 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Natural Domain Foundation Models Useful for Medical Image Classification?
Oct 30, 2023
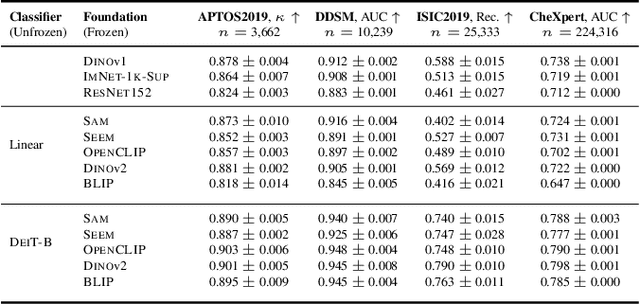
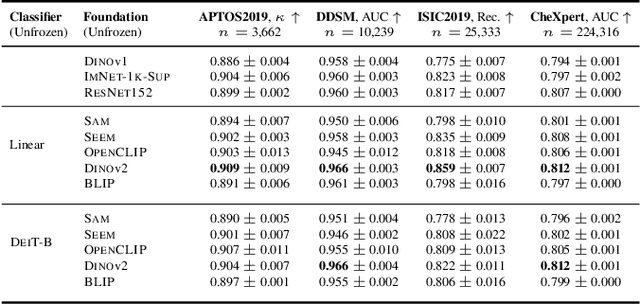

The deep learning field is converging towards the use of general foundation models that can be easily adapted for diverse tasks. While this paradigm shift has become common practice within the field of natural language processing, progress has been slower in computer vision. In this paper we attempt to address this issue by investigating the transferability of various state-of-the-art foundation models to medical image classification tasks. Specifically, we evaluate the performance of five foundation models, namely SAM, SEEM, DINOv2, BLIP, and OpenCLIP across four well-established medical imaging datasets. We explore different training settings to fully harness the potential of these models. Our study shows mixed results. DINOv2 in particular, consistently outperforms the standard practice of ImageNet pretraining. However, other foundation models failed to consistently beat this established baseline indicating limitations in their transferability to medical image classification tasks.
Pretrained ViTs Yield Versatile Representations For Medical Images
Mar 14, 2023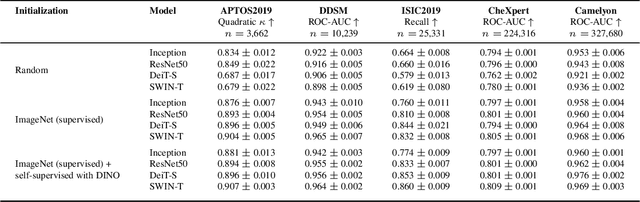
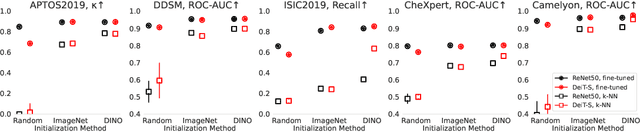

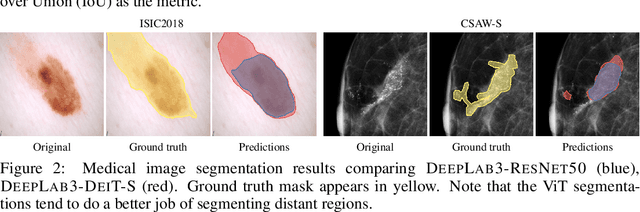
Convolutional Neural Networks (CNNs) have reigned for a decade as the de facto approach to automated medical image diagnosis, pushing the state-of-the-art in classification, detection and segmentation tasks. Over the last years, vision transformers (ViTs) have appeared as a competitive alternative to CNNs, yielding impressive levels of performance in the natural image domain, while possessing several interesting properties that could prove beneficial for medical imaging tasks. In this work, we explore the benefits and drawbacks of transformer-based models for medical image classification. We conduct a series of experiments on several standard 2D medical image benchmark datasets and tasks. Our findings show that, while CNNs perform better if trained from scratch, off-the-shelf vision transformers can perform on par with CNNs when pretrained on ImageNet, both in a supervised and self-supervised setting, rendering them as a viable alternative to CNNs.
What Makes Transfer Learning Work For Medical Images: Feature Reuse & Other Factors
Mar 02, 2022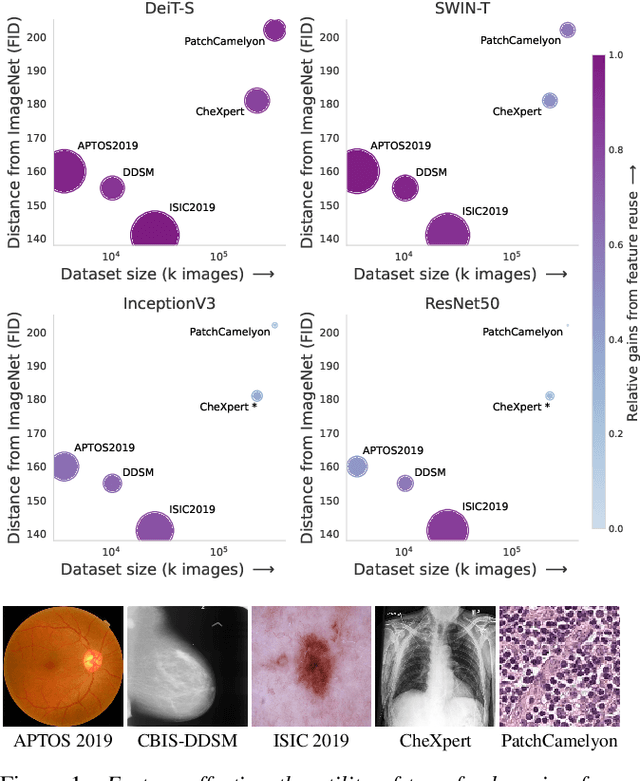
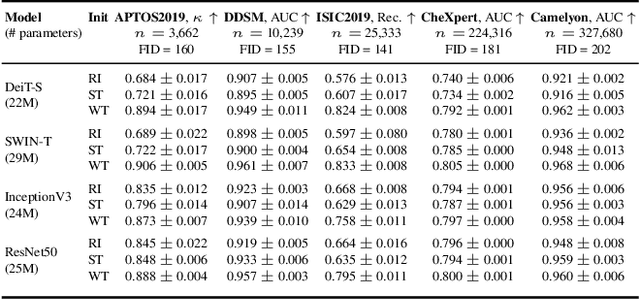
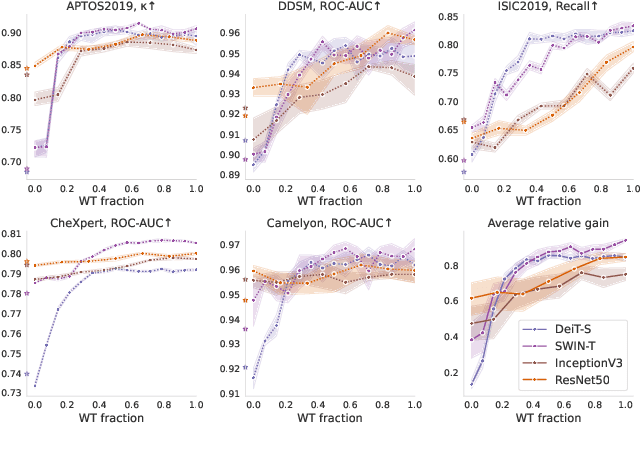
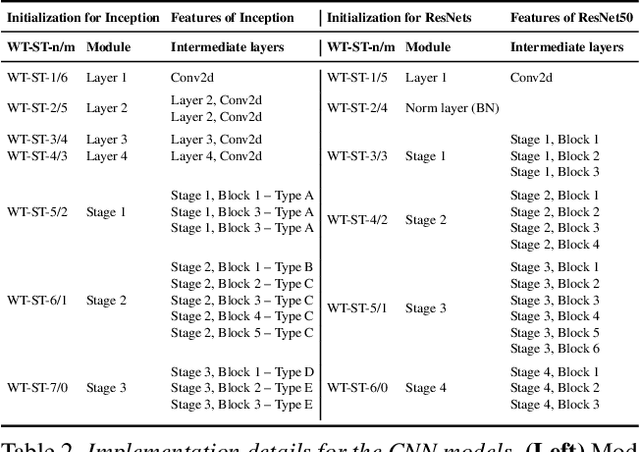
Transfer learning is a standard technique to transfer knowledge from one domain to another. For applications in medical imaging, transfer from ImageNet has become the de-facto approach, despite differences in the tasks and image characteristics between the domains. However, it is unclear what factors determine whether - and to what extent - transfer learning to the medical domain is useful. The long-standing assumption that features from the source domain get reused has recently been called into question. Through a series of experiments on several medical image benchmark datasets, we explore the relationship between transfer learning, data size, the capacity and inductive bias of the model, as well as the distance between the source and target domain. Our findings suggest that transfer learning is beneficial in most cases, and we characterize the important role feature reuse plays in its success.
Is it Time to Replace CNNs with Transformers for Medical Images?
Aug 20, 2021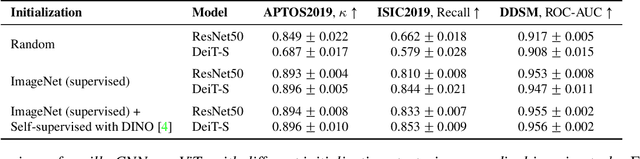
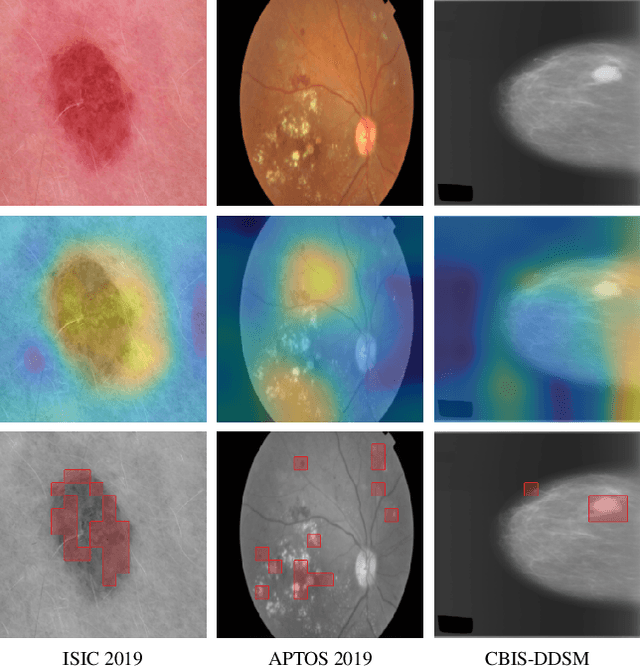
Convolutional Neural Networks (CNNs) have reigned for a decade as the de facto approach to automated medical image diagnosis. Recently, vision transformers (ViTs) have appeared as a competitive alternative to CNNs, yielding similar levels of performance while possessing several interesting properties that could prove beneficial for medical imaging tasks. In this work, we explore whether it is time to move to transformer-based models or if we should keep working with CNNs - can we trivially switch to transformers? If so, what are the advantages and drawbacks of switching to ViTs for medical image diagnosis? We consider these questions in a series of experiments on three mainstream medical image datasets. Our findings show that, while CNNs perform better when trained from scratch, off-the-shelf vision transformers using default hyperparameters are on par with CNNs when pretrained on ImageNet, and outperform their CNN counterparts when pretrained using self-supervision.