 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new Time-decay Radiomics Integrated Network (TRINet) for short-term breast cancer risk prediction
Dec 04, 2024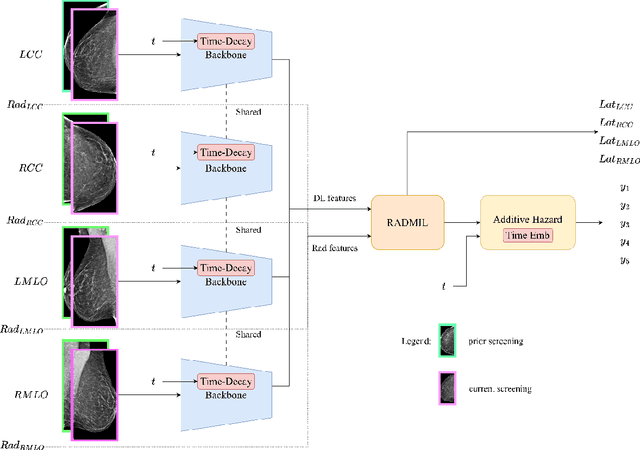
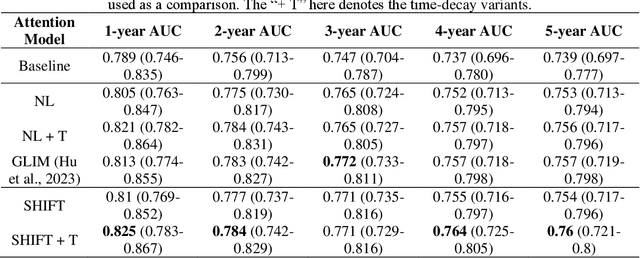
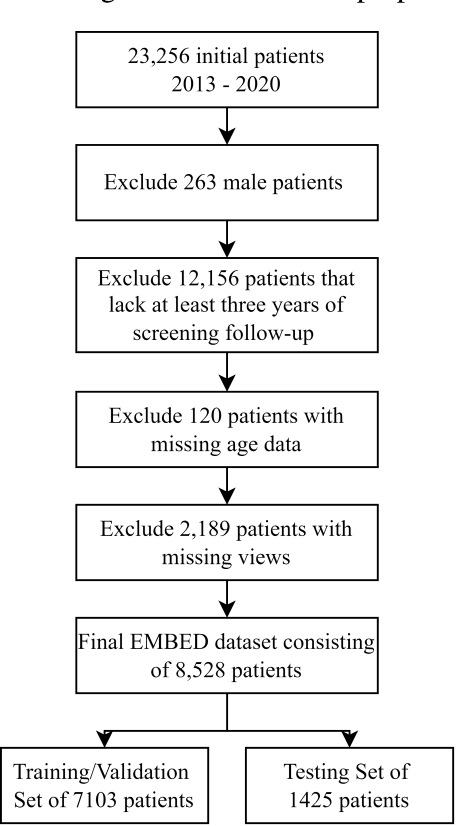
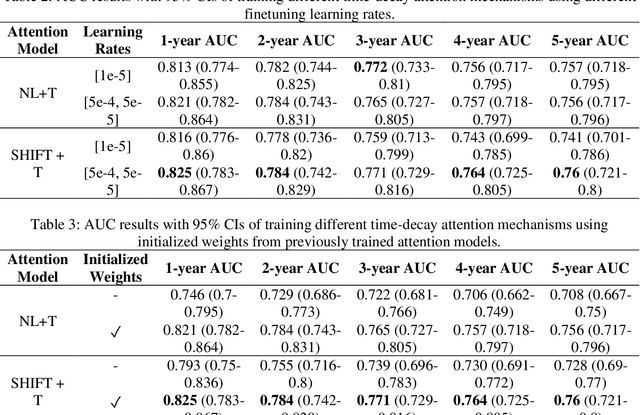
To facilitate early detection of breast cancer, there is a need to develop short-term risk prediction schemes that can prescribe personalized/individualized screening mammography regimens for women. In this study, we propose a new deep learning architecture called TRINet that implements time-decay attention to focus on recent mammographic screenings, as current models do not account for the relevance of newer images. We integrate radiomic features with an Attention-based Multiple Instance Learning (AMIL) framework to weigh and combine multiple views for better risk estimation. In addition, we introduce a continual learning approach with a new label assignment strategy based on bilateral asymmetry to make the model more adaptable to asymmetrical cancer indicators. Finally, we add a time-embedded additive hazard layer to perform dynamic, multi-year risk forecasting based on individualized screening intervals. We used two public datasets, namely 8,528 patients from the American EMBED dataset and 8,723 patients from the Swedish CSAW dataset in our experiments. Evaluation results on the EMBED test set show that our approach significantly outperforms state-of-the-art models, achieving AUC scores of 0.851, 0.811, 0.796, 0.793, and 0.789 across 1-, 2-, to 5-year intervals, respectively. Our results underscore the importance of integrating temporal attention, radiomic features, time embeddings, bilateral asymmetry, and continual learning strategies, providing a more adaptive and precise tool for short-term breast cancer risk prediction.
Artificial Intelligence-Informed Handheld Breast Ultrasound for Screening: A Systematic Review of Diagnostic Test Accuracy
Nov 11, 2024



Background. Breast cancer screening programs using mammography have led to significant mortality reduction in high-income countries. However, many low- and middle-income countries lack resources for mammographic screening. Handheld breast ultrasound (BUS) is a low-cost alternative but requires substantial training. Artificial intelligence (AI) enabled BUS may aid in both the detection (perception) and classification (interpretation) of breast cancer. Materials and Methods. This review (CRD42023493053) is reported in accordance with the PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analysis) and SWiM (Synthesis Without Meta-analysis) guidelines. PubMed and Google Scholar were searched from January 1, 2016 to December 12, 2023. A meta-analysis was not attempted. Studies are grouped according to their AI task type, application time, and AI task. Study quality is assessed using the QUality Assessment of Diagnostic Accuracy Studies-2 (QUADAS-2) tool. Results. Of 763 candidate studies, 314 total full texts were reviewed. 34 studies are included. The AI tasks of included studies are as follows: 1 frame selection, 6 detection, 11 segmentation, and 16 classification. In total, 5.7 million BUS images from over 185,000 patients were used for AI training or validation. A single study included a prospective testing set. 79% of studies were at high or unclear risk of bias. Conclusion. There has been encouraging development of AI for BUS. Despite studies demonstrating high performance across all identified tasks, the evidence supporting AI-enhanced BUS generally lacks robustness. High-quality model validation will be key to realizing the potential for AI-enhanced BUS in increasing access to screening in resource-limited environments.
Random Token Fusion for Multi-View Medical Diagnosis
Oct 21, 2024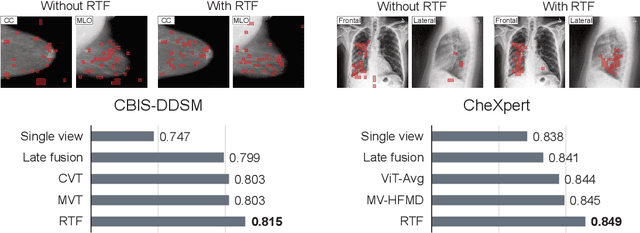

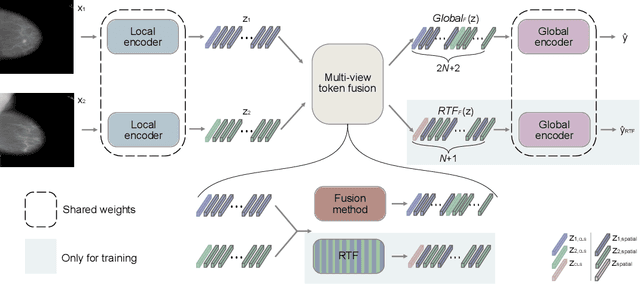

In multi-view medical diagnosis, deep learning-based models often fuse information from different imaging perspectives to improve diagnostic performance. However, existing approaches are prone to overfitting and rely heavily on view-specific features, which can lead to trivial solutions. In this work, we introduce Random Token Fusion (RTF), a novel technique designed to enhance multi-view medical image analysis using vision transformers. By integrating randomness into the feature fusion process during training, RTF addresses the issue of overfitting and enhances the robustness and accuracy of diagnostic models without incurring any additional cost at inference. We validate our approach on standard mammography and chest X-ray benchmark datasets. Through extensive experiments, we demonstrate that RTF consistently improves the performance of existing fusion methods, paving the way for a new generation of multi-view medical foundation models.
MAMA-MIA: A Large-Scale Multi-Center Breast Cancer DCE-MRI Benchmark Dataset with Expert Segmentations
Jun 19, 2024Current research in breast cancer Magnetic Resonance Imaging (MRI), especially with Artificial Intelligence (AI), faces challenges due to the lack of expert segmentations. To address this, we introduce the MAMA-MIA dataset, comprising 1506 multi-center dynamic contrast-enhanced MRI cases with expert segmentations of primary tumors and non-mass enhancement areas. These cases were sourced from four publicly available collections in The Cancer Imaging Archive (TCIA). Initially, we trained a deep learning model to automatically segment the cases, generating preliminary segmentations that significantly reduced expert segmentation time. Sixteen experts, averaging 9 years of experience in breast cancer, then corrected these segmentations, resulting in the final expert segmentations. Additionally, two radiologists conducted a visual inspection of the automatic segmentations to support future quality control studies. Alongside the expert segmentations, we provide 49 harmonized demographic and clinical variables and the pretrained weights of the well-known nnUNet architecture trained using the DCE-MRI full-images and expert segmentations. This dataset aims to accelerate the development and benchmarking of deep learning models and foster innovation in breast cancer diagnostics and treatment planning.
RADIFUSION: A multi-radiomics deep learning based breast cancer risk prediction model using sequential mammographic images with image attention and bilateral asymmetry refinement
Apr 01, 2023



Breast cancer is a significant public health concern and early detection is critical for triaging high risk patients. Sequential screening mammograms can provide important spatiotemporal information about changes in breast tissue over time. In this study, we propose a deep learning architecture called RADIFUSION that utilizes sequential mammograms and incorporates a linear image attention mechanism, radiomic features, a new gating mechanism to combine different mammographic views, and bilateral asymmetry-based finetuning for breast cancer risk assessment. We evaluate our model on a screening dataset called Cohort of Screen-Aged Women (CSAW) dataset. Based on results obtained on the independent testing set consisting of 1,749 women, our approach achieved superior performance compared to other state-of-the-art models with area under the receiver operating characteristic curves (AUCs) of 0.905, 0.872 and 0.866 in the three respective metrics of 1-year AUC, 2-year AUC and > 2-year AUC. Our study highlights the importance of incorporating various deep learning mechanisms, such as image attention, radiomic features, gating mechanism, and bilateral asymmetry-based fine-tuning, to improve the accuracy of breast cancer risk assessment. We also demonstrate that our model's performance was enhanced by leveraging spatiotemporal information from sequential mammograms. Our findings suggest that RADIFUSION can provide clinicians with a powerful tool for breast cancer risk assessment.
Visual Detection of Personal Protective Equipment and Safety Gear on Industry Workers
Dec 09, 2022



Workplace injuries are common in today's society due to a lack of adequately worn safety equipment. A system that only admits appropriately equipped personnel can be created to improve working conditions. The goal is thus to develop a system that will improve workers' safety using a camera that will detect the usage of Personal Protective Equipment (PPE). To this end, we collected and labeled appropriate data from several public sources, which have been used to train and evaluate several models based on the popular YOLOv4 object detector. Our focus, driven by a collaborating industrial partner, is to implement our system into an entry control point where workers must present themselves to obtain access to a restricted area. Combined with facial identity recognition, the system would ensure that only authorized people wearing appropriate equipment are granted access. A novelty of this work is that we increase the number of classes to five objects (hardhat, safety vest, safety gloves, safety glasses, and hearing protection), whereas most existing works only focus on one or two classes, usually hardhats or vests. The AI model developed provides good detection accuracy at a distance of 3 and 5 meters in the collaborative environment where we aim at operating (mAP of 99/89%, respectively). The small size of some objects or the potential occlusion by body parts have been identified as potential factors that are detrimental to accuracy, which we have counteracted via data augmentation and cropping of the body before applying PPE detection.
High-resolution synthesis of high-density breast mammograms: Application to improved fairness in deep learning based mass detection
Sep 20, 2022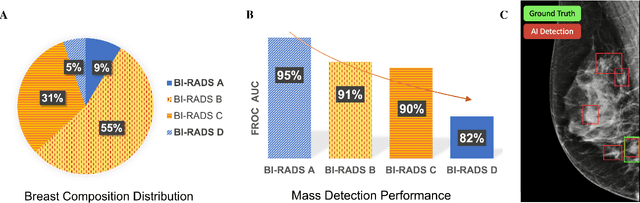
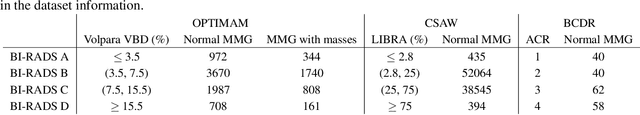
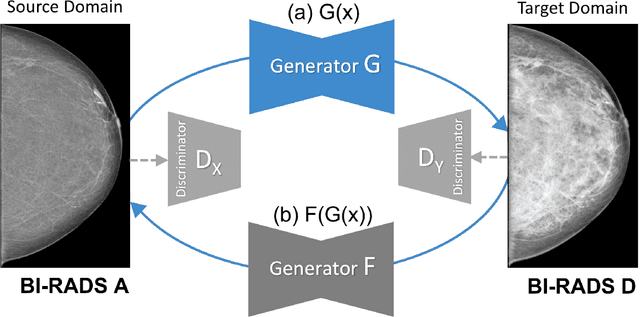
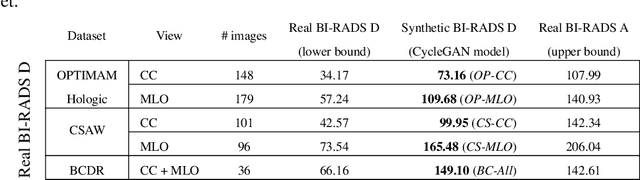
Computer-aided detection systems based on deep learning have shown good performance in breast cancer detection. However, high-density breasts show poorer detection performance since dense tissues can mask or even simulate masses. Therefore, the sensitivity of mammography for breast cancer detection can be reduced by more than 20% in dense breasts. Additionally, extremely dense cases reported an increased risk of cancer compared to low-density breasts. This study aims to improve the mass detection performance in high-density breasts using synthetic high-density full-field digital mammograms (FFDM) as data augmentation during breast mass detection model training. To this end, a total of five cycle-consistent GAN (CycleGAN) models using three FFDM datasets were trained for low-to-high-density image translation in high-resolution mammograms. The training images were split by breast density BI-RADS categories, being BI-RADS A almost entirely fatty and BI-RADS D extremely dense breasts. Our results showed that the proposed data augmentation technique improved the sensitivity and precision of mass detection in high-density breasts by 2% and 6% in two different test sets and was useful as a domain adaptation technique. In addition, the clinical realism of the synthetic images was evaluated in a reader study involving two expert radiologists and one surgical oncologist.
PatchDropout: Economizing Vision Transformers Using Patch Dropout
Aug 10, 2022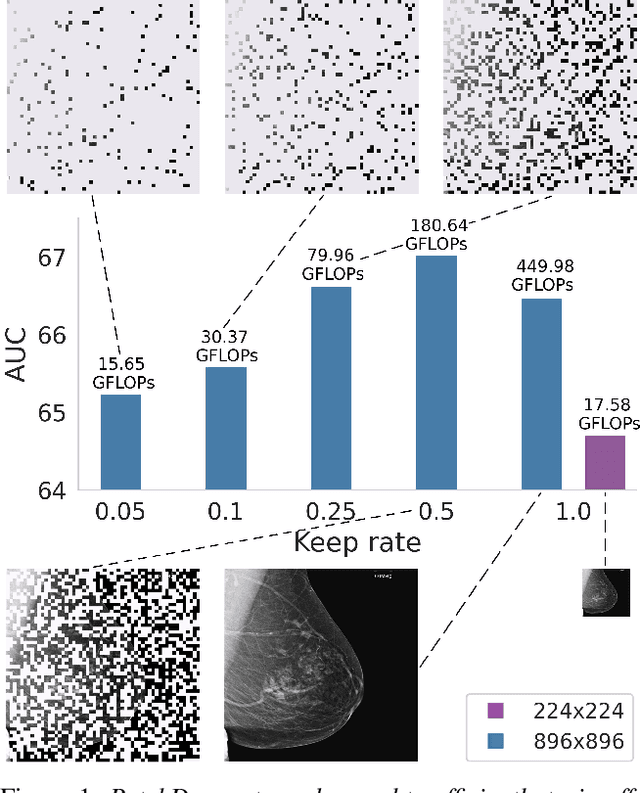
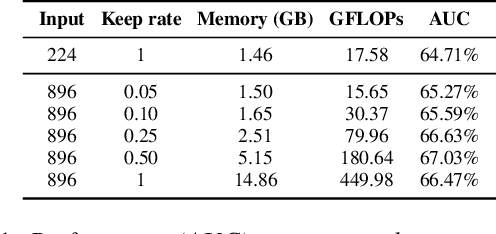
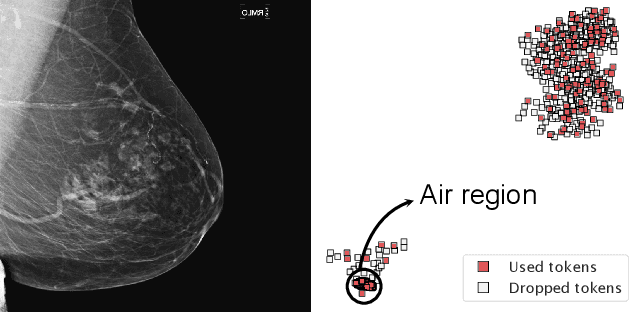
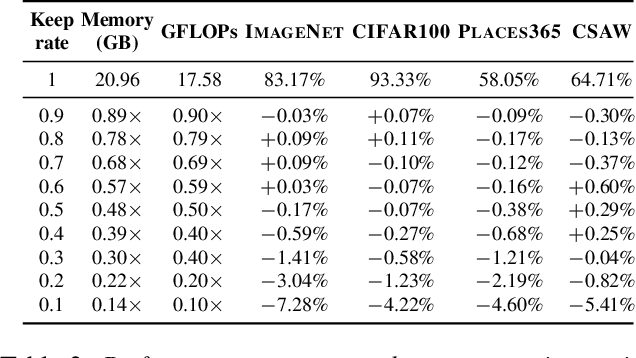
Vision transformers have demonstrated the potential to outperform CNNs in a variety of vision tasks. But the computational and memory requirements of these models prohibit their use in many applications, especially those that depend on high-resolution images, such as medical image classification. Efforts to train ViTs more efficiently are overly complicated, necessitating architectural changes or intricate training schemes. In this work, we show that standard ViT models can be efficiently trained at high resolution by randomly dropping input image patches. This simple approach, PatchDropout, reduces FLOPs and memory by at least 50% in standard natural image datasets such as ImageNet, and those savings only increase with image size. On CSAW, a high-resolution medical dataset, we observe a 5 times savings in computation and memory using PatchDropout, along with a boost in performance. For practitioners with a fixed computational or memory budget, PatchDropout makes it possible to choose image resolution, hyperparameters, or model size to get the most performance out of their model.
CSAW-M: An Ordinal Classification Dataset for Benchmarking Mammographic Masking of Cancer
Dec 02, 2021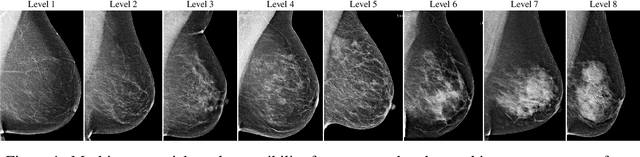

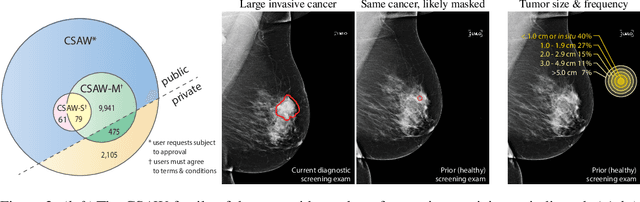

Interval and large invasive breast cancers, which are associated with worse prognosis than other cancers, are usually detected at a late stage due to false negative assessments of screening mammograms. The missed screening-time detection is commonly caused by the tumor being obscured by its surrounding breast tissues, a phenomenon called masking. To study and benchmark mammographic masking of cancer, in this work we introduce CSAW-M, the largest public mammographic dataset, collected from over 10,000 individuals and annotated with potential masking. In contrast to the previous approaches which measure breast image density as a proxy, our dataset directly provides annotations of masking potential assessments from five specialists. We also trained deep learning models on CSAW-M to estimate the masking level and showed that the estimated masking is significantly more predictive of screening participants diagnosed with interval and large invasive cancers -- without being explicitly trained for these tasks -- than its breast density counterparts.
Development and evaluation of a 3D annotation software for interactive COVID-19 lesion segmentation in chest CT
Jan 13, 2021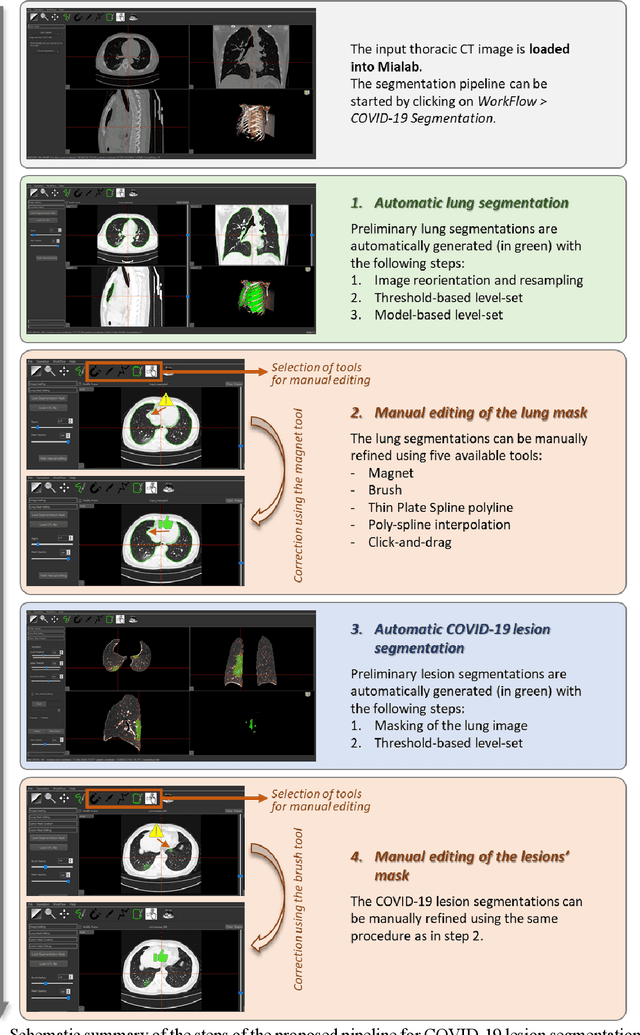
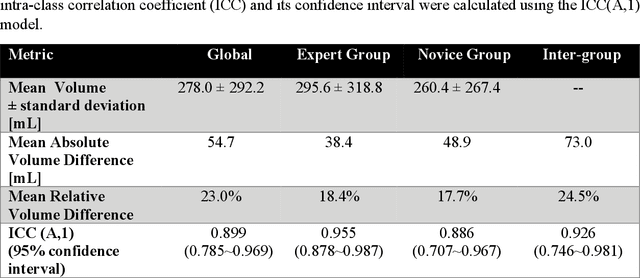
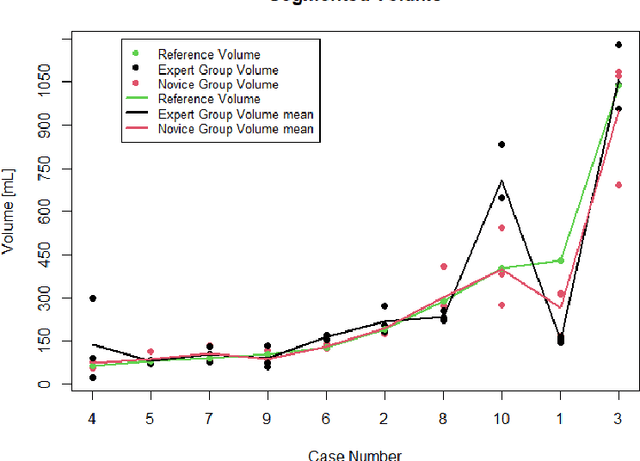
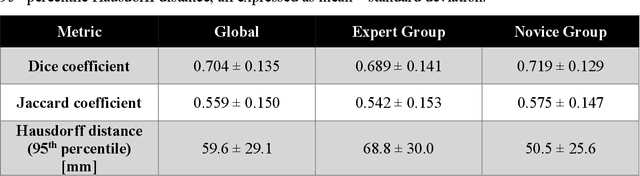
Segmentation of COVID-19 lesions from chest CT scans is of great importance for better diagnosing the disease and investigating its extent. However, manual segmentation can be very time consuming and subjective, given the lesions' large variation in shape, size and position. On the other hand, we still lack large manually segmented datasets that could be used for training machine learning-based models for fully automatic segmentation. In this work, we propose a new interactive and user-friendly tool for COVID-19 lesion segmentation, which works by alternating automatic steps (based on level-set segmentation and statistical shape modeling) with manual correction steps. The present software was tested by two different expertise groups: one group of three radiologists and one of three users with an engineering background. Promising segmentation results were obtained by both groups, which achieved satisfactory agreement both between- and within-group. Moreover, our interactive tool was shown to significantly speed up the lesion segmentation process, when compared to fully manual segmentation. Finally, we investigated inter-observer variability and how it is strongly influenced by several subjective factors, showing the importance for AI researchers and clinical doctors to be aware of the uncertainty in lesion segmentation results.