 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer
Dec 02, 2021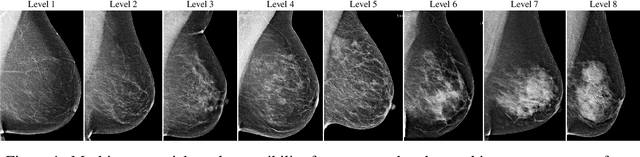

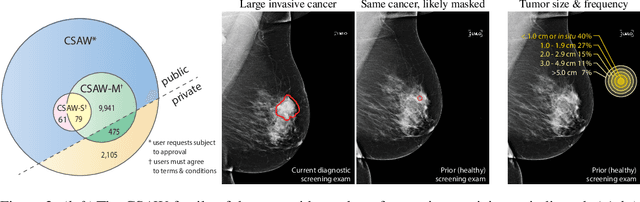

Interval and large invasive breast cancers, which are associated with worse prognosis than other cancers, are usually detected at a late stage due to false negative assessments of screening mammograms. The missed screening-time detection is commonly caused by the tumor being obscured by its surrounding breast tissues, a phenomenon called masking. To study and benchmark mammographic masking of cancer, in this work we introduce CSAW-M, the largest public mammographic dataset, collected from over 10,000 individuals and annotated with potential masking. In contrast to the previous approaches which measure breast image density as a proxy, our dataset directly provides annotations of masking potential assessments from five specialists. We also trained deep learning models on CSAW-M to estimate the masking level and showed that the estimated masking is significantly more predictive of screening participants diagnosed with interval and large invasive cancers -- without being explicitly trained for these tasks -- than its breast density counterparts.
Adding Seemingly Uninformative Labels Helps in Low Data Regimes
Aug 11, 2020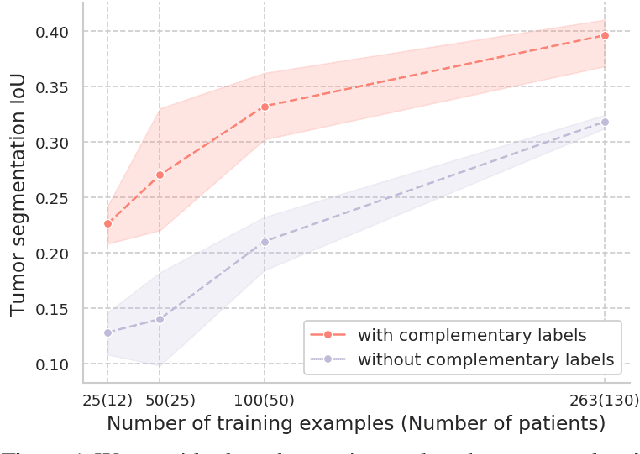
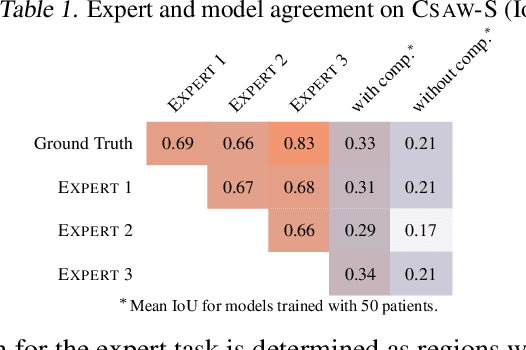
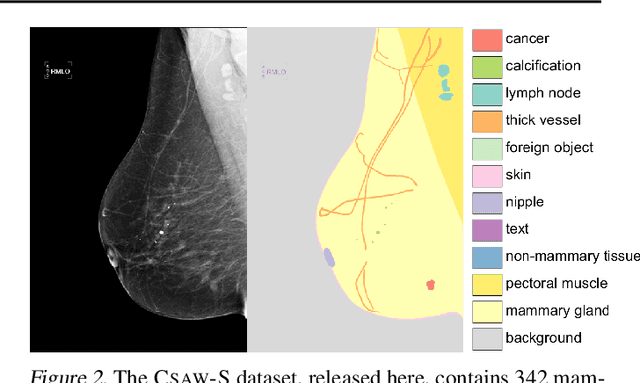

Evidence suggests that networks trained on large datasets generalize well not solely because of the numerous training examples, but also class diversity which encourages learning of enriched features. This raises the question of whether this remains true when data is scarce - is there an advantage to learning with additional labels in low-data regimes? In this work, we consider a task that requires difficult-to-obtain expert annotations: tumor segmentation in mammography images. We show that, in low-data settings, performance can be improved by complementing the expert annotations with seemingly uninformative labels from non-expert annotators, turning the task into a multi-class problem. We reveal that these gains increase when less expert data is available, and uncover several interesting properties through further studies. We demonstrate our findings on CSAW-S, a new dataset that we introduce here, and confirm them on two public datasets.