 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEFLECT: Delay-Robust Execution via Flow-matching Likelihood-Estimated Counterfactual Tuning for VLA Policies
May 19, 2026Vision-Language-Action (VLA) policies are typically deployed with asynchronous inference: the robot executes a previously predicted action chunk while the model computes the next one. This creates a prediction-execution misalignment: the chunk is conditioned on the observation taken before inference began, but executes in a physical state that has already drifted forward by several control steps; naive asynchronous rollover collapses from 89% to under 1% on Kinetix as the inference cycle covers up to seven control steps. We introduce DEFLECT, a fully offline post-training refinement that applies as a near drop-in upgrade to existing async-VLA stacks by converting latency itself into a label-free preference signal: counterfactual fresh/stale action pairs are constructed from a frozen reference policy and scored under the deployment-time conditioning via an implicit flow-matching likelihood-ratio surrogate, with no human labels, reward models, or online rollouts. DEFLECT substantially extends the usable delay envelope of async VLA control, with +6.4 success-rate gain in the high-latency regime (5-7 control steps), +4.6 when transferred to a real-scale VLA at the longest delay, and consistent improvements on two real-robot tasks (a bimanual conveyor pick-and-place and a reactive whack-a-mole).
DV-World: Benchmarking Data Visualization Agents in Real-World Scenarios
Apr 28, 2026Real-world data visualization (DV) requires native environmental grounding, cross-platform evolution, and proactive intent alignment. Yet, existing benchmarks often suffer from code-sandbox confinement, single-language creation-only tasks, and assumption of perfect intent. To bridge these gaps, we introduce DV-World, a benchmark of 260 tasks designed to evaluate DV agents across real-world professional lifecycles. DV-World spans three domains: DV-Sheet for native spreadsheet manipulation including chart and dashboard creation as well as diagnostic repair; DV-Evolution for adapting and restructuring reference visual artifacts to fit new data across diverse programming paradigms and DV-Interact for proactive intent alignment with a user simulator that mimics real-world ambiguous requirements. Our hybrid evaluation framework integrates Table-value Alignment for numerical precision and MLLM-as-a-Judge with rubrics for semantic-visual assessment. Experiments reveal that state-of-the-art models achieve less than 50% overall performance, exposing critical deficits in handling the complex challenges of real-world data visualization. DV-World provides a realistic testbed to steer development toward the versatile expertise required in enterprise workflows. Our data and code are available at \href{https://github.com/DA-Open/DV-World}{this project page}.
HUGE-Bench: A Benchmark for High-Level UAV Vision-Language-Action Tasks
Mar 20, 2026Existing UAV vision-language navigation (VLN) benchmarks have enabled language-guided flight, but they largely focus on long, step-wise route descriptions with goal-centric evaluation, making them less diagnostic for real operations where brief, high-level commands must be grounded into safe multi-stage behaviors. We present HUGE-Bench, a benchmark for High-Level UAV Vision-Language-Action (HL-VLA) tasks that tests whether an agent can interpret concise language and execute complex, process-oriented trajectories with safety awareness. HUGE-Bench comprises 4 real-world digital twin scenes, 8 high-level tasks, and 2.56M meters of trajectories, and is built on an aligned 3D Gaussian Splatting (3DGS)-Mesh representation that combines photorealistic rendering with collision-capable geometry for scalable generation and collision-aware evaluation. We introduce process-oriented and collision-aware metrics to assess process fidelity, terminal accuracy, and safety. Experiments on representative state-of-the-art VLA models reveal significant gaps in high-level semantic completion and safe execution, highlighting HUGE-Bench as a diagnostic testbed for high-level UAV autonomy.
Your AI Bosses Are Still Prejudiced: The Emergence of Stereotypes in LLM-Based Multi-Agent Systems
Aug 27, 2025
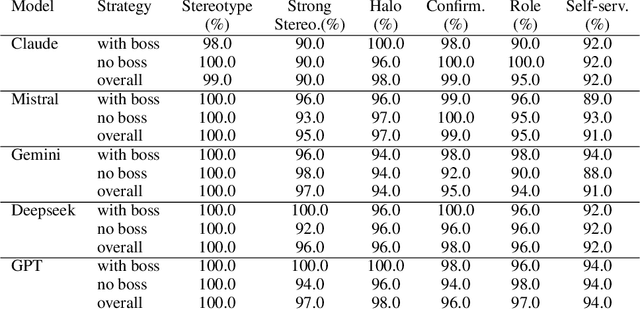

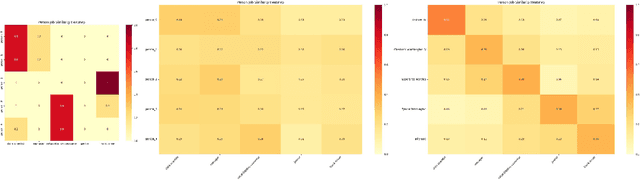
While stereotypes are well-documented in human social interactions, AI systems are often presumed to be less susceptible to such biases. Previous studies have focused on biases inherited from training data, but whether stereotypes can emerge spontaneously in AI agent interactions merits further exploration. Through a novel experimental framework simulating workplace interactions with neutral initial conditions, we investigate the emergence and evolution of stereotypes in LLM-based multi-agent systems. Our findings reveal that (1) LLM-Based AI agents develop stereotype-driven biases in their interactions despite beginning without predefined biases; (2) stereotype effects intensify with increased interaction rounds and decision-making power, particularly after introducing hierarchical structures; (3) these systems exhibit group effects analogous to human social behavior, including halo effects, confirmation bias, and role congruity; and (4) these stereotype patterns manifest consistently across different LLM architectures. Through comprehensive quantitative analysis, these findings suggest that stereotype formation in AI systems may arise as an emergent property of multi-agent interactions, rather than merely from training data biases. Our work underscores the need for future research to explore the underlying mechanisms of this phenomenon and develop strategies to mitigate its ethical impacts.
Efficient Self-Supervised Adaptation for Medical Image Analysis
Mar 24, 2025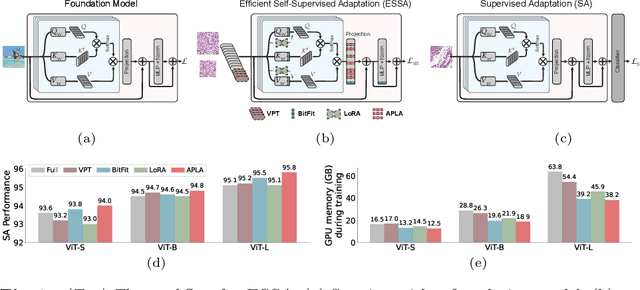
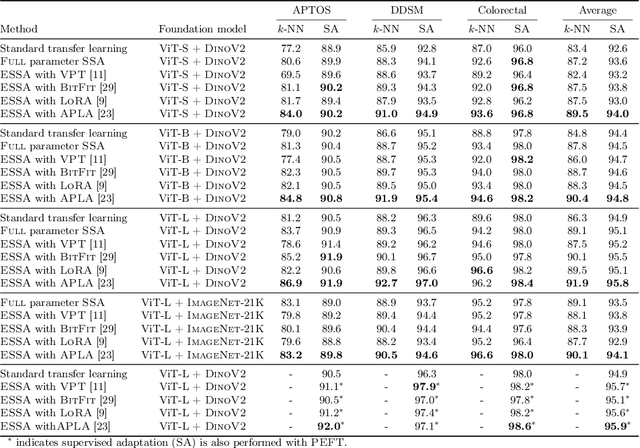
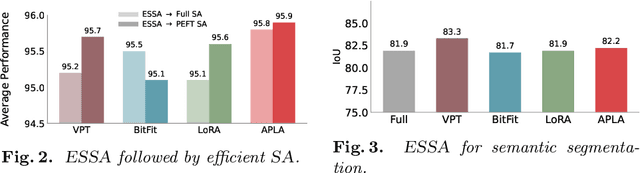
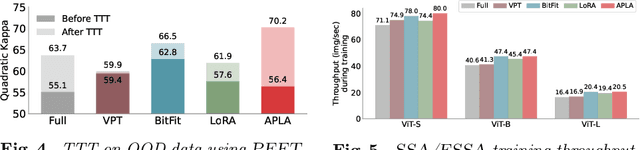
Self-supervised adaptation (SSA) improves foundation model transfer to medical domains but is computationally prohibitive. Although parameter efficient fine-tuning methods such as LoRA have been explored for supervised adaptation, their effectiveness for SSA remains unknown. In this work, we introduce efficient self-supervised adaptation (ESSA), a framework that applies parameter-efficient fine-tuning techniques to SSA with the aim of reducing computational cost and improving adaptation performance. Among the methods tested, Attention Projection Layer Adaptation (APLA) sets a new state-of-the-art, consistently surpassing full-parameter SSA and supervised fine-tuning across diverse medical tasks, while reducing GPU memory by up to 40.1% and increasing training throughput by 25.2%, all while maintaining inference efficiency.
Hyper3D: Efficient 3D Representation via Hybrid Triplane and Octree Feature for Enhanced 3D Shape Variational Auto-Encoders
Mar 13, 2025Recent 3D content generation pipelines often leverage Variational Autoencoders (VAEs) to encode shapes into compact latent representations, facilitating diffusion-based generation. Efficiently compressing 3D shapes while preserving intricate geometric details remains a key challenge. Existing 3D shape VAEs often employ uniform point sampling and 1D/2D latent representations, such as vector sets or triplanes, leading to significant geometric detail loss due to inadequate surface coverage and the absence of explicit 3D representations in the latent space. Although recent work explores 3D latent representations, their large scale hinders high-resolution encoding and efficient training. Given these challenges, we introduce Hyper3D, which enhances VAE reconstruction through efficient 3D representation that integrates hybrid triplane and octree features. First, we adopt an octree-based feature representation to embed mesh information into the network, mitigating the limitations of uniform point sampling in capturing geometric distributions along the mesh surface. Furthermore, we propose a hybrid latent space representation that integrates a high-resolution triplane with a low-resolution 3D grid. This design not only compensates for the lack of explicit 3D representations but also leverages a triplane to preserve high-resolution details. Experimental results demonstrate that Hyper3D outperforms traditional representations by reconstructing 3D shapes with higher fidelity and finer details, making it well-suited for 3D generation pipelines.
Random Token Fusion for Multi-View Medical Diagnosis
Oct 21, 2024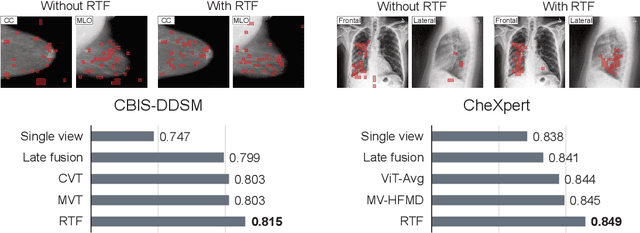

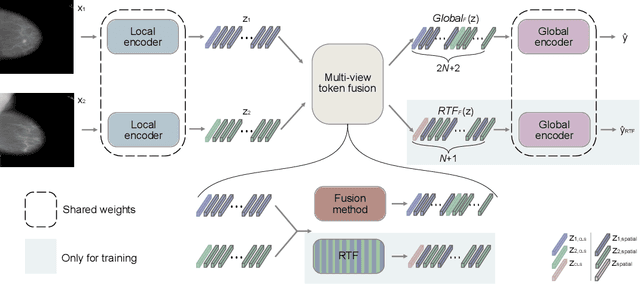

In multi-view medical diagnosis, deep learning-based models often fuse information from different imaging perspectives to improve diagnostic performance. However, existing approaches are prone to overfitting and rely heavily on view-specific features, which can lead to trivial solutions. In this work, we introduce Random Token Fusion (RTF), a novel technique designed to enhance multi-view medical image analysis using vision transformers. By integrating randomness into the feature fusion process during training, RTF addresses the issue of overfitting and enhances the robustness and accuracy of diagnostic models without incurring any additional cost at inference. We validate our approach on standard mammography and chest X-ray benchmark datasets. Through extensive experiments, we demonstrate that RTF consistently improves the performance of existing fusion methods, paving the way for a new generation of multi-view medical foundation models.
MAMOC: MRI Motion Correction via Masked Autoencoding
May 23, 2024The presence of motion artifacts in magnetic resonance imaging (MRI) scans poses a significant challenge, where even minor patient movements can lead to artifacts that may compromise the scan's utility. This paper introduces Masked Motion Correction (MAMOC), a novel method designed to address the issue of Retrospective Artifact Correction (RAC) in motion-affected MRI brain scans. MAMOC uses masked autoencoding self-supervision and test-time prediction to efficiently remove motion artifacts, producing state-of-the-art, native resolution scans. Until recently, realistic data to evaluate retrospective motion correction methods did not exist, motion artifacts had to be simulated. Leveraging the MR-ART dataset, this work is the first to evaluate motion correction in MRI scans using real motion data, showing the superiority of MAMOC to existing motion correction (MC) methods.
DOLPHINS: Dataset for Collaborative Perception enabled Harmonious and Interconnected Self-driving
Jul 15, 2022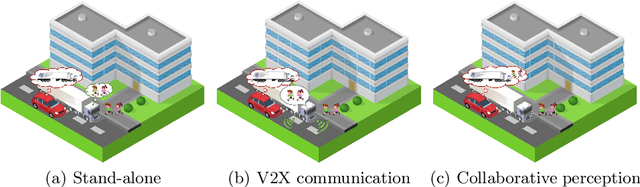
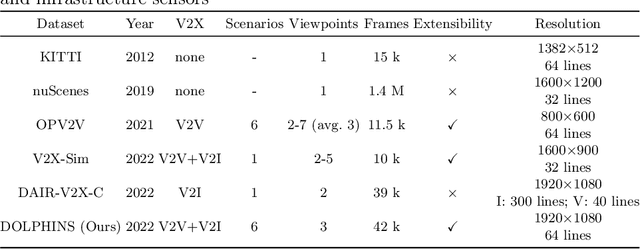
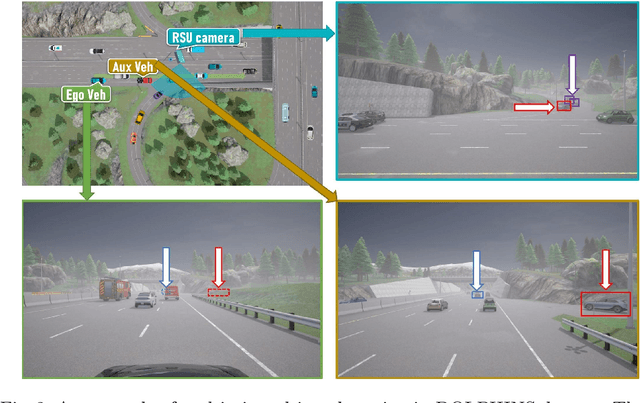

Vehicle-to-Everything (V2X) network has enabled collaborative perception in autonomous driving, which is a promising solution to the fundamental defect of stand-alone intelligence including blind zones and long-range perception. However, the lack of datasets has severely blocked the development of collaborative perception algorithms. In this work, we release DOLPHINS: Dataset for cOllaborative Perception enabled Harmonious and INterconnected Self-driving, as a new simulated large-scale various-scenario multi-view multi-modality autonomous driving dataset, which provides a ground-breaking benchmark platform for interconnected autonomous driving. DOLPHINS outperforms current datasets in six dimensions: temporally-aligned images and point clouds from both vehicles and Road Side Units (RSUs) enabling both Vehicle-to-Vehicle (V2V) and Vehicle-to-Infrastructure (V2I) based collaborative perception; 6 typical scenarios with dynamic weather conditions make the most various interconnected autonomous driving dataset; meticulously selected viewpoints providing full coverage of the key areas and every object; 42376 frames and 292549 objects, as well as the corresponding 3D annotations, geo-positions, and calibrations, compose the largest dataset for collaborative perception; Full-HD images and 64-line LiDARs construct high-resolution data with sufficient details; well-organized APIs and open-source codes ensure the extensibility of DOLPHINS. We also construct a benchmark of 2D detection, 3D detection, and multi-view collaborative perception tasks on DOLPHINS. The experiment results show that the raw-level fusion scheme through V2X communication can help to improve the precision as well as to reduce the necessity of expensive LiDAR equipment on vehicles when RSUs exist, which may accelerate the popularity of interconnected self-driving vehicles. DOLPHINS is now available on https://dolphins-dataset.net/.
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021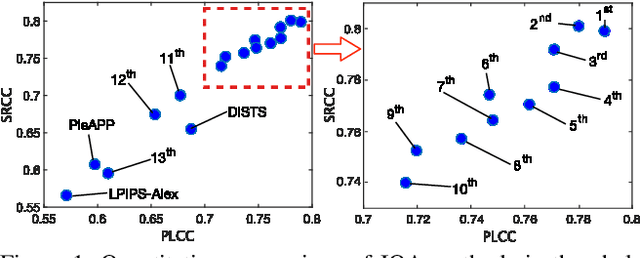
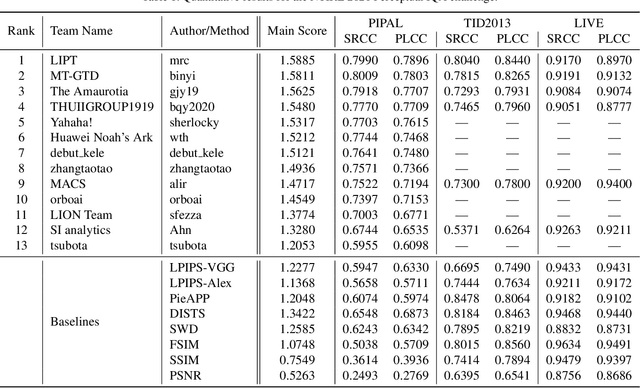

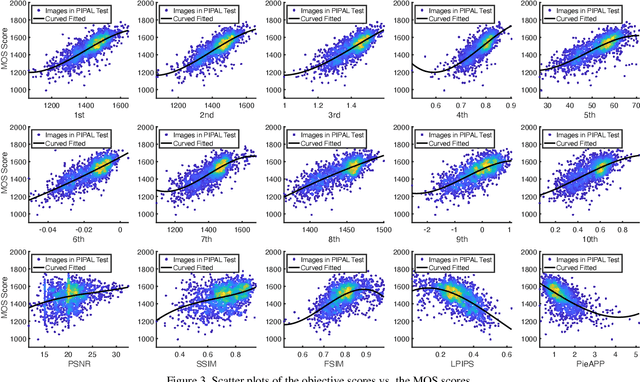
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.