 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Self-Supervised Adaptation for Medical Image Analysis
Paper and Code
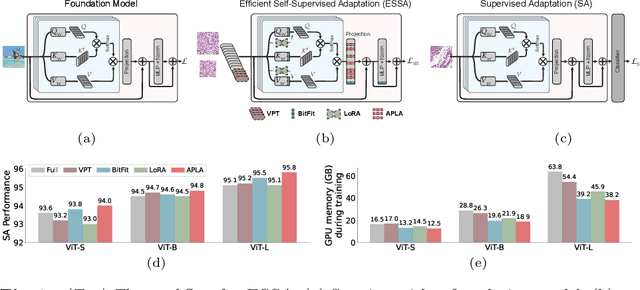
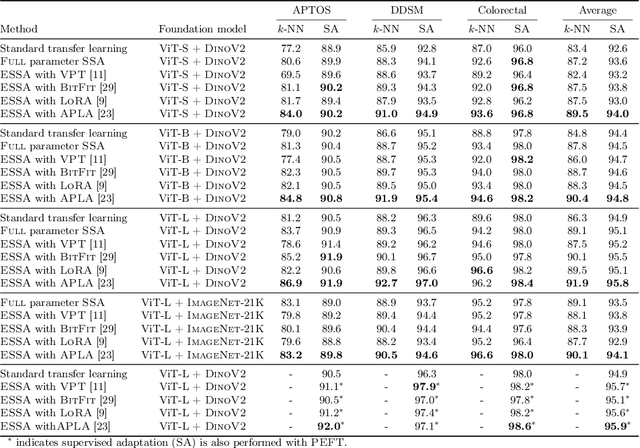
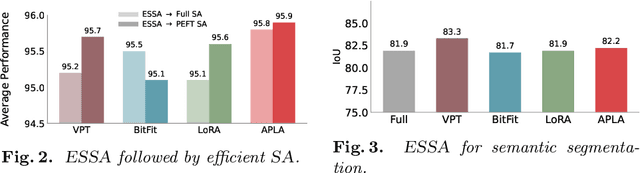
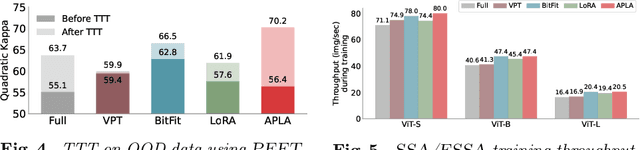
Self-supervised adaptation (SSA) improves foundation model transfer to medical domains but is computationally prohibitive. Although parameter efficient fine-tuning methods such as LoRA have been explored for supervised adaptation, their effectiveness for SSA remains unknown. In this work, we introduce efficient self-supervised adaptation (ESSA), a framework that applies parameter-efficient fine-tuning techniques to SSA with the aim of reducing computational cost and improving adaptation performance. Among the methods tested, Attention Projection Layer Adaptation (APLA) sets a new state-of-the-art, consistently surpassing full-parameter SSA and supervised fine-tuning across diverse medical tasks, while reducing GPU memory by up to 40.1% and increasing training throughput by 25.2%, all while maintaining inference efficiency.