 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Self-Supervised Adaptation for Medical Image Analysis
Mar 24, 2025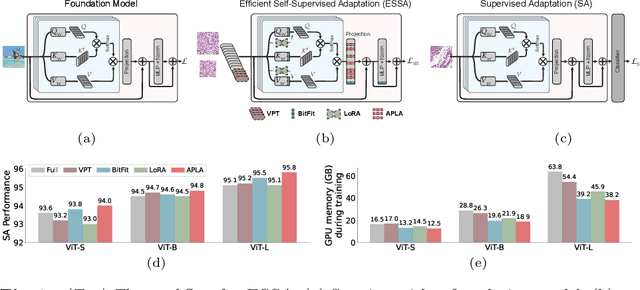
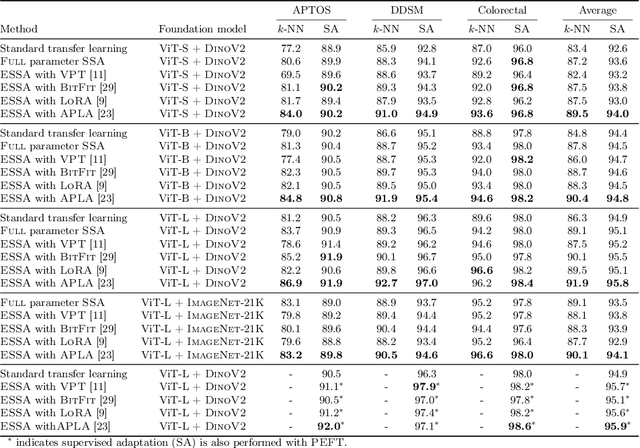
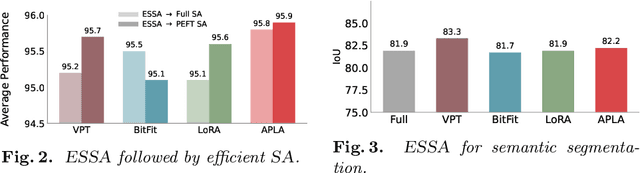
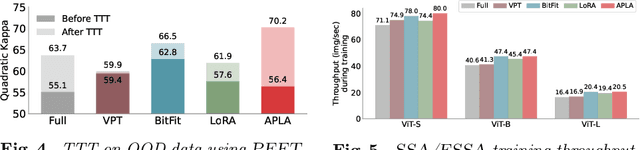
Self-supervised adaptation (SSA) improves foundation model transfer to medical domains but is computationally prohibitive. Although parameter efficient fine-tuning methods such as LoRA have been explored for supervised adaptation, their effectiveness for SSA remains unknown. In this work, we introduce efficient self-supervised adaptation (ESSA), a framework that applies parameter-efficient fine-tuning techniques to SSA with the aim of reducing computational cost and improving adaptation performance. Among the methods tested, Attention Projection Layer Adaptation (APLA) sets a new state-of-the-art, consistently surpassing full-parameter SSA and supervised fine-tuning across diverse medical tasks, while reducing GPU memory by up to 40.1% and increasing training throughput by 25.2%, all while maintaining inference efficiency.
APLA: A Simple Adaptation Method for Vision Transformers
Mar 14, 2025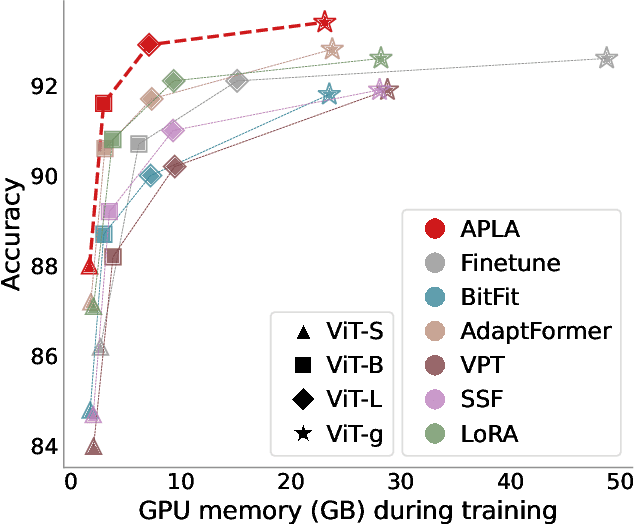
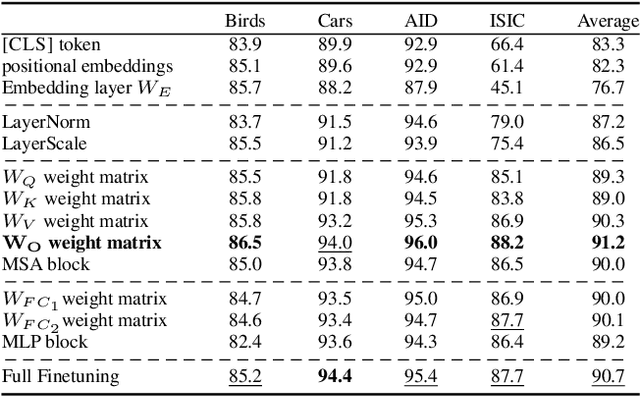
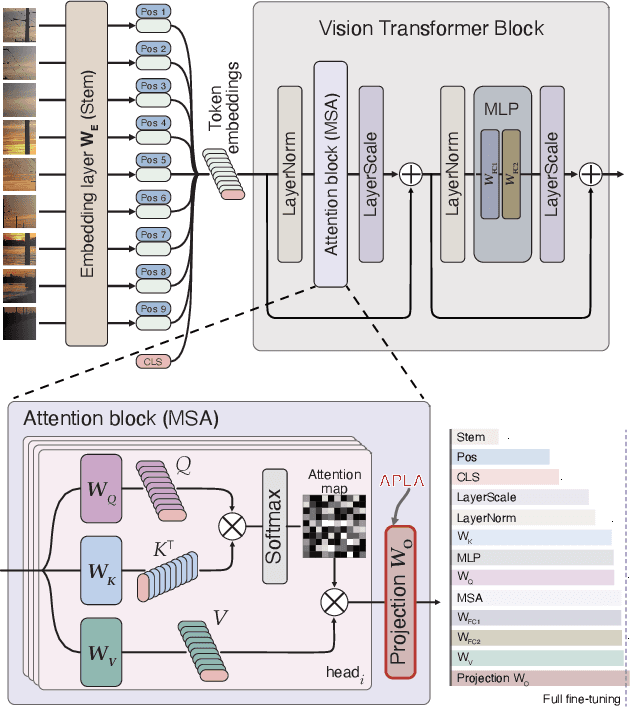
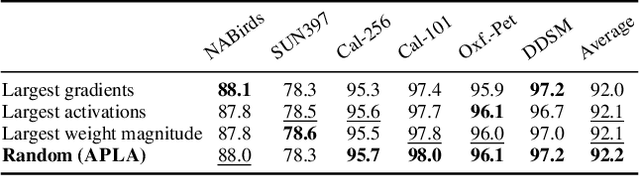
Existing adaptation techniques typically require architectural modifications or added parameters, leading to high computational costs and complexity. We introduce Attention Projection Layer Adaptation (APLA), a simple approach to adapt vision transformers (ViTs) without altering the architecture or adding parameters. Through a systematic analysis, we find that the layer immediately after the attention mechanism is crucial for adaptation. By updating only this projection layer, or even just a random subset of this layer's weights, APLA achieves state-of-the-art performance while reducing GPU memory usage by up to 52.63% and training time by up to 43.0%, with no extra cost at inference. Across 46 datasets covering a variety of tasks including scene classification, medical imaging, satellite imaging, and fine-grained classification, APLA consistently outperforms 17 other leading adaptation methods, including full fine-tuning, on classification, segmentation, and detection tasks. The code is available at https://github.com/MoeinSorkhei/APLA.
Learning from Offline Foundation Features with Tensor Augmentations
Oct 03, 2024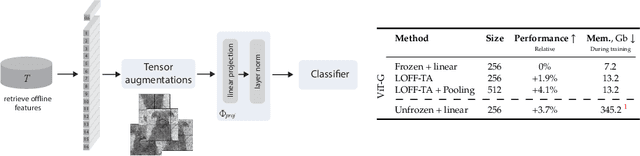
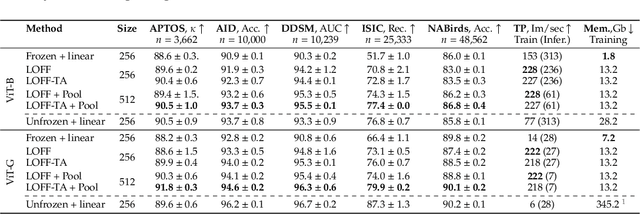
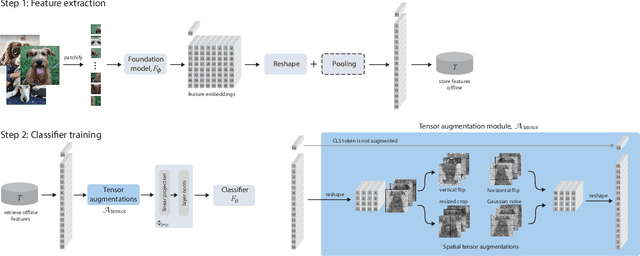
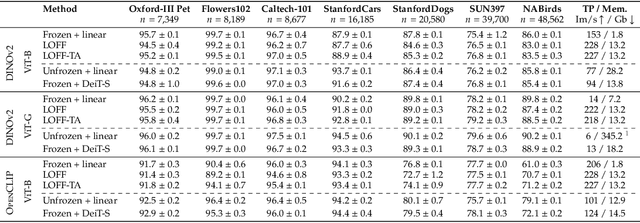
We introduce Learning from Offline Foundation Features with Tensor Augmentations (LOFF-TA), an efficient training scheme designed to harness the capabilities of foundation models in limited resource settings where their direct development is not feasible. LOFF-TA involves training a compact classifier on cached feature embeddings from a frozen foundation model, resulting in up to $37\times$ faster training and up to $26\times$ reduced GPU memory usage. Because the embeddings of augmented images would be too numerous to store, yet the augmentation process is essential for training, we propose to apply tensor augmentations to the cached embeddings of the original non-augmented images. LOFF-TA makes it possible to leverage the power of foundation models, regardless of their size, in settings with limited computational capacity. Moreover, LOFF-TA can be used to apply foundation models to high-resolution images without increasing compute. In certain scenarios, we find that training with LOFF-TA yields better results than directly fine-tuning the foundation model.
What Makes Transfer Learning Work For Medical Images: Feature Reuse & Other Factors
Mar 02, 2022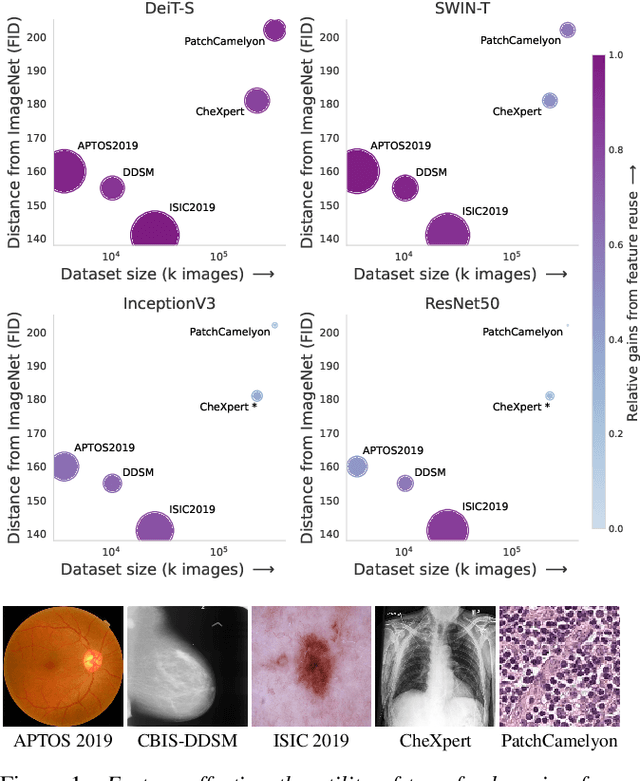
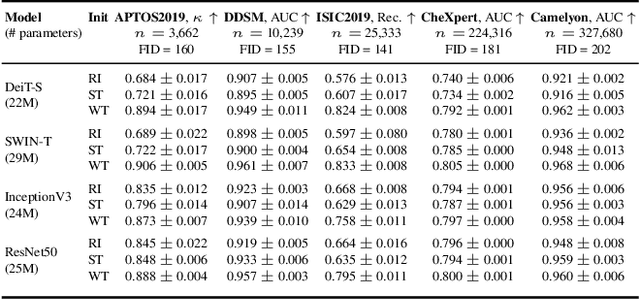
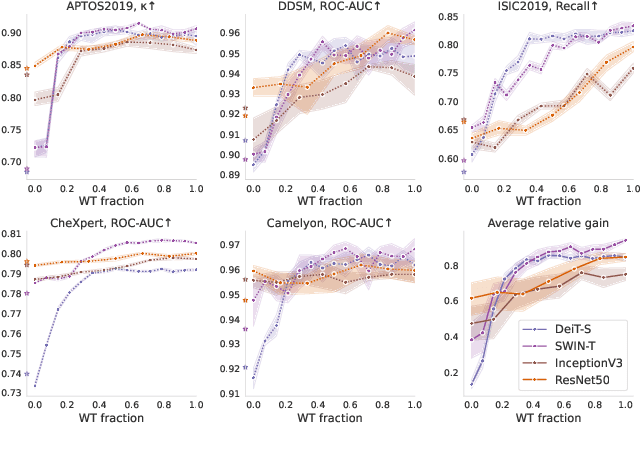
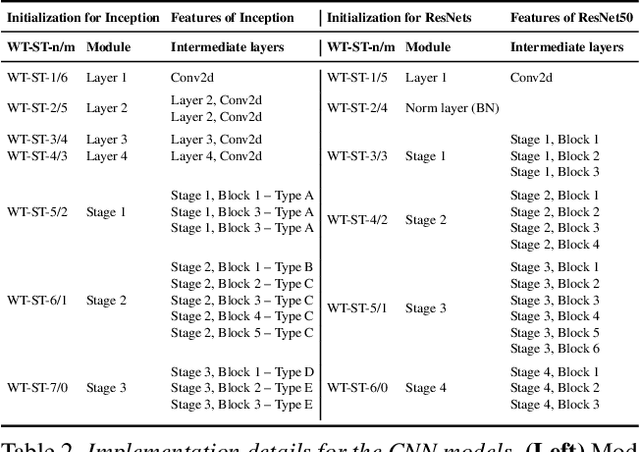
Transfer learning is a standard technique to transfer knowledge from one domain to another. For applications in medical imaging, transfer from ImageNet has become the de-facto approach, despite differences in the tasks and image characteristics between the domains. However, it is unclear what factors determine whether - and to what extent - transfer learning to the medical domain is useful. The long-standing assumption that features from the source domain get reused has recently been called into question. Through a series of experiments on several medical image benchmark datasets, we explore the relationship between transfer learning, data size, the capacity and inductive bias of the model, as well as the distance between the source and target domain. Our findings suggest that transfer learning is beneficial in most cases, and we characterize the important role feature reuse plays in its success.
CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer
Dec 02, 2021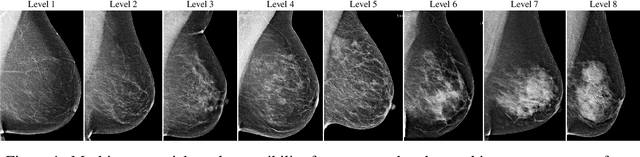

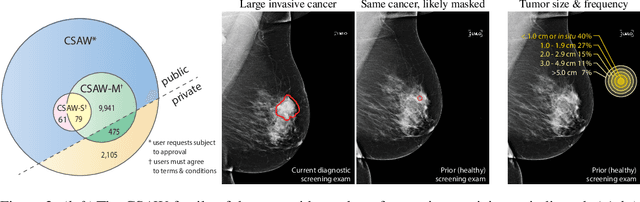

Interval and large invasive breast cancers, which are associated with worse prognosis than other cancers, are usually detected at a late stage due to false negative assessments of screening mammograms. The missed screening-time detection is commonly caused by the tumor being obscured by its surrounding breast tissues, a phenomenon called masking. To study and benchmark mammographic masking of cancer, in this work we introduce CSAW-M, the largest public mammographic dataset, collected from over 10,000 individuals and annotated with potential masking. In contrast to the previous approaches which measure breast image density as a proxy, our dataset directly provides annotations of masking potential assessments from five specialists. We also trained deep learning models on CSAW-M to estimate the masking level and showed that the estimated masking is significantly more predictive of screening participants diagnosed with interval and large invasive cancers -- without being explicitly trained for these tasks -- than its breast density counterparts.
Full-Glow: Fully conditional Glow for more realistic image generation
Dec 10, 2020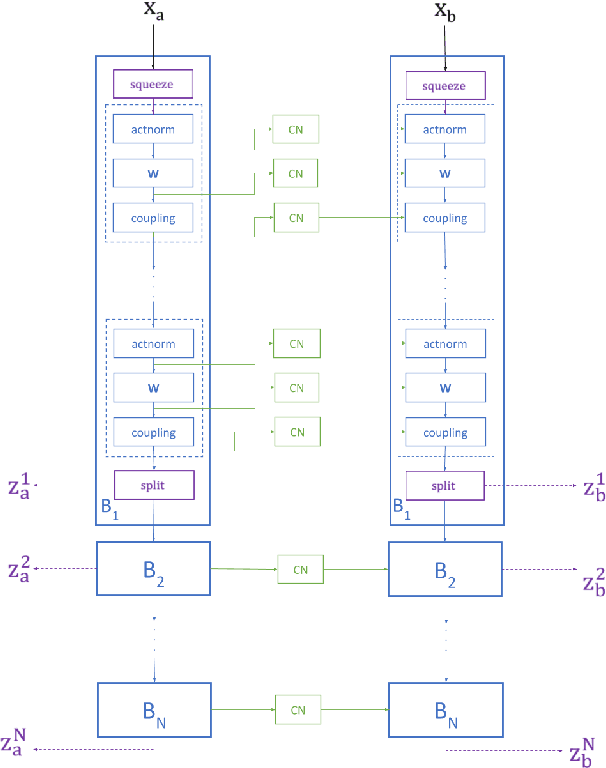
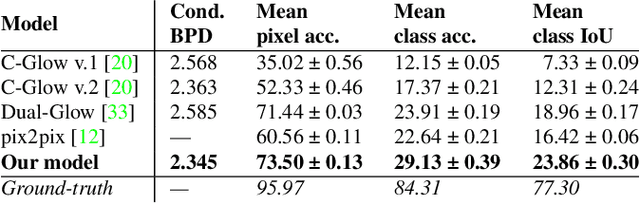


Autonomous agents, such as driverless cars, require large amounts of labeled visual data for their training. A viable approach for acquiring such data is training a generative model with collected real data, and then augmenting the collected real dataset with synthetic images from the model, generated with control of the scene layout and ground truth labeling. In this paper we propose Full-Glow, a fully conditional Glow-based architecture for generating plausible and realistic images of novel street scenes given a semantic segmentation map indicating the scene layout. Benchmark comparisons show our model to outperform recent works in terms of the semantic segmentation performance of a pretrained PSPNet. This indicates that images from our model are, to a higher degree than from other models, similar to real images of the same kinds of scenes and objects, making them suitable as training data for a visual semantic segmentation or object recognition system.