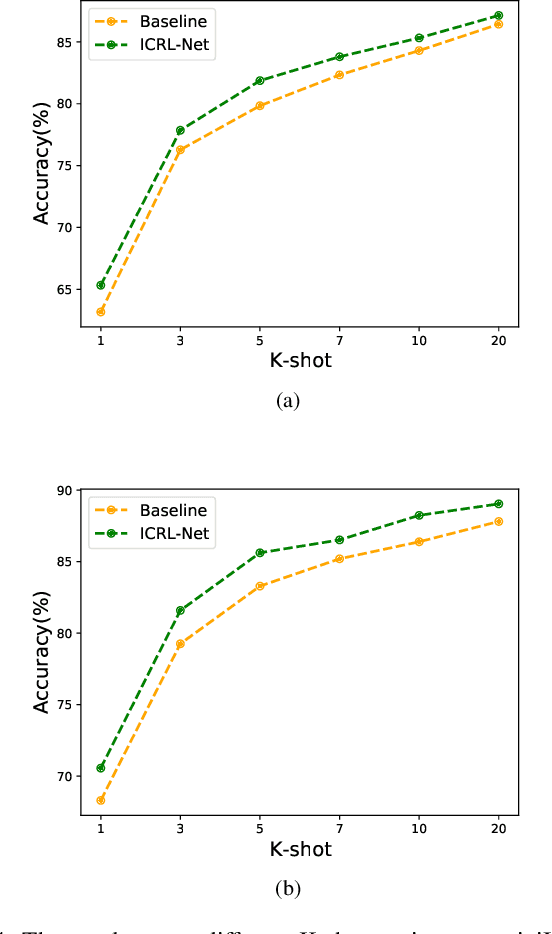
Few-shot visual recognition refers to recognize novel visual concepts from a few labeled instances. Many few-shot visual recognition methods adopt the metric-based meta-learning paradigm by comparing the query representation with class representations to predict the category of query instance. However, current metric-based methods generally treat all instances equally and consequently often obtain biased class representation, considering not all instances are equally significant when summarizing the instance-level representations for the class-level representation. For example, some instances may contain unrepresentative information, such as too much background and information of unrelated concepts, which skew the results. To address the above issues, we propose a novel metric-based meta-learning framework termed instance-adaptive class representation learning network (ICRL-Net) for few-shot visual recognition. Specifically, we develop an adaptive instance revaluing network with the capability to address the biased representation issue when generating the class representation, by learning and assigning adaptive weights for different instances according to their relative significance in the support set of corresponding class. Additionally, we design an improved bilinear instance representation and incorporate two novel structural losses, i.e., intra-class instance clustering loss and inter-class representation distinguishing loss, to further regulate the instance revaluation process and refine the class representation. We conduct extensive experiments on four commonly adopted few-shot benchmarks: miniImageNet, tieredImageNet, CIFAR-FS, and FC100 datasets. The experimental results compared with the state-of-the-art approaches demonstrate the superiority of our ICRL-Net.
Leveraging GAN Priors for Few-Shot Part Segmentation
Jul 27, 2022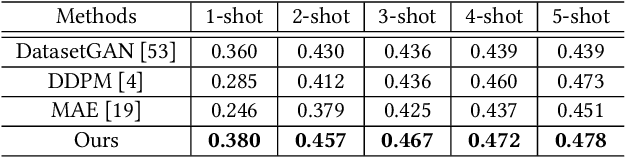
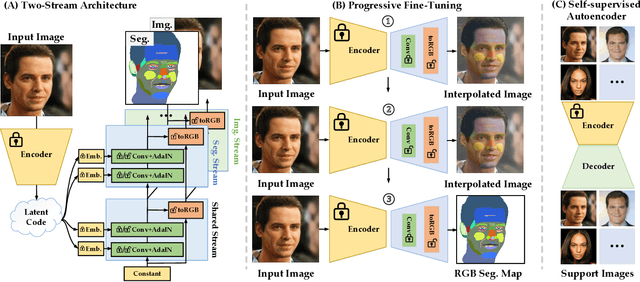
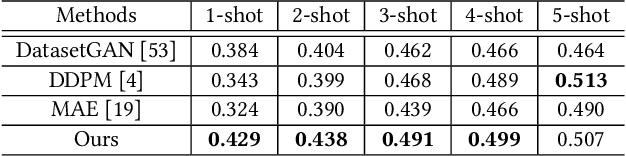

Few-shot part segmentation aims to separate different parts of an object given only a few annotated samples. Due to the challenge of limited data, existing works mainly focus on learning classifiers over pre-trained features, failing to learn task-specific features for part segmentation. In this paper, we propose to learn task-specific features in a "pre-training"-"fine-tuning" paradigm. We conduct prompt designing to reduce the gap between the pre-train task (i.e., image generation) and the downstream task (i.e., part segmentation), so that the GAN priors for generation can be leveraged for segmentation. This is achieved by projecting part segmentation maps into the RGB space and conducting interpolation between RGB segmentation maps and original images. Specifically, we design a fine-tuning strategy to progressively tune an image generator into a segmentation generator, where the supervision of the generator varying from images to segmentation maps by interpolation. Moreover, we propose a two-stream architecture, i.e., a segmentation stream to generate task-specific features, and an image stream to provide spatial constraints. The image stream can be regarded as a self-supervised auto-encoder, and this enables our model to benefit from large-scale support images. Overall, this work is an attempt to explore the internal relevance between generation tasks and perception tasks by prompt designing. Extensive experiments show that our model can achieve state-of-the-art performance on several part segmentation datasets.