 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-Based Output Drift Detection for Breast Cancer Response Prediction in a Multisite Clinical Decision Support System
Dec 20, 2025Modern clinical decision support systems can concurrently serve multiple, independent medical imaging institutions, but their predictive performance may degrade across sites due to variations in patient populations, imaging hardware, and acquisition protocols. Continuous surveillance of predictive model outputs offers a safe and reliable approach for identifying such distributional shifts without ground truth labels. However, most existing methods rely on centralized monitoring of aggregated predictions, overlooking site-specific drift dynamics. We propose an agent-based framework for detecting drift and assessing its severity in multisite clinical AI systems. To evaluate its effectiveness, we simulate a multi-center environment for output-based drift detection, assigning each site a drift monitoring agent that performs batch-wise comparisons of model outputs against a reference distribution. We analyse several multi-center monitoring schemes, that differ in how the reference is obtained (site-specific, global, production-only and adaptive), alongside a centralized baseline. Results on real-world breast cancer imaging data using a pathological complete response prediction model shows that all multi-center schemes outperform centralized monitoring, with F1-score improvements up to 10.3% in drift detection. In the absence of site-specific references, the adaptive scheme performs best, with F1-scores of 74.3% for drift detection and 83.7% for drift severity classification. These findings suggest that adaptive, site-aware agent-based drift monitoring can enhance reliability of multisite clinical decision support systems.
Clinically-guided Data Synthesis for Laryngeal Lesion Detection
Aug 08, 2025Although computer-aided diagnosis (CADx) and detection (CADe) systems have made significant progress in various medical domains, their application is still limited in specialized fields such as otorhinolaryngology. In the latter, current assessment methods heavily depend on operator expertise, and the high heterogeneity of lesions complicates diagnosis, with biopsy persisting as the gold standard despite its substantial costs and risks. A critical bottleneck for specialized endoscopic CADx/e systems is the lack of well-annotated datasets with sufficient variability for real-world generalization. This study introduces a novel approach that exploits a Latent Diffusion Model (LDM) coupled with a ControlNet adapter to generate laryngeal endoscopic image-annotation pairs, guided by clinical observations. The method addresses data scarcity by conditioning the diffusion process to produce realistic, high-quality, and clinically relevant image features that capture diverse anatomical conditions. The proposed approach can be leveraged to expand training datasets for CADx/e models, empowering the assessment process in laryngology. Indeed, during a downstream task of detection, the addition of only 10% synthetic data improved the detection rate of laryngeal lesions by 9% when the model was internally tested and 22.1% on out-of-domain external data. Additionally, the realism of the generated images was evaluated by asking 5 expert otorhinolaryngologists with varying expertise to rate their confidence in distinguishing synthetic from real images. This work has the potential to accelerate the development of automated tools for laryngeal disease diagnosis, offering a solution to data scarcity and demonstrating the applicability of synthetic data in real-world scenarios.
Simulating Dynamic Tumor Contrast Enhancement in Breast MRI using Conditional Generative Adversarial Networks
Sep 27, 2024This paper presents a method for virtual contrast enhancement in breast MRI, offering a promising non-invasive alternative to traditional contrast agent-based DCE-MRI acquisition. Using a conditional generative adversarial network, we predict DCE-MRI images, including jointly-generated sequences of multiple corresponding DCE-MRI timepoints, from non-contrast-enhanced MRIs, enabling tumor localization and characterization without the associated health risks. Furthermore, we qualitatively and quantitatively evaluate the synthetic DCE-MRI images, proposing a multi-metric Scaled Aggregate Measure (SAMe), assessing their utility in a tumor segmentation downstream task, and conclude with an analysis of the temporal patterns in multi-sequence DCE-MRI generation. Our approach demonstrates promising results in generating realistic and useful DCE-MRI sequences, highlighting the potential of virtual contrast enhancement for improving breast cancer diagnosis and treatment, particularly for patients where contrast agent administration is contraindicated.
On Differentially Private 3D Medical Image Synthesis with Controllable Latent Diffusion Models
Jul 23, 2024
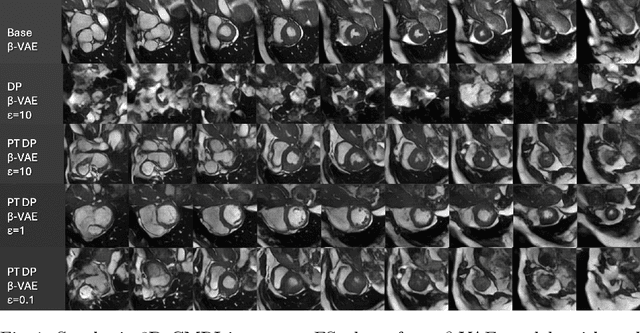
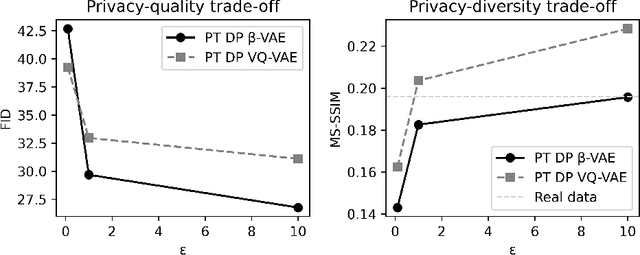

Generally, the small size of public medical imaging datasets coupled with stringent privacy concerns, hampers the advancement of data-hungry deep learning models in medical imaging. This study addresses these challenges for 3D cardiac MRI images in the short-axis view. We propose Latent Diffusion Models that generate synthetic images conditioned on medical attributes, while ensuring patient privacy through differentially private model training. To our knowledge, this is the first work to apply and quantify differential privacy in 3D medical image generation. We pre-train our models on public data and finetune them with differential privacy on the UK Biobank dataset. Our experiments reveal that pre-training significantly improves model performance, achieving a Fr\'echet Inception Distance (FID) of 26.77 at $\epsilon=10$, compared to 92.52 for models without pre-training. Additionally, we explore the trade-off between privacy constraints and image quality, investigating how tighter privacy budgets affect output controllability and may lead to degraded performance. Our results demonstrate that proper consideration during training with differential privacy can substantially improve the quality of synthetic cardiac MRI images, but there are still notable challenges in achieving consistent medical realism.
Enhancing the Utility of Privacy-Preserving Cancer Classification using Synthetic Data
Jul 17, 2024Deep learning holds immense promise for aiding radiologists in breast cancer detection. However, achieving optimal model performance is hampered by limitations in availability and sharing of data commonly associated to patient privacy concerns. Such concerns are further exacerbated, as traditional deep learning models can inadvertently leak sensitive training information. This work addresses these challenges exploring and quantifying the utility of privacy-preserving deep learning techniques, concretely, (i) differentially private stochastic gradient descent (DP-SGD) and (ii) fully synthetic training data generated by our proposed malignancy-conditioned generative adversarial network. We assess these methods via downstream malignancy classification of mammography masses using a transformer model. Our experimental results depict that synthetic data augmentation can improve privacy-utility tradeoffs in differentially private model training. Further, model pretraining on synthetic data achieves remarkable performance, which can be further increased with DP-SGD fine-tuning across all privacy guarantees. With this first in-depth exploration of privacy-preserving deep learning in breast imaging, we address current and emerging clinical privacy requirements and pave the way towards the adoption of private high-utility deep diagnostic models. Our reproducible codebase is publicly available at https://github.com/RichardObi/mammo_dp.
Progressive Growing of Patch Size: Resource-Efficient Curriculum Learning for Dense Prediction Tasks
Jul 11, 2024In this work, we introduce Progressive Growing of Patch Size, a resource-efficient implicit curriculum learning approach for dense prediction tasks. Our curriculum approach is defined by growing the patch size during model training, which gradually increases the task's difficulty. We integrated our curriculum into the nnU-Net framework and evaluated the methodology on all 10 tasks of the Medical Segmentation Decathlon. With our approach, we are able to substantially reduce runtime, computational costs, and CO2 emissions of network training compared to classical constant patch size training. In our experiments, the curriculum approach resulted in improved convergence. We are able to outperform standard nnU-Net training, which is trained with constant patch size, in terms of Dice Score on 7 out of 10 MSD tasks while only spending roughly 50% of the original training runtime. To the best of our knowledge, our Progressive Growing of Patch Size is the first successful employment of a sample-length curriculum in the form of patch size in the field of computer vision. Our code is publicly available at https://github.com/compai-lab/2024-miccai-fischer.
MAMA-MIA: A Large-Scale Multi-Center Breast Cancer DCE-MRI Benchmark Dataset with Expert Segmentations
Jun 19, 2024Current research in breast cancer Magnetic Resonance Imaging (MRI), especially with Artificial Intelligence (AI), faces challenges due to the lack of expert segmentations. To address this, we introduce the MAMA-MIA dataset, comprising 1506 multi-center dynamic contrast-enhanced MRI cases with expert segmentations of primary tumors and non-mass enhancement areas. These cases were sourced from four publicly available collections in The Cancer Imaging Archive (TCIA). Initially, we trained a deep learning model to automatically segment the cases, generating preliminary segmentations that significantly reduced expert segmentation time. Sixteen experts, averaging 9 years of experience in breast cancer, then corrected these segmentations, resulting in the final expert segmentations. Additionally, two radiologists conducted a visual inspection of the automatic segmentations to support future quality control studies. Alongside the expert segmentations, we provide 49 harmonized demographic and clinical variables and the pretrained weights of the well-known nnUNet architecture trained using the DCE-MRI full-images and expert segmentations. This dataset aims to accelerate the development and benchmarking of deep learning models and foster innovation in breast cancer diagnostics and treatment planning.
Mitigating annotation shift in cancer classification using single image generative models
May 30, 2024Artificial Intelligence (AI) has emerged as a valuable tool for assisting radiologists in breast cancer detection and diagnosis. However, the success of AI applications in this domain is restricted by the quantity and quality of available data, posing challenges due to limited and costly data annotation procedures that often lead to annotation shifts. This study simulates, analyses and mitigates annotation shifts in cancer classification in the breast mammography domain. First, a high-accuracy cancer risk prediction model is developed, which effectively distinguishes benign from malignant lesions. Next, model performance is used to quantify the impact of annotation shift. We uncover a substantial impact of annotation shift on multiclass classification performance particularly for malignant lesions. We thus propose a training data augmentation approach based on single-image generative models for the affected class, requiring as few as four in-domain annotations to considerably mitigate annotation shift, while also addressing dataset imbalance. Lastly, we further increase performance by proposing and validating an ensemble architecture based on multiple models trained under different data augmentation regimes. Our study offers key insights into annotation shift in deep learning breast cancer classification and explores the potential of single-image generative models to overcome domain shift challenges.
Debiasing Cardiac Imaging with Controlled Latent Diffusion Models
Mar 28, 2024

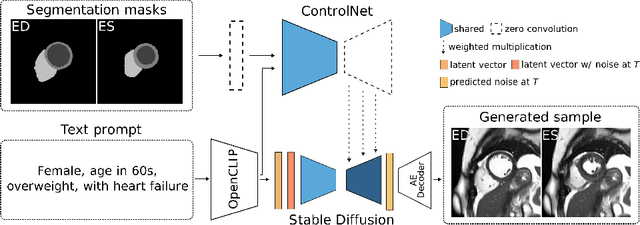

The progress in deep learning solutions for disease diagnosis and prognosis based on cardiac magnetic resonance imaging is hindered by highly imbalanced and biased training data. To address this issue, we propose a method to alleviate imbalances inherent in datasets through the generation of synthetic data based on sensitive attributes such as sex, age, body mass index, and health condition. We adopt ControlNet based on a denoising diffusion probabilistic model to condition on text assembled from patient metadata and cardiac geometry derived from segmentation masks using a large-cohort study, specifically, the UK Biobank. We assess our method by evaluating the realism of the generated images using established quantitative metrics. Furthermore, we conduct a downstream classification task aimed at debiasing a classifier by rectifying imbalances within underrepresented groups through synthetically generated samples. Our experiments demonstrate the effectiveness of the proposed approach in mitigating dataset imbalances, such as the scarcity of younger patients or individuals with normal BMI level suffering from heart failure. This work represents a major step towards the adoption of synthetic data for the development of fair and generalizable models for medical classification tasks. Notably, we conduct all our experiments using a single, consumer-level GPU to highlight the feasibility of our approach within resource-constrained environments. Our code is available at https://github.com/faildeny/debiasing-cardiac-mri.
Towards Learning Contrast Kinetics with Multi-Condition Latent Diffusion Models
Mar 20, 2024



Contrast agents in dynamic contrast enhanced magnetic resonance imaging allow to localize tumors and observe their contrast kinetics, which is essential for cancer characterization and respective treatment decision-making. However, contrast agent administration is not only associated with adverse health risks, but also restricted for patients during pregnancy, and for those with kidney malfunction, or other adverse reactions. With contrast uptake as key biomarker for lesion malignancy, cancer recurrence risk, and treatment response, it becomes pivotal to reduce the dependency on intravenous contrast agent administration. To this end, we propose a multi-conditional latent diffusion model capable of acquisition time-conditioned image synthesis of DCE-MRI temporal sequences. To evaluate medical image synthesis, we additionally propose and validate the Fr\'echet radiomics distance as an image quality measure based on biomarker variability between synthetic and real imaging data. Our results demonstrate our method's ability to generate realistic multi-sequence fat-saturated breast DCE-MRI and uncover the emerging potential of deep learning based contrast kinetics simulation. We publicly share our accessible codebase at https://github.com/RichardObi/ccnet.