 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocBAM: Advancing 3D Patch-Based Image Segmentation by Integrating Location Contex
Jan 21, 2026Patch-based methods are widely used in 3D medical image segmentation to address memory constraints in processing high-resolution volumetric data. However, these approaches often neglect the patch's location within the global volume, which can limit segmentation performance when anatomical context is important. In this paper, we investigate the role of location context in patch-based 3D segmentation and propose a novel attention mechanism, LocBAM, that explicitly processes spatial information. Experiments on BTCV, AMOS22, and KiTS23 demonstrate that incorporating location context stabilizes training and improves segmentation performance, particularly under low patch-to-volume coverage where global context is missing. Furthermore, LocBAM consistently outperforms classical coordinate encoding via CoordConv. Code is publicly available at https://github.com/compai-lab/2026-ISBI-hooft
TomoGraphView: 3D Medical Image Classification with Omnidirectional Slice Representations and Graph Neural Networks
Nov 12, 2025The growing number of medical tomography examinations has necessitated the development of automated methods capable of extracting comprehensive imaging features to facilitate downstream tasks such as tumor characterization, while assisting physicians in managing their growing workload. However, 3D medical image classification remains a challenging task due to the complex spatial relationships and long-range dependencies inherent in volumetric data. Training models from scratch suffers from low data regimes, and the absence of 3D large-scale multimodal datasets has limited the development of 3D medical imaging foundation models. Recent studies, however, have highlighted the potential of 2D vision foundation models, originally trained on natural images, as powerful feature extractors for medical image analysis. Despite these advances, existing approaches that apply 2D models to 3D volumes via slice-based decomposition remain suboptimal. Conventional volume slicing strategies, which rely on canonical planes such as axial, sagittal, or coronal, may inadequately capture the spatial extent of target structures when these are misaligned with standardized viewing planes. Furthermore, existing slice-wise aggregation strategies rarely account for preserving the volumetric structure, resulting in a loss of spatial coherence across slices. To overcome these limitations, we propose TomoGraphView, a novel framework that integrates omnidirectional volume slicing with spherical graph-based feature aggregation. We publicly share our accessible code base at http://github.com/compai-lab/2025-MedIA-kiechle and provide a user-friendly library for omnidirectional volume slicing at https://pypi.org/project/OmniSlicer.
Improving Reliability and Explainability of Medical Question Answering through Atomic Fact Checking in Retrieval-Augmented LLMs
May 30, 2025Large language models (LLMs) exhibit extensive medical knowledge but are prone to hallucinations and inaccurate citations, which pose a challenge to their clinical adoption and regulatory compliance. Current methods, such as Retrieval Augmented Generation, partially address these issues by grounding answers in source documents, but hallucinations and low fact-level explainability persist. In this work, we introduce a novel atomic fact-checking framework designed to enhance the reliability and explainability of LLMs used in medical long-form question answering. This method decomposes LLM-generated responses into discrete, verifiable units called atomic facts, each of which is independently verified against an authoritative knowledge base of medical guidelines. This approach enables targeted correction of errors and direct tracing to source literature, thereby improving the factual accuracy and explainability of medical Q&A. Extensive evaluation using multi-reader assessments by medical experts and an automated open Q&A benchmark demonstrated significant improvements in factual accuracy and explainability. Our framework achieved up to a 40% overall answer improvement and a 50% hallucination detection rate. The ability to trace each atomic fact back to the most relevant chunks from the database provides a granular, transparent explanation of the generated responses, addressing a major gap in current medical AI applications. This work represents a crucial step towards more trustworthy and reliable clinical applications of LLMs, addressing key prerequisites for clinical application and fostering greater confidence in AI-assisted healthcare.
Graph Neural Networks: A suitable Alternative to MLPs in Latent 3D Medical Image Classification?
Jul 24, 2024



Recent studies have underscored the capabilities of natural imaging foundation models to serve as powerful feature extractors, even in a zero-shot setting for medical imaging data. Most commonly, a shallow multi-layer perceptron (MLP) is appended to the feature extractor to facilitate end-to-end learning and downstream prediction tasks such as classification, thus representing the de facto standard. However, as graph neural networks (GNNs) have become a practicable choice for various tasks in medical research in the recent past, we direct attention to the question of how effective GNNs are compared to MLP prediction heads for the task of 3D medical image classification, proposing them as a potential alternative. In our experiments, we devise a subject-level graph for each volumetric dataset instance. Therein latent representations of all slices in the volume, encoded through a DINOv2 pretrained vision transformer (ViT), constitute the nodes and their respective node features. We use public datasets to compare the classification heads numerically and evaluate various graph construction and graph convolution methods in our experiments. Our findings show enhancements of the GNN in classification performance and substantial improvements in runtime compared to an MLP prediction head. Additional robustness evaluations further validate the promising performance of the GNN, promoting them as a suitable alternative to traditional MLP classification heads. Our code is publicly available at: https://github.com/compai-lab/2024-miccai-grail-kiechle
Progressive Growing of Patch Size: Resource-Efficient Curriculum Learning for Dense Prediction Tasks
Jul 11, 2024In this work, we introduce Progressive Growing of Patch Size, a resource-efficient implicit curriculum learning approach for dense prediction tasks. Our curriculum approach is defined by growing the patch size during model training, which gradually increases the task's difficulty. We integrated our curriculum into the nnU-Net framework and evaluated the methodology on all 10 tasks of the Medical Segmentation Decathlon. With our approach, we are able to substantially reduce runtime, computational costs, and CO2 emissions of network training compared to classical constant patch size training. In our experiments, the curriculum approach resulted in improved convergence. We are able to outperform standard nnU-Net training, which is trained with constant patch size, in terms of Dice Score on 7 out of 10 MSD tasks while only spending roughly 50% of the original training runtime. To the best of our knowledge, our Progressive Growing of Patch Size is the first successful employment of a sample-length curriculum in the form of patch size in the field of computer vision. Our code is publicly available at https://github.com/compai-lab/2024-miccai-fischer.
Mask the Unknown: Assessing Different Strategies to Handle Weak Annotations in the MICCAI2023 Mediastinal Lymph Node Quantification Challenge
Jun 20, 2024

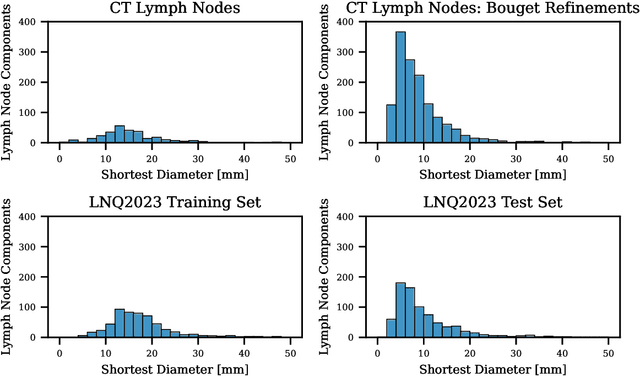
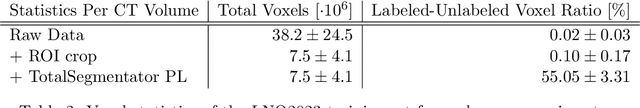
Pathological lymph node delineation is crucial in cancer diagnosis, progression assessment, and treatment planning. The MICCAI 2023 Lymph Node Quantification Challenge published the first public dataset for pathological lymph node segmentation in the mediastinum. As lymph node annotations are expensive, the challenge was formed as a weakly supervised learning task, where only a subset of all lymph nodes in the training set have been annotated. For the challenge submission, multiple methods for training on these weakly supervised data were explored, including noisy label training, loss masking of unlabeled data, and an approach that integrated the TotalSegmentator toolbox as a form of pseudo labeling in order to reduce the number of unknown voxels. Furthermore, multiple public TCIA datasets were incorporated into the training to improve the performance of the deep learning model. Our submitted model achieved a Dice score of 0.628 and an average symmetric surface distance of 5.8~mm on the challenge test set. With our submitted model, we accomplished third rank in the MICCAI2023 LNQ challenge. A finding of our analysis was that the integration of all visible, including non-pathological, lymph nodes improved the overall segmentation performance on pathological lymph nodes of the test set. Furthermore, segmentation models trained only on clinically enlarged lymph nodes, as given in the challenge scenario, could not generalize to smaller pathological lymph nodes. The code and model for the challenge submission are available at \url{https://gitlab.lrz.de/compai/MediastinalLymphNodeSegmentation}.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2024:008
Analysis of clinical, dosimetric and radiomic features for predicting local failure after stereotactic radiotherapy of brain metastases in malignant melanoma
May 31, 2024
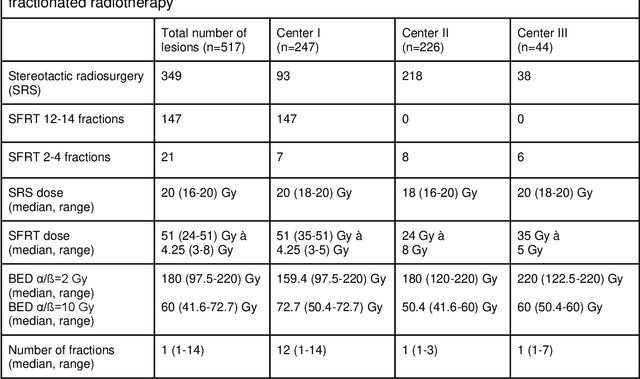
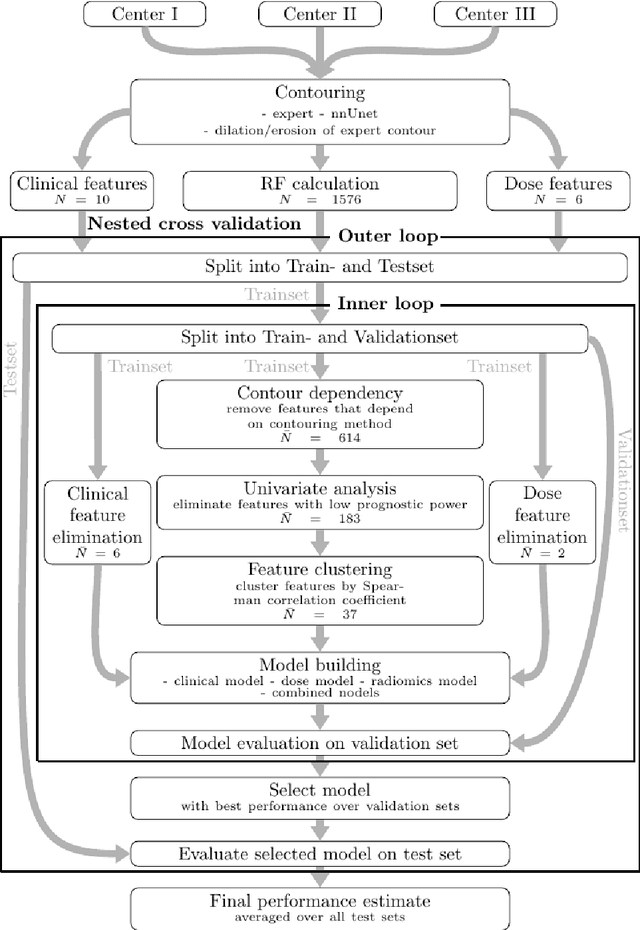
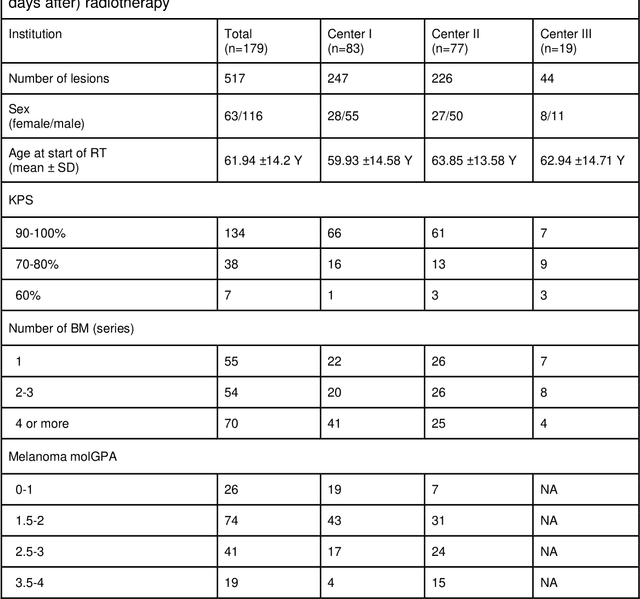
Background: The aim of this study was to investigate the role of clinical, dosimetric and pretherapeutic magnetic resonance imaging (MRI) features for lesion-specific outcome prediction of stereotactic radiotherapy (SRT) in patients with brain metastases from malignant melanoma (MBM). Methods: In this multicenter, retrospective analysis, we reviewed 517 MBM from 130 patients treated with SRT (single fraction or hypofractionated). For each gross tumor volume (GTV) 1576 radiomic features (RF) were calculated (788 each for the GTV and for a 3 mm margin around the GTV). Clinical parameters, radiation dose and RF from pretherapeutic contrast-enhanced T1-weighted MRI from different institutions were evaluated with a feature processing and elimination pipeline in a nested cross-validation scheme. Results: Seventy-two (72) of 517 lesions (13.9%) showed a local failure (LF) after SRT. The processing pipeline showed clinical, dosimetric and radiomic features providing information for LF prediction. The most prominent ones were the correlation of the gray level co-occurrence matrix of the margin (hazard ratio (HR): 0.37, confidence interval (CI): 0.23-0.58) and systemic therapy before SRT (HR: 0.55, CI: 0.42-0.70). The majority of RF associated with LF was calculated in the margin around the GTV. Conclusions: Pretherapeutic MRI based RF connected with lesion-specific outcome after SRT could be identified, despite multicentric data and minor differences in imaging protocols. Image data analysis of the surrounding metastatic environment may provide therapy-relevant information with the potential to further individualize radiotherapy strategies.
All Sizes Matter: Improving Volumetric Brain Segmentation on Small Lesions
Oct 04, 2023



Brain metastases (BMs) are the most frequently occurring brain tumors. The treatment of patients having multiple BMs with stereo tactic radiosurgery necessitates accurate localization of the metastases. Neural networks can assist in this time-consuming and costly task that is typically performed by human experts. Particularly challenging is the detection of small lesions since they are often underrepresented in exist ing approaches. Yet, lesion detection is equally important for all sizes. In this work, we develop an ensemble of neural networks explicitly fo cused on detecting and segmenting small BMs. To accomplish this task, we trained several neural networks focusing on individual aspects of the BM segmentation problem: We use blob loss that specifically addresses the imbalance of lesion instances in terms of size and texture and is, therefore, not biased towards larger lesions. In addition, a model using a subtraction sequence between the T1 and T1 contrast-enhanced sequence focuses on low-contrast lesions. Furthermore, we train additional models only on small lesions. Our experiments demonstrate the utility of the ad ditional blob loss and the subtraction sequence. However, including the specialized small lesion models in the ensemble deteriorates segmentation results. We also find domain-knowledge-inspired postprocessing steps to drastically increase our performance in most experiments. Our approach enables us to submit a competitive challenge entry to the ASNR-MICCAI BraTS Brain Metastasis Challenge 2023.
A unified 3D framework for Organs at Risk Localization and Segmentation for Radiation Therapy Planning
Mar 01, 2022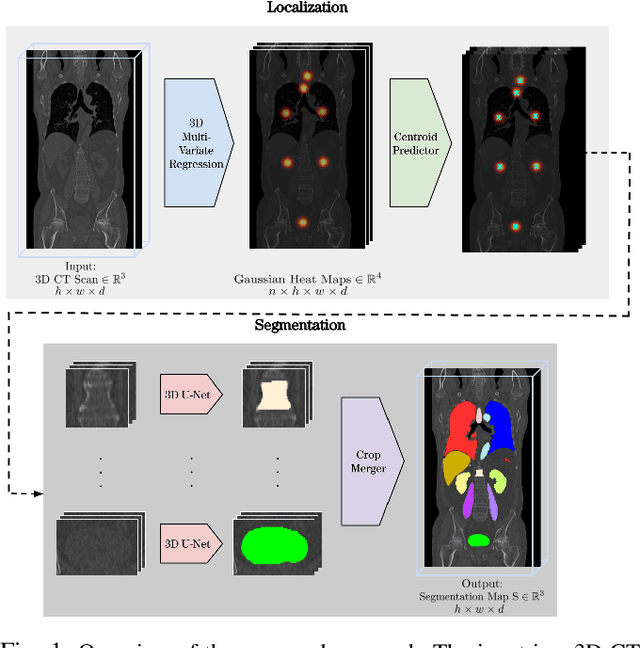
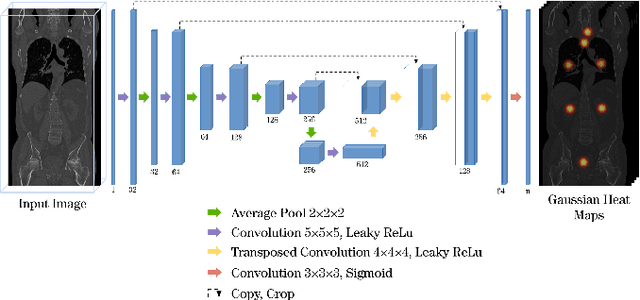
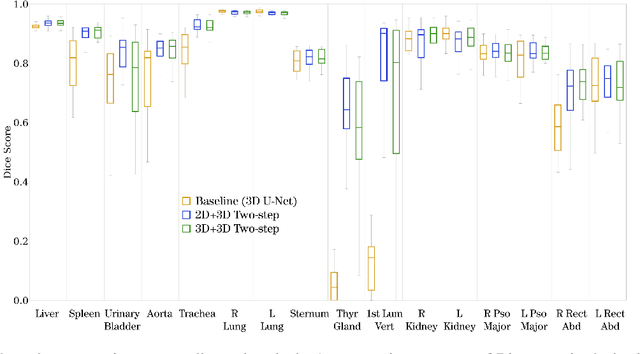
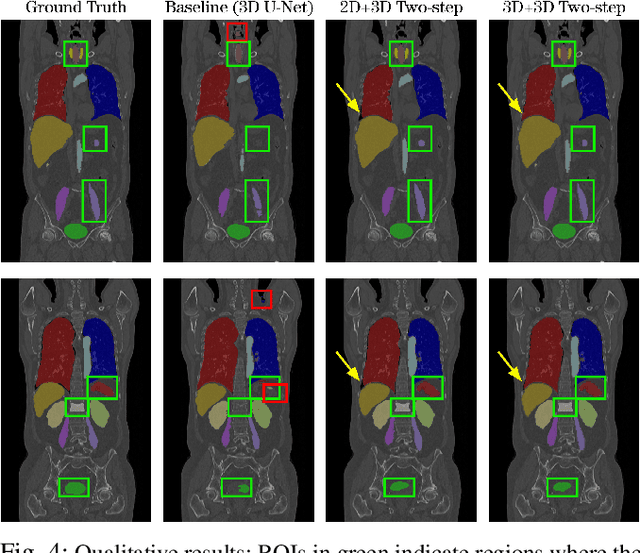
Automatic localization and segmentation of organs-at-risk (OAR) in CT are essential pre-processing steps in medical image analysis tasks, such as radiation therapy planning. For instance, the segmentation of OAR surrounding tumors enables the maximization of radiation to the tumor area without compromising the healthy tissues. However, the current medical workflow requires manual delineation of OAR, which is prone to errors and is annotator-dependent. In this work, we aim to introduce a unified 3D pipeline for OAR localization-segmentation rather than novel localization or segmentation architectures. To the best of our knowledge, our proposed framework fully enables the exploitation of 3D context information inherent in medical imaging. In the first step, a 3D multi-variate regression network predicts organs' centroids and bounding boxes. Secondly, 3D organ-specific segmentation networks are leveraged to generate a multi-organ segmentation map. Our method achieved an overall Dice score of $0.9260\pm 0.18 \%$ on the VISCERAL dataset containing CT scans with varying fields of view and multiple organs.
Evaluating the Robustness of Self-Supervised Learning in Medical Imaging
May 14, 2021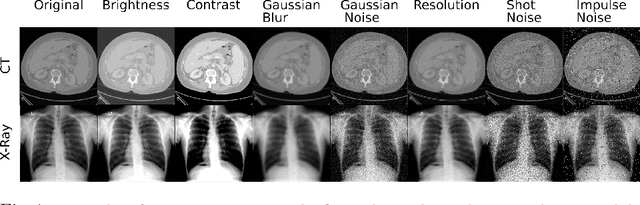

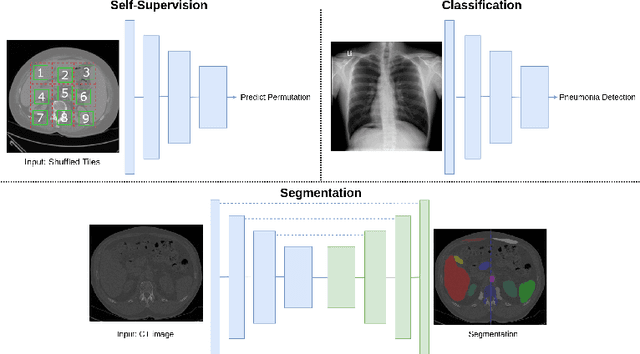
Self-supervision has demonstrated to be an effective learning strategy when training target tasks on small annotated data-sets. While current research focuses on creating novel pretext tasks to learn meaningful and reusable representations for the target task, these efforts obtain marginal performance gains compared to fully-supervised learning. Meanwhile, little attention has been given to study the robustness of networks trained in a self-supervised manner. In this work, we demonstrate that networks trained via self-supervised learning have superior robustness and generalizability compared to fully-supervised learning in the context of medical imaging. Our experiments on pneumonia detection in X-rays and multi-organ segmentation in CT yield consistent results exposing the hidden benefits of self-supervision for learning robust feature representations.