 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cost of Reasoning: Chain-of-Thought Induces Overconfidence in Vision-Language Models
Mar 17, 2026Vision-language models (VLMs) are increasingly deployed in high-stakes settings where reliable uncertainty quantification (UQ) is as important as predictive accuracy. Extended reasoning via chain-of-thought (CoT) prompting or reasoning-trained models has become ubiquitous in modern VLM pipelines, yet its effect on UQ reliability remains poorly understood. We show that reasoning consistently degrades the quality of most uncertainty estimates, even when it improves task accuracy. We identify implicit answer conditioning as the primary mechanism: as reasoning traces converge on a conclusion before the final answer is generated, token probabilities increasingly reflect consistency with the model's own reasoning trace rather than uncertainty about correctness. In effect, the model becomes overconfident in its answer. In contrast, agreement-based consistency remains robust and often improves under reasoning, making it a practical choice for uncertainty estimation in reasoning-enabled VLMs.
Efficient Self-Supervised Adaptation for Medical Image Analysis
Mar 24, 2025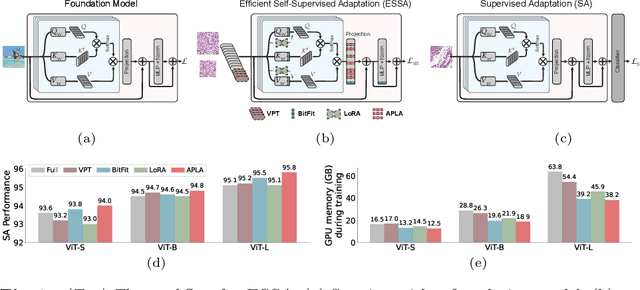
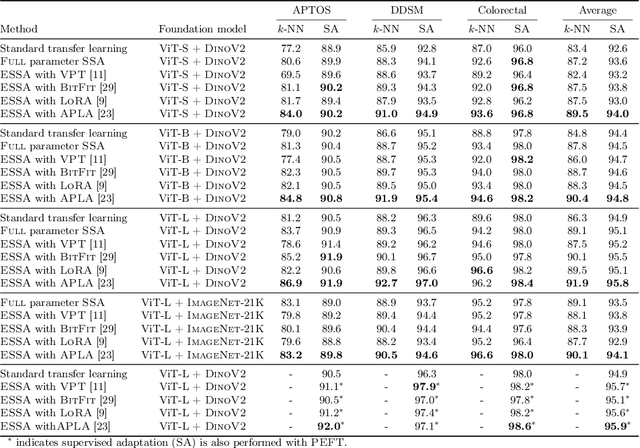
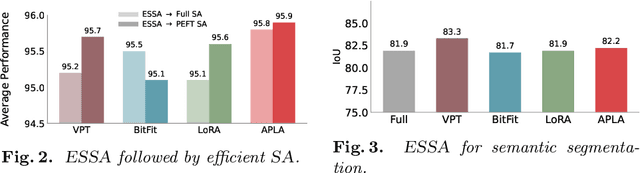
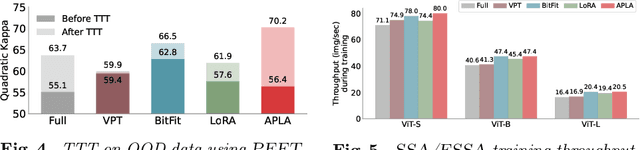
Self-supervised adaptation (SSA) improves foundation model transfer to medical domains but is computationally prohibitive. Although parameter efficient fine-tuning methods such as LoRA have been explored for supervised adaptation, their effectiveness for SSA remains unknown. In this work, we introduce efficient self-supervised adaptation (ESSA), a framework that applies parameter-efficient fine-tuning techniques to SSA with the aim of reducing computational cost and improving adaptation performance. Among the methods tested, Attention Projection Layer Adaptation (APLA) sets a new state-of-the-art, consistently surpassing full-parameter SSA and supervised fine-tuning across diverse medical tasks, while reducing GPU memory by up to 40.1% and increasing training throughput by 25.2%, all while maintaining inference efficiency.
APLA: A Simple Adaptation Method for Vision Transformers
Mar 14, 2025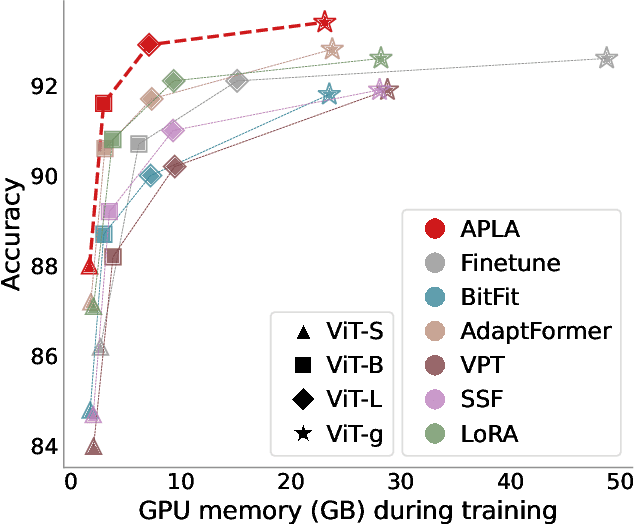
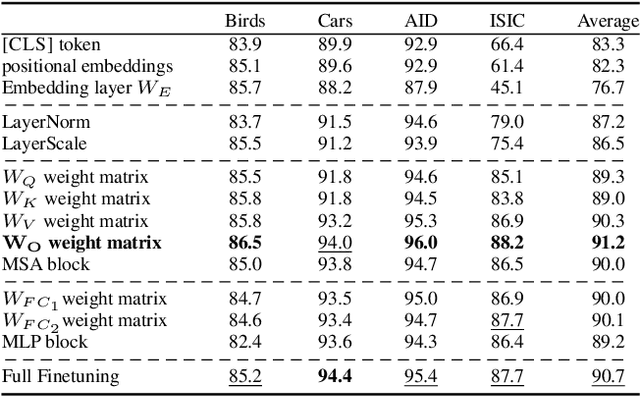
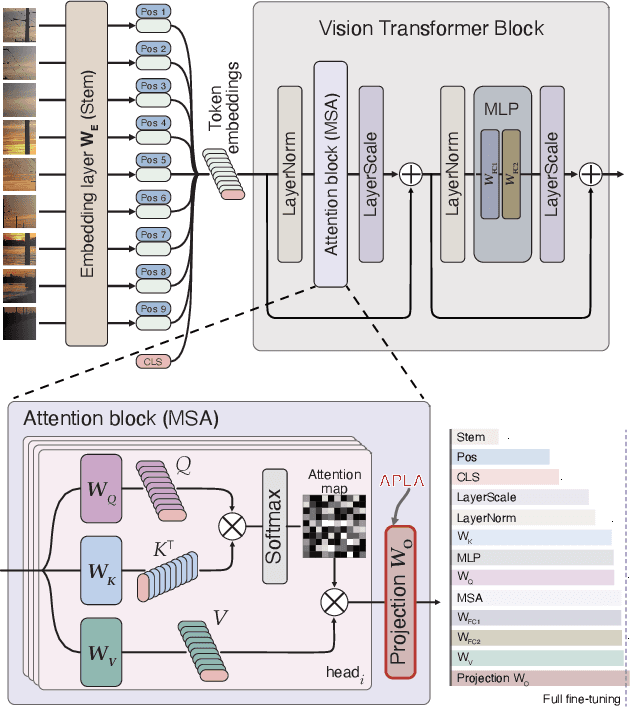
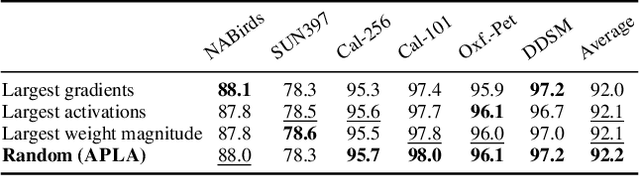
Existing adaptation techniques typically require architectural modifications or added parameters, leading to high computational costs and complexity. We introduce Attention Projection Layer Adaptation (APLA), a simple approach to adapt vision transformers (ViTs) without altering the architecture or adding parameters. Through a systematic analysis, we find that the layer immediately after the attention mechanism is crucial for adaptation. By updating only this projection layer, or even just a random subset of this layer's weights, APLA achieves state-of-the-art performance while reducing GPU memory usage by up to 52.63% and training time by up to 43.0%, with no extra cost at inference. Across 46 datasets covering a variety of tasks including scene classification, medical imaging, satellite imaging, and fine-grained classification, APLA consistently outperforms 17 other leading adaptation methods, including full fine-tuning, on classification, segmentation, and detection tasks. The code is available at https://github.com/MoeinSorkhei/APLA.
VORTEX: Challenging CNNs at Texture Recognition by using Vision Transformers with Orderless and Randomized Token Encodings
Mar 09, 2025



Texture recognition has recently been dominated by ImageNet-pre-trained deep Convolutional Neural Networks (CNNs), with specialized modifications and feature engineering required to achieve state-of-the-art (SOTA) performance. However, although Vision Transformers (ViTs) were introduced a few years ago, little is known about their texture recognition ability. Therefore, in this work, we introduce VORTEX (ViTs with Orderless and Randomized Token Encodings for Texture Recognition), a novel method that enables the effective use of ViTs for texture analysis. VORTEX extracts multi-depth token embeddings from pre-trained ViT backbones and employs a lightweight module to aggregate hierarchical features and perform orderless encoding, obtaining a better image representation for texture recognition tasks. This approach allows seamless integration with any ViT with the common transformer architecture. Moreover, no fine-tuning of the backbone is performed, since they are used only as frozen feature extractors, and the features are fed to a linear SVM. We evaluate VORTEX on nine diverse texture datasets, demonstrating its ability to achieve or surpass SOTA performance in a variety of texture analysis scenarios. By bridging the gap between texture recognition with CNNs and transformer-based architectures, VORTEX paves the way for adopting emerging transformer foundation models. Furthermore, VORTEX demonstrates robust computational efficiency when coupled with ViT backbones compared to CNNs with similar costs. The method implementation and experimental scripts are publicly available in our online repository.
Learning from Offline Foundation Features with Tensor Augmentations
Oct 03, 2024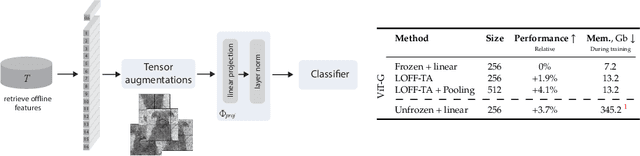
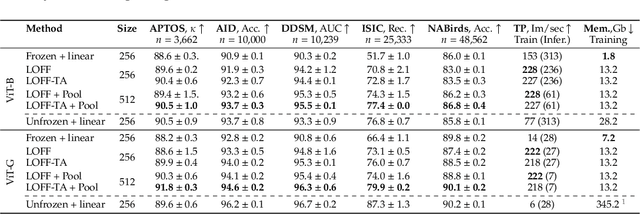
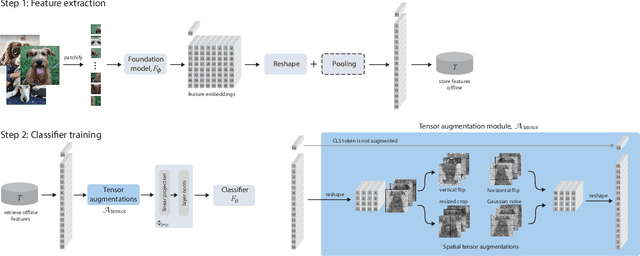
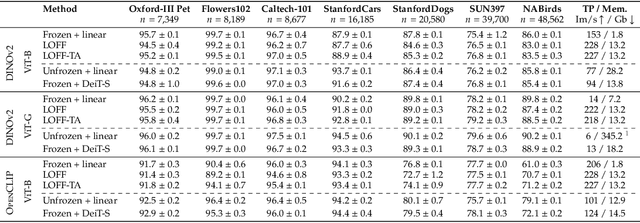
We introduce Learning from Offline Foundation Features with Tensor Augmentations (LOFF-TA), an efficient training scheme designed to harness the capabilities of foundation models in limited resource settings where their direct development is not feasible. LOFF-TA involves training a compact classifier on cached feature embeddings from a frozen foundation model, resulting in up to $37\times$ faster training and up to $26\times$ reduced GPU memory usage. Because the embeddings of augmented images would be too numerous to store, yet the augmentation process is essential for training, we propose to apply tensor augmentations to the cached embeddings of the original non-augmented images. LOFF-TA makes it possible to leverage the power of foundation models, regardless of their size, in settings with limited computational capacity. Moreover, LOFF-TA can be used to apply foundation models to high-resolution images without increasing compute. In certain scenarios, we find that training with LOFF-TA yields better results than directly fine-tuning the foundation model.
Adding Seemingly Uninformative Labels Helps in Low Data Regimes
Aug 11, 2020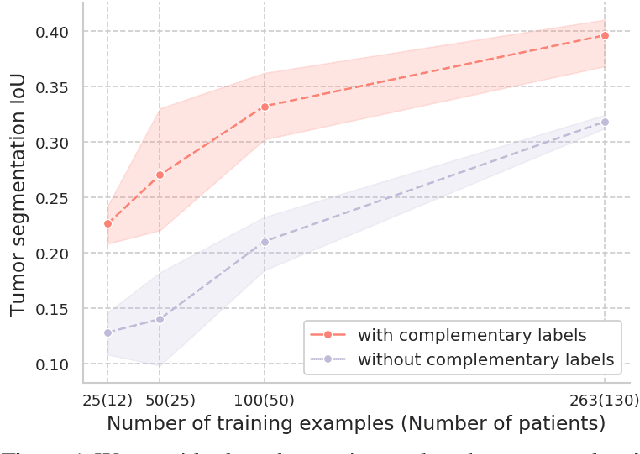
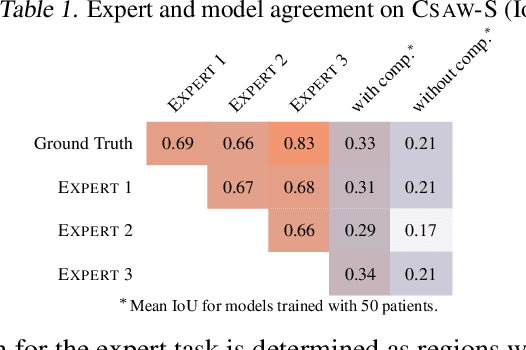
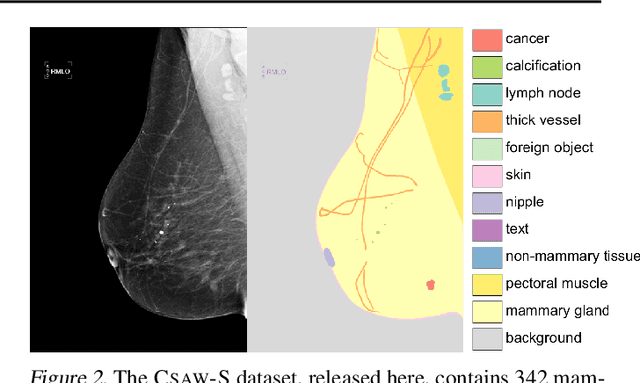

Evidence suggests that networks trained on large datasets generalize well not solely because of the numerous training examples, but also class diversity which encourages learning of enriched features. This raises the question of whether this remains true when data is scarce - is there an advantage to learning with additional labels in low-data regimes? In this work, we consider a task that requires difficult-to-obtain expert annotations: tumor segmentation in mammography images. We show that, in low-data settings, performance can be improved by complementing the expert annotations with seemingly uninformative labels from non-expert annotators, turning the task into a multi-class problem. We reveal that these gains increase when less expert data is available, and uncover several interesting properties through further studies. We demonstrate our findings on CSAW-S, a new dataset that we introduce here, and confirm them on two public datasets.
An empirical study of the relation between network architecture and complexity
Nov 11, 2019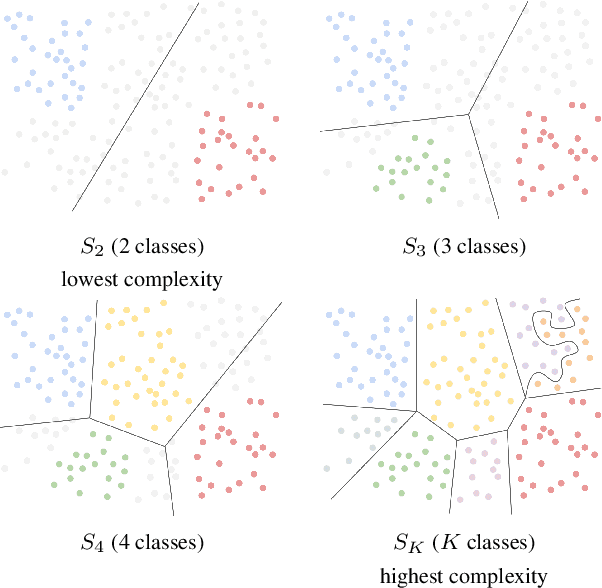
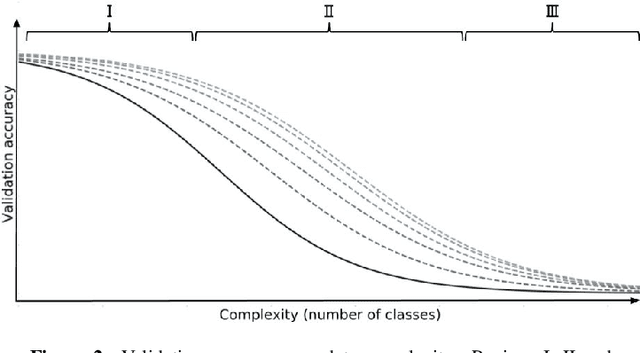
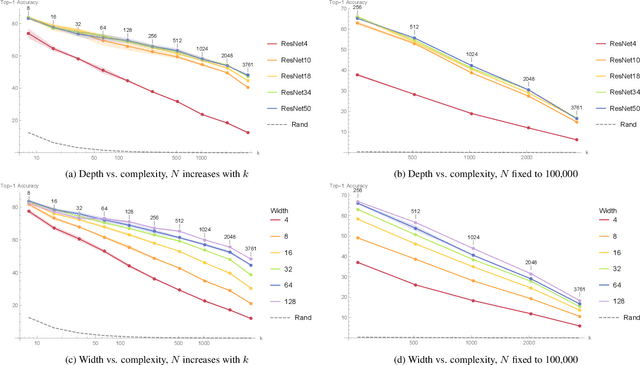
In this preregistration submission, we propose an empirical study of how networks handle changes in complexity of the data. We investigate the effect of network capacity on generalization performance in the face of increasing data complexity. For this, we measure the generalization error for an image classification task where the number of classes steadily increases. We compare a number of modern architectures at different scales in this setting. The methodology, setup, and hypotheses described in this proposal were evaluated by peer review before experiments were conducted.