 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MAMA-MIA Challenge: Advancing Generalizability and Fairness in Breast MRI Tumor Segmentation and Treatment Response Prediction
Mar 01, 2026Breast cancer is the most frequently diagnosed malignancy among women worldwide and a leading cause of cancer-related mortality. Dynamic contrast-enhanced magnetic resonance imaging plays a central role in tumor characterization and treatment monitoring, particularly in patients receiving neoadjuvant chemotherapy. However, existing artificial intelligence models for breast magnetic resonance imaging are often developed using single-center data and evaluated using aggregate performance metrics, limiting their generalizability and obscuring potential performance disparities across demographic subgroups. The MAMA-MIA Challenge was designed to address these limitations by introducing a large-scale benchmark that jointly evaluates primary tumor segmentation and prediction of pathologic complete response using pre-treatment magnetic resonance imaging only. The training cohort comprised 1,506 patients from multiple institutions in the United States, while evaluation was conducted on an external test set of 574 patients from three independent European centers to assess cross-continental and cross-institutional generalization. A unified scoring framework combined predictive performance with subgroup consistency across age, menopausal status, and breast density. Twenty-six international teams participated in the final evaluation phase. Results demonstrate substantial performance variability under external testing and reveal trade-offs between overall accuracy and subgroup fairness. The challenge provides standardized datasets, evaluation protocols, and public resources to promote the development of robust and equitable artificial intelligence systems for breast cancer imaging.
Clinically-guided Data Synthesis for Laryngeal Lesion Detection
Aug 08, 2025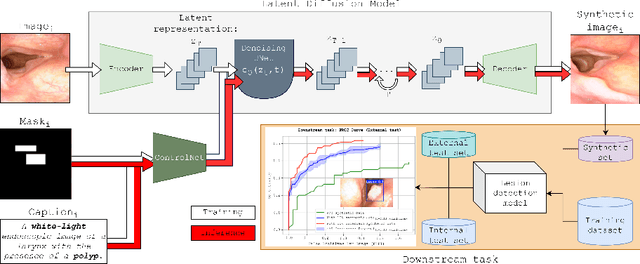
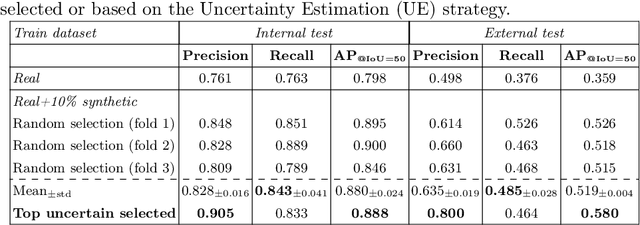
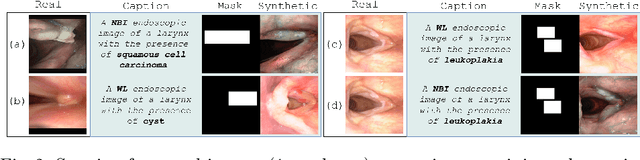
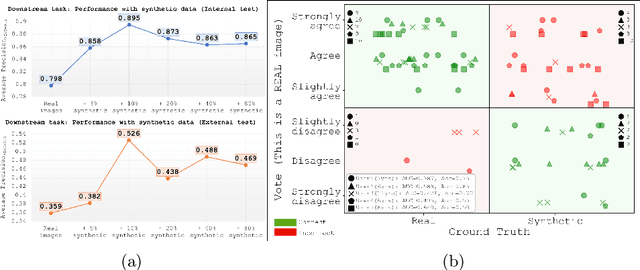
Although computer-aided diagnosis (CADx) and detection (CADe) systems have made significant progress in various medical domains, their application is still limited in specialized fields such as otorhinolaryngology. In the latter, current assessment methods heavily depend on operator expertise, and the high heterogeneity of lesions complicates diagnosis, with biopsy persisting as the gold standard despite its substantial costs and risks. A critical bottleneck for specialized endoscopic CADx/e systems is the lack of well-annotated datasets with sufficient variability for real-world generalization. This study introduces a novel approach that exploits a Latent Diffusion Model (LDM) coupled with a ControlNet adapter to generate laryngeal endoscopic image-annotation pairs, guided by clinical observations. The method addresses data scarcity by conditioning the diffusion process to produce realistic, high-quality, and clinically relevant image features that capture diverse anatomical conditions. The proposed approach can be leveraged to expand training datasets for CADx/e models, empowering the assessment process in laryngology. Indeed, during a downstream task of detection, the addition of only 10% synthetic data improved the detection rate of laryngeal lesions by 9% when the model was internally tested and 22.1% on out-of-domain external data. Additionally, the realism of the generated images was evaluated by asking 5 expert otorhinolaryngologists with varying expertise to rate their confidence in distinguishing synthetic from real images. This work has the potential to accelerate the development of automated tools for laryngeal disease diagnosis, offering a solution to data scarcity and demonstrating the applicability of synthetic data in real-world scenarios.
Calibration and Uncertainty for multiRater Volume Assessment in multiorgan Segmentation (CURVAS) challenge results
May 13, 2025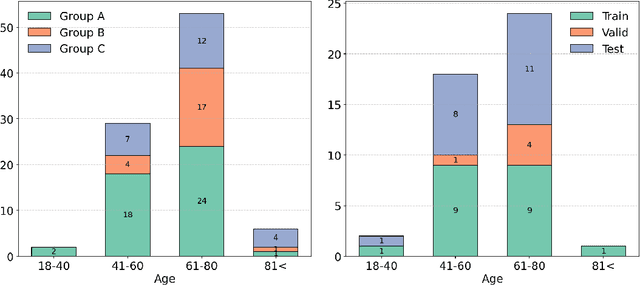
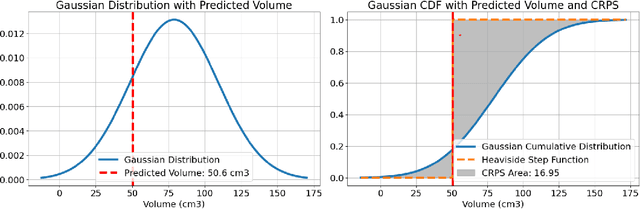

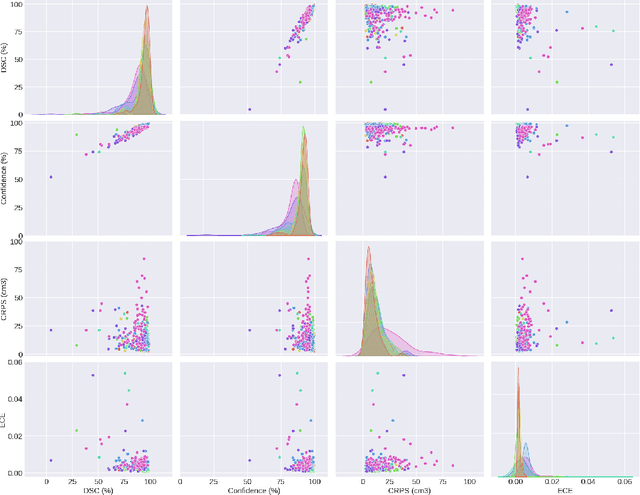
Deep learning (DL) has become the dominant approach for medical image segmentation, yet ensuring the reliability and clinical applicability of these models requires addressing key challenges such as annotation variability, calibration, and uncertainty estimation. This is why we created the Calibration and Uncertainty for multiRater Volume Assessment in multiorgan Segmentation (CURVAS), which highlights the critical role of multiple annotators in establishing a more comprehensive ground truth, emphasizing that segmentation is inherently subjective and that leveraging inter-annotator variability is essential for robust model evaluation. Seven teams participated in the challenge, submitting a variety of DL models evaluated using metrics such as Dice Similarity Coefficient (DSC), Expected Calibration Error (ECE), and Continuous Ranked Probability Score (CRPS). By incorporating consensus and dissensus ground truth, we assess how DL models handle uncertainty and whether their confidence estimates align with true segmentation performance. Our findings reinforce the importance of well-calibrated models, as better calibration is strongly correlated with the quality of the results. Furthermore, we demonstrate that segmentation models trained on diverse datasets and enriched with pre-trained knowledge exhibit greater robustness, particularly in cases deviating from standard anatomical structures. Notably, the best-performing models achieved high DSC and well-calibrated uncertainty estimates. This work underscores the need for multi-annotator ground truth, thorough calibration assessments, and uncertainty-aware evaluations to develop trustworthy and clinically reliable DL-based medical image segmentation models.
Federated nnU-Net for Privacy-Preserving Medical Image Segmentation
Mar 04, 2025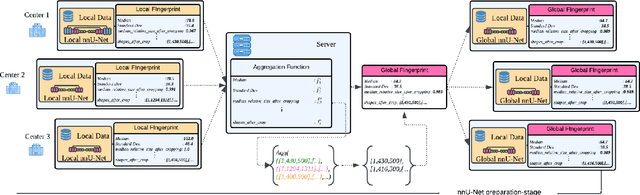
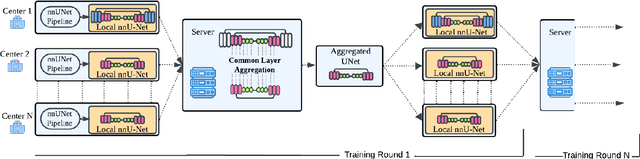
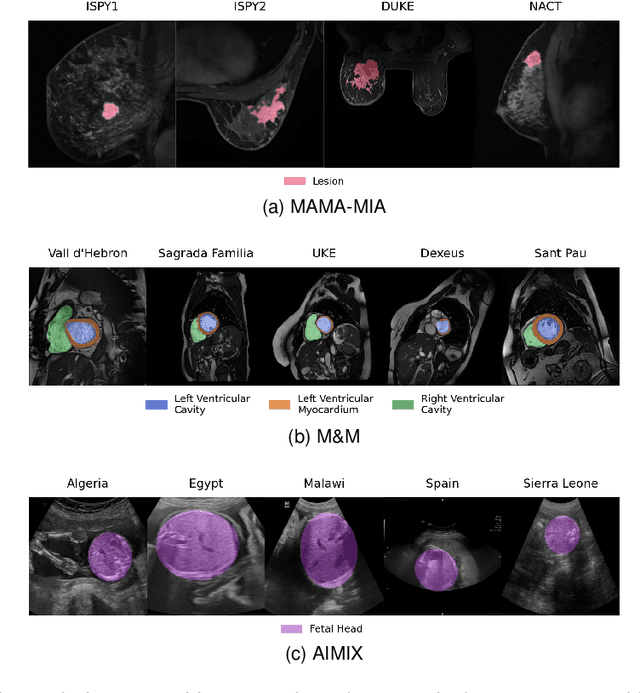
The nnU-Net framework has played a crucial role in medical image segmentation and has become the gold standard in multitudes of applications targeting different diseases, organs, and modalities. However, so far it has been used primarily in a centralized approach where the data collected from hospitals are stored in one center and used to train the nnU-Net. This centralized approach has various limitations, such as leakage of sensitive patient information and violation of patient privacy. Federated learning is one of the approaches to train a segmentation model in a decentralized manner that helps preserve patient privacy. In this paper, we propose FednnU-Net, a federated learning extension of nnU-Net. We introduce two novel federated learning methods to the nnU-Net framework - Federated Fingerprint Extraction (FFE) and Asymmetric Federated Averaging (AsymFedAvg) - and experimentally show their consistent performance for breast, cardiac and fetal segmentation using 6 datasets representing samples from 18 institutions. Additionally, to further promote research and deployment of decentralized training in privacy constrained institutions, we make our plug-n-play framework public. The source-code is available at https://github.com/faildeny/FednnUNet .
Efficient MedSAMs: Segment Anything in Medical Images on Laptop
Dec 20, 2024


Promptable segmentation foundation models have emerged as a transformative approach to addressing the diverse needs in medical images, but most existing models require expensive computing, posing a big barrier to their adoption in clinical practice. In this work, we organized the first international competition dedicated to promptable medical image segmentation, featuring a large-scale dataset spanning nine common imaging modalities from over 20 different institutions. The top teams developed lightweight segmentation foundation models and implemented an efficient inference pipeline that substantially reduced computational requirements while maintaining state-of-the-art segmentation accuracy. Moreover, the post-challenge phase advanced the algorithms through the design of performance booster and reproducibility tasks, resulting in improved algorithms and validated reproducibility of the winning solution. Furthermore, the best-performing algorithms have been incorporated into the open-source software with a user-friendly interface to facilitate clinical adoption. The data and code are publicly available to foster the further development of medical image segmentation foundation models and pave the way for impactful real-world applications.
MAMA-MIA: A Large-Scale Multi-Center Breast Cancer DCE-MRI Benchmark Dataset with Expert Segmentations
Jun 19, 2024Current research in breast cancer Magnetic Resonance Imaging (MRI), especially with Artificial Intelligence (AI), faces challenges due to the lack of expert segmentations. To address this, we introduce the MAMA-MIA dataset, comprising 1506 multi-center dynamic contrast-enhanced MRI cases with expert segmentations of primary tumors and non-mass enhancement areas. These cases were sourced from four publicly available collections in The Cancer Imaging Archive (TCIA). Initially, we trained a deep learning model to automatically segment the cases, generating preliminary segmentations that significantly reduced expert segmentation time. Sixteen experts, averaging 9 years of experience in breast cancer, then corrected these segmentations, resulting in the final expert segmentations. Additionally, two radiologists conducted a visual inspection of the automatic segmentations to support future quality control studies. Alongside the expert segmentations, we provide 49 harmonized demographic and clinical variables and the pretrained weights of the well-known nnUNet architecture trained using the DCE-MRI full-images and expert segmentations. This dataset aims to accelerate the development and benchmarking of deep learning models and foster innovation in breast cancer diagnostics and treatment planning.
Debiasing Cardiac Imaging with Controlled Latent Diffusion Models
Mar 28, 2024

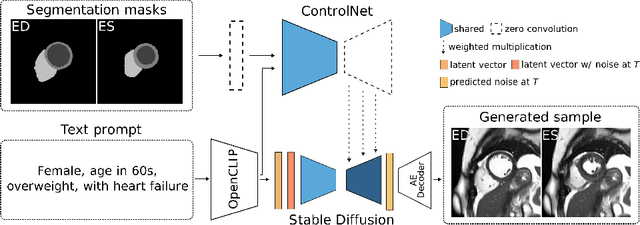

The progress in deep learning solutions for disease diagnosis and prognosis based on cardiac magnetic resonance imaging is hindered by highly imbalanced and biased training data. To address this issue, we propose a method to alleviate imbalances inherent in datasets through the generation of synthetic data based on sensitive attributes such as sex, age, body mass index, and health condition. We adopt ControlNet based on a denoising diffusion probabilistic model to condition on text assembled from patient metadata and cardiac geometry derived from segmentation masks using a large-cohort study, specifically, the UK Biobank. We assess our method by evaluating the realism of the generated images using established quantitative metrics. Furthermore, we conduct a downstream classification task aimed at debiasing a classifier by rectifying imbalances within underrepresented groups through synthetically generated samples. Our experiments demonstrate the effectiveness of the proposed approach in mitigating dataset imbalances, such as the scarcity of younger patients or individuals with normal BMI level suffering from heart failure. This work represents a major step towards the adoption of synthetic data for the development of fair and generalizable models for medical classification tasks. Notably, we conduct all our experiments using a single, consumer-level GPU to highlight the feasibility of our approach within resource-constrained environments. Our code is available at https://github.com/faildeny/debiasing-cardiac-mri.
Towards Learning Contrast Kinetics with Multi-Condition Latent Diffusion Models
Mar 20, 2024



Contrast agents in dynamic contrast enhanced magnetic resonance imaging allow to localize tumors and observe their contrast kinetics, which is essential for cancer characterization and respective treatment decision-making. However, contrast agent administration is not only associated with adverse health risks, but also restricted for patients during pregnancy, and for those with kidney malfunction, or other adverse reactions. With contrast uptake as key biomarker for lesion malignancy, cancer recurrence risk, and treatment response, it becomes pivotal to reduce the dependency on intravenous contrast agent administration. To this end, we propose a multi-conditional latent diffusion model capable of acquisition time-conditioned image synthesis of DCE-MRI temporal sequences. To evaluate medical image synthesis, we additionally propose and validate the Fr\'echet radiomics distance as an image quality measure based on biomarker variability between synthetic and real imaging data. Our results demonstrate our method's ability to generate realistic multi-sequence fat-saturated breast DCE-MRI and uncover the emerging potential of deep learning based contrast kinetics simulation. We publicly share our accessible codebase at https://github.com/RichardObi/ccnet.
Revisiting Skin Tone Fairness in Dermatological Lesion Classification
Aug 18, 2023
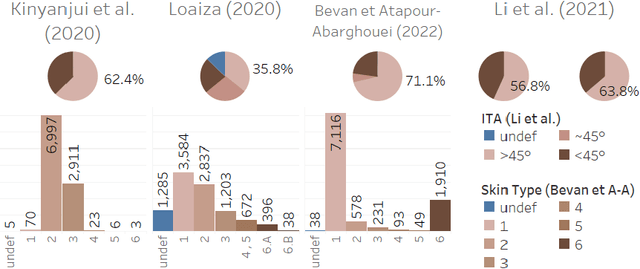

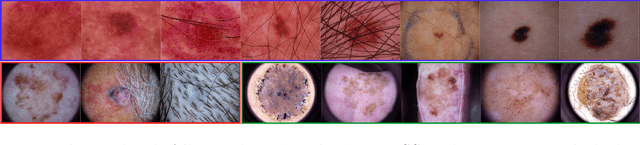
Addressing fairness in lesion classification from dermatological images is crucial due to variations in how skin diseases manifest across skin tones. However, the absence of skin tone labels in public datasets hinders building a fair classifier. To date, such skin tone labels have been estimated prior to fairness analysis in independent studies using the Individual Typology Angle (ITA). Briefly, ITA calculates an angle based on pixels extracted from skin images taking into account the lightness and yellow-blue tints. These angles are then categorised into skin tones that are subsequently used to analyse fairness in skin cancer classification. In this work, we review and compare four ITA-based approaches of skin tone classification on the ISIC18 dataset, a common benchmark for assessing skin cancer classification fairness in the literature. Our analyses reveal a high disagreement among previously published studies demonstrating the risks of ITA-based skin tone estimation methods. Moreover, we investigate the causes of such large discrepancy among these approaches and find that the lack of diversity in the ISIC18 dataset limits its use as a testbed for fairness analysis. Finally, we recommend further research on robust ITA estimation and diverse dataset acquisition with skin tone annotation to facilitate conclusive fairness assessments of artificial intelligence tools in dermatology. Our code is available at https://github.com/tkalbl/RevisitingSkinToneFairness.
medigan: A Python Library of Pretrained Generative Models for Enriched Data Access in Medical Imaging
Sep 28, 2022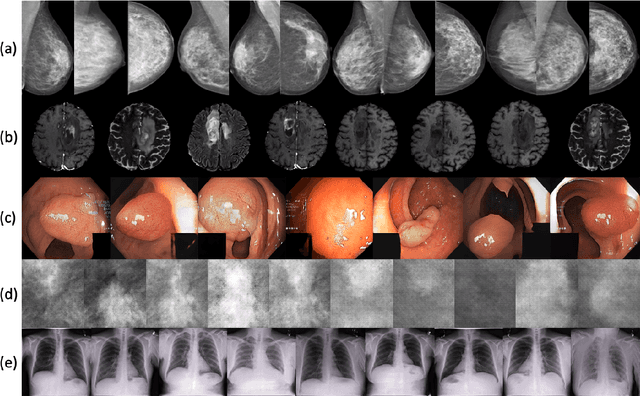
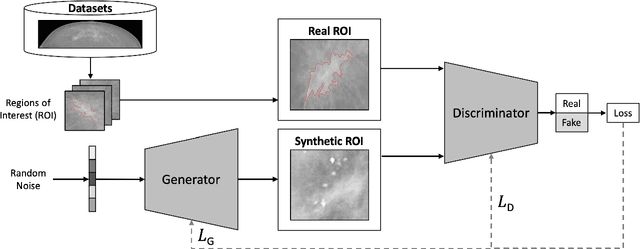
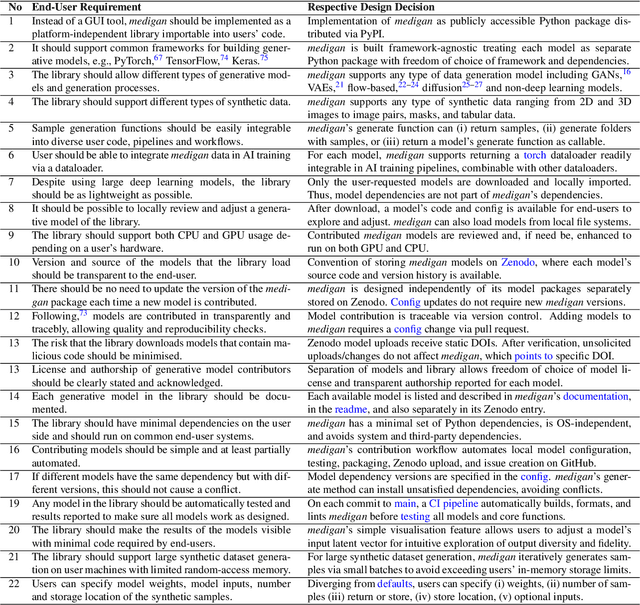
Synthetic data generated by generative models can enhance the performance and capabilities of data-hungry deep learning models in medical imaging. However, there is (1) limited availability of (synthetic) datasets and (2) generative models are complex to train, which hinders their adoption in research and clinical applications. To reduce this entry barrier, we propose medigan, a one-stop shop for pretrained generative models implemented as an open-source framework-agnostic Python library. medigan allows researchers and developers to create, increase, and domain-adapt their training data in just a few lines of code. Guided by design decisions based on gathered end-user requirements, we implement medigan based on modular components for generative model (i) execution, (ii) visualisation, (iii) search & ranking, and (iv) contribution. The library's scalability and design is demonstrated by its growing number of integrated and readily-usable pretrained generative models consisting of 21 models utilising 9 different Generative Adversarial Network architectures trained on 11 datasets from 4 domains, namely, mammography, endoscopy, x-ray, and MRI. Furthermore, 3 applications of medigan are analysed in this work, which include (a) enabling community-wide sharing of restricted data, (b) investigating generative model evaluation metrics, and (c) improving clinical downstream tasks. In (b), extending on common medical image synthesis assessment and reporting standards, we show Fr\'echet Inception Distance variability based on image normalisation and radiology-specific feature extraction.