 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparc3D: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling
May 21, 2025High-fidelity 3D object synthesis remains significantly more challenging than 2D image generation due to the unstructured nature of mesh data and the cubic complexity of dense volumetric grids. Existing two-stage pipelines-compressing meshes with a VAE (using either 2D or 3D supervision), followed by latent diffusion sampling-often suffer from severe detail loss caused by inefficient representations and modality mismatches introduced in VAE. We introduce Sparc3D, a unified framework that combines a sparse deformable marching cubes representation Sparcubes with a novel encoder Sparconv-VAE. Sparcubes converts raw meshes into high-resolution ($1024^3$) surfaces with arbitrary topology by scattering signed distance and deformation fields onto a sparse cube, allowing differentiable optimization. Sparconv-VAE is the first modality-consistent variational autoencoder built entirely upon sparse convolutional networks, enabling efficient and near-lossless 3D reconstruction suitable for high-resolution generative modeling through latent diffusion. Sparc3D achieves state-of-the-art reconstruction fidelity on challenging inputs, including open surfaces, disconnected components, and intricate geometry. It preserves fine-grained shape details, reduces training and inference cost, and integrates naturally with latent diffusion models for scalable, high-resolution 3D generation.
Hyper3D: Efficient 3D Representation via Hybrid Triplane and Octree Feature for Enhanced 3D Shape Variational Auto-Encoders
Mar 13, 2025Recent 3D content generation pipelines often leverage Variational Autoencoders (VAEs) to encode shapes into compact latent representations, facilitating diffusion-based generation. Efficiently compressing 3D shapes while preserving intricate geometric details remains a key challenge. Existing 3D shape VAEs often employ uniform point sampling and 1D/2D latent representations, such as vector sets or triplanes, leading to significant geometric detail loss due to inadequate surface coverage and the absence of explicit 3D representations in the latent space. Although recent work explores 3D latent representations, their large scale hinders high-resolution encoding and efficient training. Given these challenges, we introduce Hyper3D, which enhances VAE reconstruction through efficient 3D representation that integrates hybrid triplane and octree features. First, we adopt an octree-based feature representation to embed mesh information into the network, mitigating the limitations of uniform point sampling in capturing geometric distributions along the mesh surface. Furthermore, we propose a hybrid latent space representation that integrates a high-resolution triplane with a low-resolution 3D grid. This design not only compensates for the lack of explicit 3D representations but also leverages a triplane to preserve high-resolution details. Experimental results demonstrate that Hyper3D outperforms traditional representations by reconstructing 3D shapes with higher fidelity and finer details, making it well-suited for 3D generation pipelines.
MagicNaming: Consistent Identity Generation by Finding a "Name Space" in T2I Diffusion Models
Dec 19, 2024



Large-scale text-to-image diffusion models, (e.g., DALL-E, SDXL) are capable of generating famous persons by simply referring to their names. Is it possible to make such models generate generic identities as simple as the famous ones, e.g., just use a name? In this paper, we explore the existence of a "Name Space", where any point in the space corresponds to a specific identity. Fortunately, we find some clues in the feature space spanned by text embedding of celebrities' names. Specifically, we first extract the embeddings of celebrities' names in the Laion5B dataset with the text encoder of diffusion models. Such embeddings are used as supervision to learn an encoder that can predict the name (actually an embedding) of a given face image. We experimentally find that such name embeddings work well in promising the generated image with good identity consistency. Note that like the names of celebrities, our predicted name embeddings are disentangled from the semantics of text inputs, making the original generation capability of text-to-image models well-preserved. Moreover, by simply plugging such name embeddings, all variants (e.g., from Civitai) derived from the same base model (i.e., SDXL) readily become identity-aware text-to-image models. Project homepage: \url{https://magicfusion.github.io/MagicNaming/}.
* Accepted by AAAI 2025
Infinite-ID: Identity-preserved Personalization via ID-semantics Decoupling Paradigm
Mar 18, 2024



Drawing on recent advancements in diffusion models for text-to-image generation, identity-preserved personalization has made significant progress in accurately capturing specific identities with just a single reference image. However, existing methods primarily integrate reference images within the text embedding space, leading to a complex entanglement of image and text information, which poses challenges for preserving both identity fidelity and semantic consistency. To tackle this challenge, we propose Infinite-ID, an ID-semantics decoupling paradigm for identity-preserved personalization. Specifically, we introduce identity-enhanced training, incorporating an additional image cross-attention module to capture sufficient ID information while deactivating the original text cross-attention module of the diffusion model. This ensures that the image stream faithfully represents the identity provided by the reference image while mitigating interference from textual input. Additionally, we introduce a feature interaction mechanism that combines a mixed attention module with an AdaIN-mean operation to seamlessly merge the two streams. This mechanism not only enhances the fidelity of identity and semantic consistency but also enables convenient control over the styles of the generated images. Extensive experimental results on both raw photo generation and style image generation demonstrate the superior performance of our proposed method.
PartSeg: Few-shot Part Segmentation via Part-aware Prompt Learning
Aug 24, 2023In this work, we address the task of few-shot part segmentation, which aims to segment the different parts of an unseen object using very few labeled examples. It is found that leveraging the textual space of a powerful pre-trained image-language model (such as CLIP) can be beneficial in learning visual features. Therefore, we develop a novel method termed PartSeg for few-shot part segmentation based on multimodal learning. Specifically, we design a part-aware prompt learning method to generate part-specific prompts that enable the CLIP model to better understand the concept of ``part'' and fully utilize its textual space. Furthermore, since the concept of the same part under different object categories is general, we establish relationships between these parts during the prompt learning process. We conduct extensive experiments on the PartImageNet and Pascal$\_$Part datasets, and the experimental results demonstrated that our proposed method achieves state-of-the-art performance.
Null-text Guidance in Diffusion Models is Secretly a Cartoon-style Creator
May 11, 2023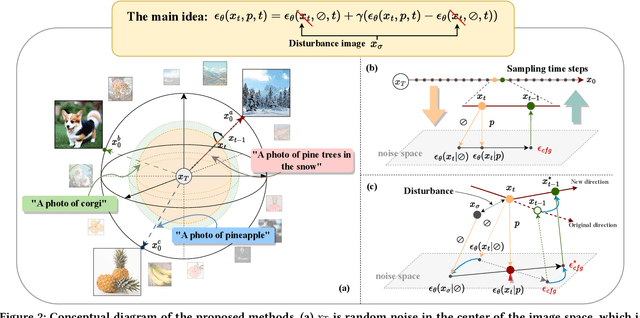
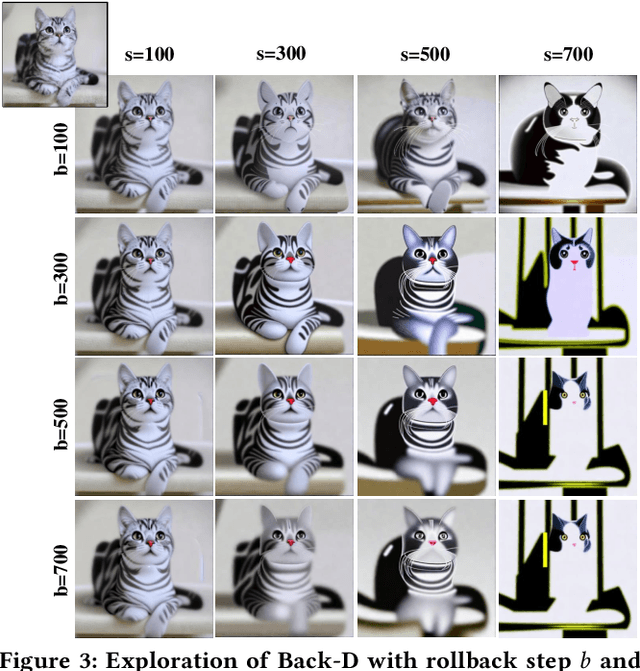

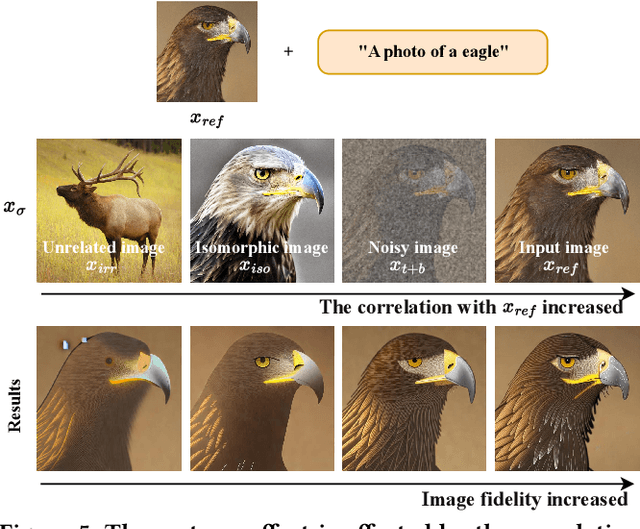
Classifier-free guidance is an effective sampling technique in diffusion models that has been widely adopted. The main idea is to extrapolate the model in the direction of text guidance and away from null-text guidance. In this paper, we demonstrate that null-text guidance in diffusion models is secretly a cartoon-style creator, i.e., the generated images can be efficiently transformed into cartoons by simply perturbing the null-text guidance. Specifically, we proposed two disturbance methods, i.e., Rollback disturbance (Back-D) and Image disturbance (Image-D), to construct misalignment between the noisy images used for predicting null-text guidance and text guidance (subsequently referred to as \textbf{null-text noisy image} and \textbf{text noisy image} respectively) in the sampling process. Back-D achieves cartoonization by altering the noise level of null-text noisy image via replacing $x_t$ with $x_{t+\Delta t}$. Image-D, alternatively, produces high-fidelity, diverse cartoons by defining $x_t$ as a clean input image, which further improves the incorporation of finer image details. Through comprehensive experiments, we delved into the principle of noise disturbing for null-text and uncovered that the efficacy of disturbance depends on the correlation between the null-text noisy image and the source image. Moreover, our proposed techniques, which can generate cartoon images and cartoonize specific ones, are training-free and easily integrated as a plug-and-play component in any classifier-free guided diffusion model. Project page is available at \url{https://nulltextforcartoon.github.io/}.
MagicFusion: Boosting Text-to-Image Generation Performance by Fusing Diffusion Models
Mar 25, 2023The advent of open-source AI communities has produced a cornucopia of powerful text-guided diffusion models that are trained on various datasets. While few explorations have been conducted on ensembling such models to combine their strengths. In this work, we propose a simple yet effective method called Saliency-aware Noise Blending (SNB) that can empower the fused text-guided diffusion models to achieve more controllable generation. Specifically, we experimentally find that the responses of classifier-free guidance are highly related to the saliency of generated images. Thus we propose to trust different models in their areas of expertise by blending the predicted noises of two diffusion models in a saliency-aware manner. SNB is training-free and can be completed within a DDIM sampling process. Additionally, it can automatically align the semantics of two noise spaces without requiring additional annotations such as masks. Extensive experiments show the impressive effectiveness of SNB in various applications. Project page is available at https://magicfusion.github.io/.
Token Contrast for Weakly-Supervised Semantic Segmentation
Mar 02, 2023Weakly-Supervised Semantic Segmentation (WSSS) using image-level labels typically utilizes Class Activation Map (CAM) to generate the pseudo labels. Limited by the local structure perception of CNN, CAM usually cannot identify the integral object regions. Though the recent Vision Transformer (ViT) can remedy this flaw, we observe it also brings the over-smoothing issue, \ie, the final patch tokens incline to be uniform. In this work, we propose Token Contrast (ToCo) to address this issue and further explore the virtue of ViT for WSSS. Firstly, motivated by the observation that intermediate layers in ViT can still retain semantic diversity, we designed a Patch Token Contrast module (PTC). PTC supervises the final patch tokens with the pseudo token relations derived from intermediate layers, allowing them to align the semantic regions and thus yield more accurate CAM. Secondly, to further differentiate the low-confidence regions in CAM, we devised a Class Token Contrast module (CTC) inspired by the fact that class tokens in ViT can capture high-level semantics. CTC facilitates the representation consistency between uncertain local regions and global objects by contrasting their class tokens. Experiments on the PASCAL VOC and MS COCO datasets show the proposed ToCo can remarkably surpass other single-stage competitors and achieve comparable performance with state-of-the-art multi-stage methods. Code is available at https://github.com/rulixiang/ToCo.
OmniForce: On Human-Centered, Large Model Empowered and Cloud-Edge Collaborative AutoML System
Mar 01, 2023



Automated machine learning (AutoML) seeks to build ML models with minimal human effort. While considerable research has been conducted in the area of AutoML in general, aiming to take humans out of the loop when building artificial intelligence (AI) applications, scant literature has focused on how AutoML works well in open-environment scenarios such as the process of training and updating large models, industrial supply chains or the industrial metaverse, where people often face open-loop problems during the search process: they must continuously collect data, update data and models, satisfy the requirements of the development and deployment environment, support massive devices, modify evaluation metrics, etc. Addressing the open-environment issue with pure data-driven approaches requires considerable data, computing resources, and effort from dedicated data engineers, making current AutoML systems and platforms inefficient and computationally intractable. Human-computer interaction is a practical and feasible way to tackle the problem of open-environment AI. In this paper, we introduce OmniForce, a human-centered AutoML (HAML) system that yields both human-assisted ML and ML-assisted human techniques, to put an AutoML system into practice and build adaptive AI in open-environment scenarios. Specifically, we present OmniForce in terms of ML version management; pipeline-driven development and deployment collaborations; a flexible search strategy framework; and widely provisioned and crowdsourced application algorithms, including large models. Furthermore, the (large) models constructed by OmniForce can be automatically turned into remote services in a few minutes; this process is dubbed model as a service (MaaS). Experimental results obtained in multiple search spaces and real-world use cases demonstrate the efficacy and efficiency of OmniForce.
Domain Re-Modulation for Few-Shot Generative Domain Adaptation
Feb 07, 2023In this study, we investigate the task of few-shot Generative Domain Adaptation (GDA), which involves transferring a pre-trained generator from one domain to a new domain using one or a few reference images. Building upon previous research that has focused on Target-domain Consistency, Large Diversity, and Cross-domain Consistency, we conclude two additional desired properties for GDA: Memory and Domain Association. To meet these properties, we proposed a novel method Domain Re-Modulation (DoRM). Specifically, DoRM freezes the source generator and employs additional mapping and affine modules (M&A module) to capture the attributes of the target domain, resulting in a linearly combinable domain shift in style space. This allows for high-fidelity multi-domain and hybrid-domain generation by integrating multiple M&A modules in a single generator. DoRM is lightweight and easy to implement. Extensive experiments demonstrated the superior performance of DoRM on both one-shot and 10-shot GDA, both quantitatively and qualitatively. Additionally, for the first time, multi-domain and hybrid-domain generation can be achieved with a minimal storage cost by using a single model. The code will be available at https://github.com/wuyi2020/DoRM.