 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUNAvg: Federated Uncertainty Weighted Averaging for Datasets with Diverse Labels
Jul 10, 2024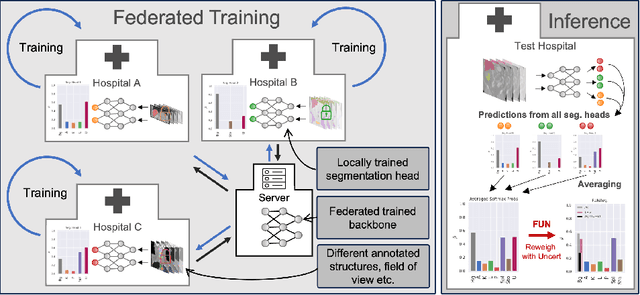

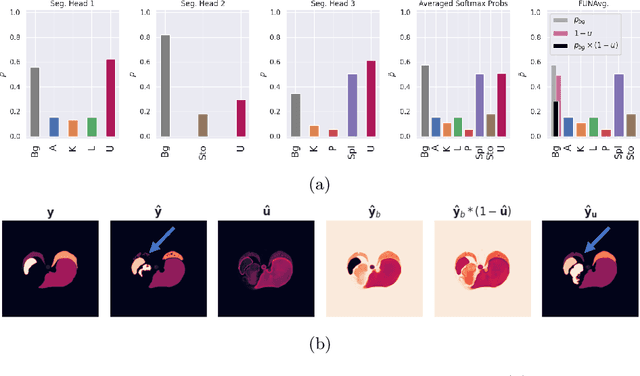

Federated learning is one popular paradigm to train a joint model in a distributed, privacy-preserving environment. But partial annotations pose an obstacle meaning that categories of labels are heterogeneous over clients. We propose to learn a joint backbone in a federated manner, while each site receives its own multi-label segmentation head. By using Bayesian techniques we observe that the different segmentation heads although only trained on the individual client's labels also learn information about the other labels not present at the respective site. This information is encoded in their predictive uncertainty. To obtain a final prediction we leverage this uncertainty and perform a weighted averaging of the ensemble of distributed segmentation heads, which allows us to segment "locally unknown" structures. With our method, which we refer to as FUNAvg, we are even on-par with the models trained and tested on the same dataset on average. The code is publicly available at https://github.com/Cardio-AI/FUNAvg.
Benchmarking the CoW with the TopCoW Challenge: Topology-Aware Anatomical Segmentation of the Circle of Willis for CTA and MRA
Dec 29, 2023



The Circle of Willis (CoW) is an important network of arteries connecting major circulations of the brain. Its vascular architecture is believed to affect the risk, severity, and clinical outcome of serious neuro-vascular diseases. However, characterizing the highly variable CoW anatomy is still a manual and time-consuming expert task. The CoW is usually imaged by two angiographic imaging modalities, magnetic resonance angiography (MRA) and computed tomography angiography (CTA), but there exist limited public datasets with annotations on CoW anatomy, especially for CTA. Therefore we organized the TopCoW Challenge in 2023 with the release of an annotated CoW dataset and invited submissions worldwide for the CoW segmentation task, which attracted over 140 registered participants from four continents. TopCoW dataset was the first public dataset with voxel-level annotations for CoW's 13 vessel components, made possible by virtual-reality (VR) technology. It was also the first dataset with paired MRA and CTA from the same patients. TopCoW challenge aimed to tackle the CoW characterization problem as a multiclass anatomical segmentation task with an emphasis on topological metrics. The top performing teams managed to segment many CoW components to Dice scores around 90%, but with lower scores for communicating arteries and rare variants. There were also topological mistakes for predictions with high Dice scores. Additional topological analysis revealed further areas for improvement in detecting certain CoW components and matching CoW variant's topology accurately. TopCoW represented a first attempt at benchmarking the CoW anatomical segmentation task for MRA and CTA, both morphologically and topologically.
Focused Decoding Enables 3D Anatomical Detection by Transformers
Jul 21, 2022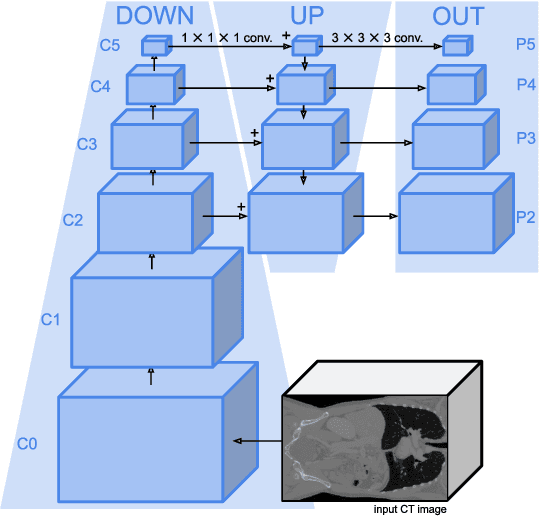
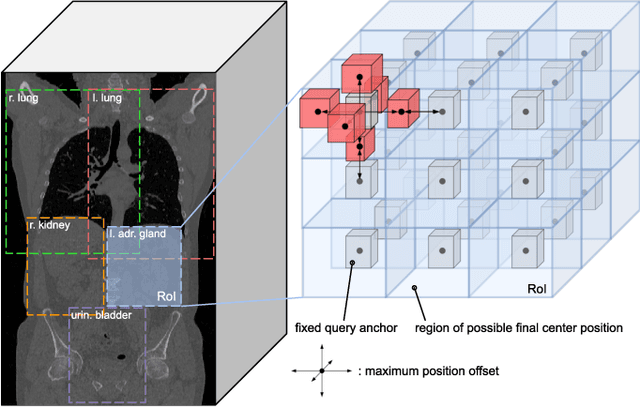
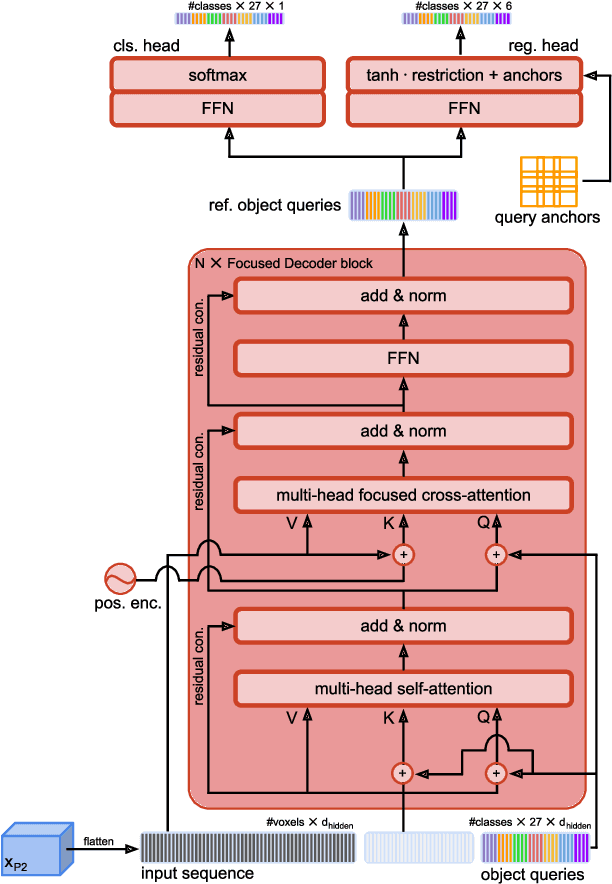
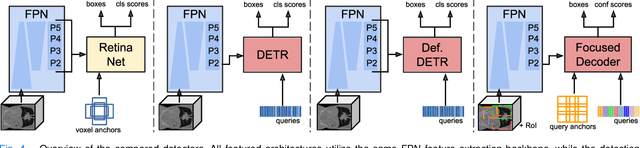
Detection Transformers represent end-to-end object detection approaches based on a Transformer encoder-decoder architecture, exploiting the attention mechanism for global relation modeling. Although Detection Transformers deliver results on par with or even superior to their highly optimized CNN-based counterparts operating on 2D natural images, their success is closely coupled to access to a vast amount of training data. This, however, restricts the feasibility of employing Detection Transformers in the medical domain, as access to annotated data is typically limited. To tackle this issue and facilitate the advent of medical Detection Transformers, we propose a novel Detection Transformer for 3D anatomical structure detection, dubbed Focused Decoder. Focused Decoder leverages information from an anatomical region atlas to simultaneously deploy query anchors and restrict the cross-attention's field of view to regions of interest, which allows for a precise focus on relevant anatomical structures. We evaluate our proposed approach on two publicly available CT datasets and demonstrate that Focused Decoder not only provides strong detection results and thus alleviates the need for a vast amount of annotated data but also exhibits exceptional and highly intuitive explainability of results via attention weights. Code for Focused Decoder is available in our medical Vision Transformer library github.com/bwittmann/transoar.
A unified 3D framework for Organs at Risk Localization and Segmentation for Radiation Therapy Planning
Mar 01, 2022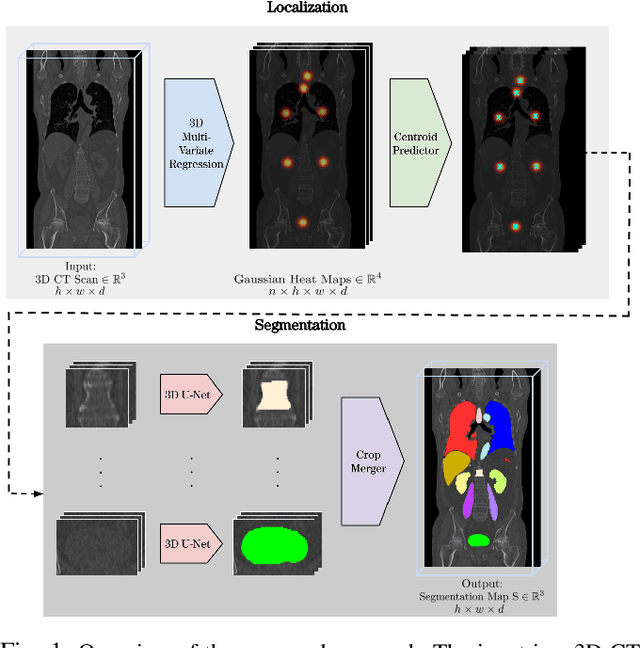
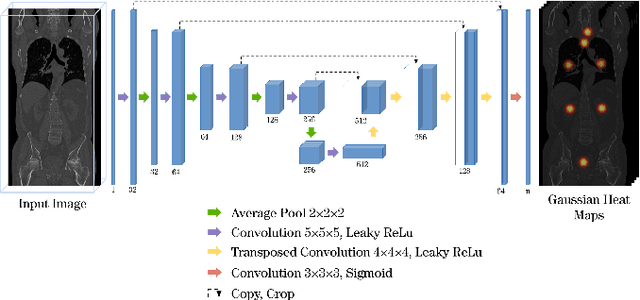
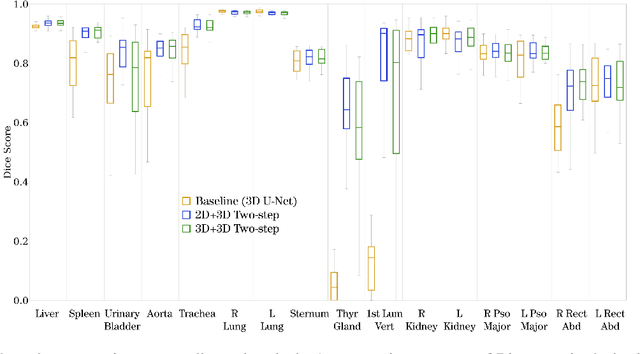
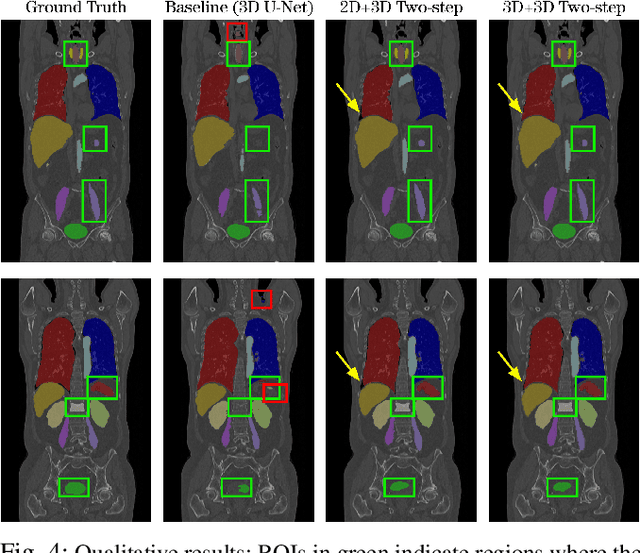
Automatic localization and segmentation of organs-at-risk (OAR) in CT are essential pre-processing steps in medical image analysis tasks, such as radiation therapy planning. For instance, the segmentation of OAR surrounding tumors enables the maximization of radiation to the tumor area without compromising the healthy tissues. However, the current medical workflow requires manual delineation of OAR, which is prone to errors and is annotator-dependent. In this work, we aim to introduce a unified 3D pipeline for OAR localization-segmentation rather than novel localization or segmentation architectures. To the best of our knowledge, our proposed framework fully enables the exploitation of 3D context information inherent in medical imaging. In the first step, a 3D multi-variate regression network predicts organs' centroids and bounding boxes. Secondly, 3D organ-specific segmentation networks are leveraged to generate a multi-organ segmentation map. Our method achieved an overall Dice score of $0.9260\pm 0.18 \%$ on the VISCERAL dataset containing CT scans with varying fields of view and multiple organs.
A Deep Learning Approach to Predicting Collateral Flow in Stroke Patients Using Radiomic Features from Perfusion Images
Oct 24, 2021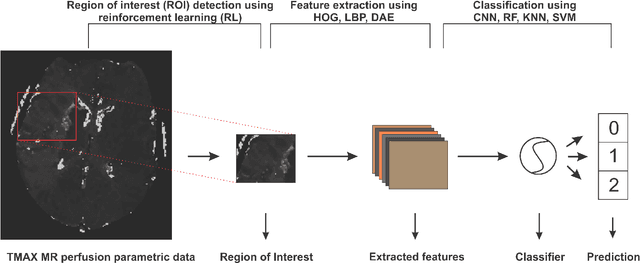
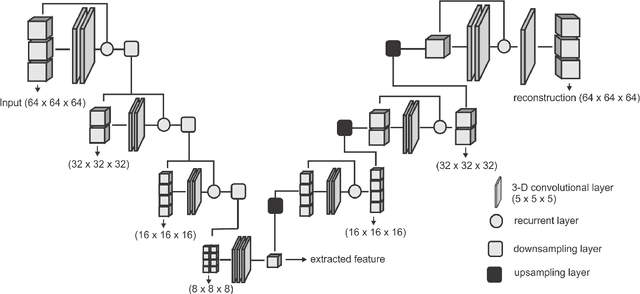
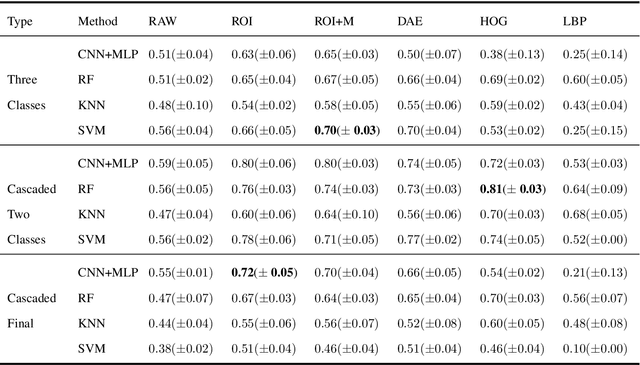
Collateral circulation results from specialized anastomotic channels which are capable of providing oxygenated blood to regions with compromised blood flow caused by ischemic injuries. The quality of collateral circulation has been established as a key factor in determining the likelihood of a favorable clinical outcome and goes a long way to determine the choice of stroke care model - that is the decision to transport or treat eligible patients immediately. Though there exist several imaging methods and grading criteria for quantifying collateral blood flow, the actual grading is mostly done through manual inspection of the acquired images. This approach is associated with a number of challenges. First, it is time-consuming - the clinician needs to scan through several slices of images to ascertain the region of interest before deciding on what severity grade to assign to a patient. Second, there is a high tendency for bias and inconsistency in the final grade assigned to a patient depending on the experience level of the clinician. We present a deep learning approach to predicting collateral flow grading in stroke patients based on radiomic features extracted from MR perfusion data. First, we formulate a region of interest detection task as a reinforcement learning problem and train a deep learning network to automatically detect the occluded region within the 3D MR perfusion volumes. Second, we extract radiomic features from the obtained region of interest through local image descriptors and denoising auto-encoders. Finally, we apply a convolutional neural network and other machine learning classifiers to the extracted radiomic features to automatically predict the collateral flow grading of the given patient volume as one of three severity classes - no flow (0), moderate flow (1), and good flow (2)...
Evaluating the Robustness of Self-Supervised Learning in Medical Imaging
May 14, 2021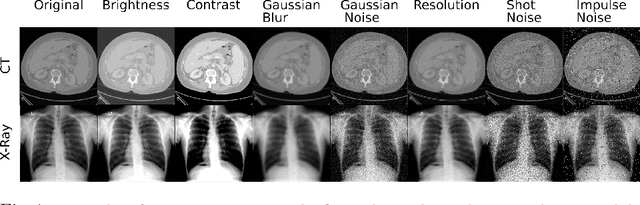

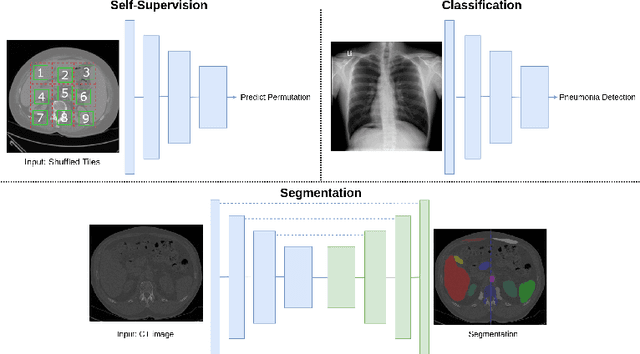
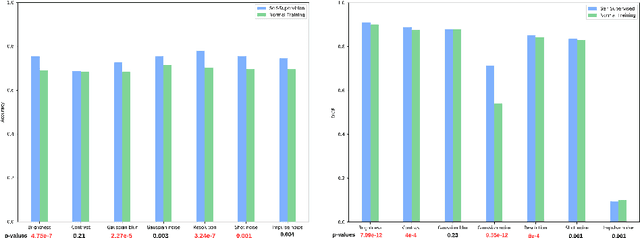
Self-supervision has demonstrated to be an effective learning strategy when training target tasks on small annotated data-sets. While current research focuses on creating novel pretext tasks to learn meaningful and reusable representations for the target task, these efforts obtain marginal performance gains compared to fully-supervised learning. Meanwhile, little attention has been given to study the robustness of networks trained in a self-supervised manner. In this work, we demonstrate that networks trained via self-supervised learning have superior robustness and generalizability compared to fully-supervised learning in the context of medical imaging. Our experiments on pneumonia detection in X-rays and multi-organ segmentation in CT yield consistent results exposing the hidden benefits of self-supervision for learning robust feature representations.
Grading Loss: A Fracture Grade-based Metric Loss for Vertebral Fracture Detection
Aug 18, 2020

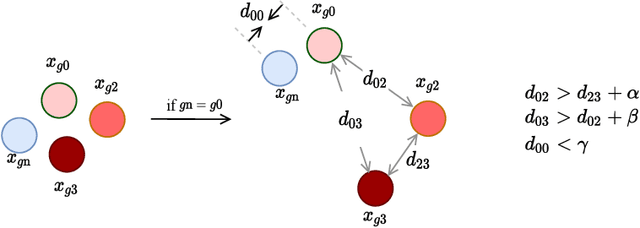
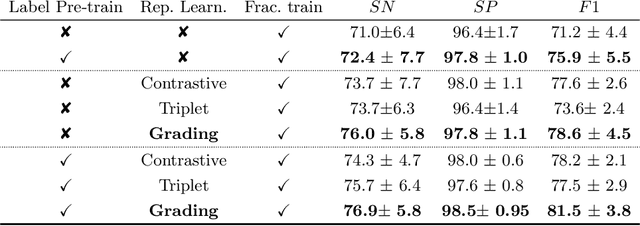
Osteoporotic vertebral fractures have a severe impact on patients' overall well-being but are severely under-diagnosed. These fractures present themselves at various levels of severity measured using the Genant's grading scale. Insufficient annotated datasets, severe data-imbalance, and minor difference in appearances between fractured and healthy vertebrae make naive classification approaches result in poor discriminatory performance. Addressing this, we propose a representation learning-inspired approach for automated vertebral fracture detection, aimed at learning latent representations efficient for fracture detection. Building on state-of-art metric losses, we present a novel Grading Loss for learning representations that respect Genant's fracture grading scheme. On a publicly available spine dataset, the proposed loss function achieves a fracture detection F1 score of 81.5%, a 10% increase over a naive classification baseline.
Deep Reinforcement Learning for Organ Localization in CT
May 11, 2020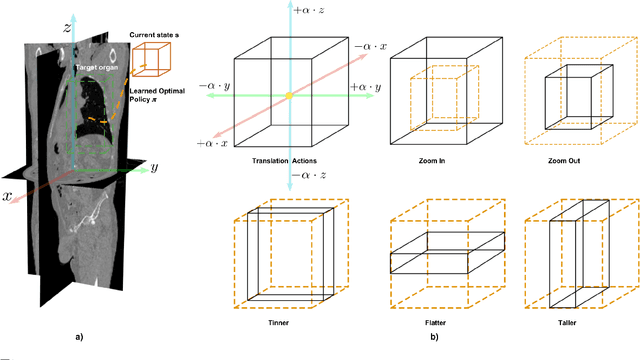
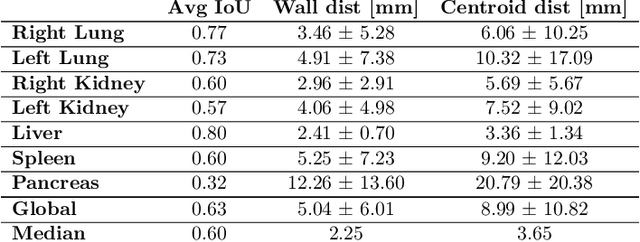
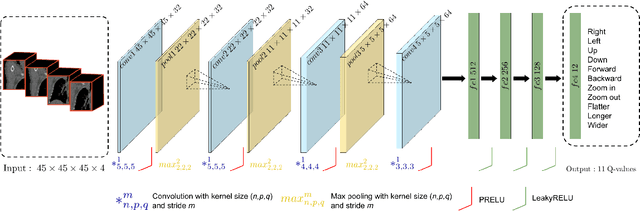
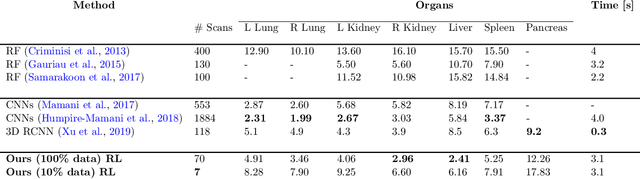
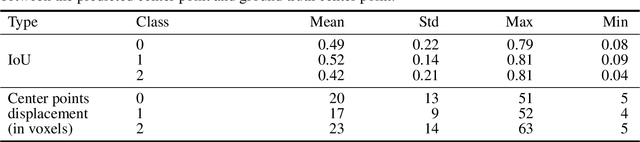
Robust localization of organs in computed tomography scans is a constant pre-processing requirement for organ-specific image retrieval, radiotherapy planning, and interventional image analysis. In contrast to current solutions based on exhaustive search or region proposals, which require large amounts of annotated data, we propose a deep reinforcement learning approach for organ localization in CT. In this work, an artificial agent is actively self-taught to localize organs in CT by learning from its asserts and mistakes. Within the context of reinforcement learning, we propose a novel set of actions tailored for organ localization in CT. Our method can use as a plug-and-play module for localizing any organ of interest. We evaluate the proposed solution on the public VISCERAL dataset containing CT scans with varying fields of view and multiple organs. We achieved an overall intersection over union of 0.63, an absolute median wall distance of 2.25 mm, and a median distance between centroids of 3.65 mm.
* Accepted paper in MIDL 2020
Shape-Aware Complementary-Task Learning for Multi-Organ Segmentation
Aug 14, 2019
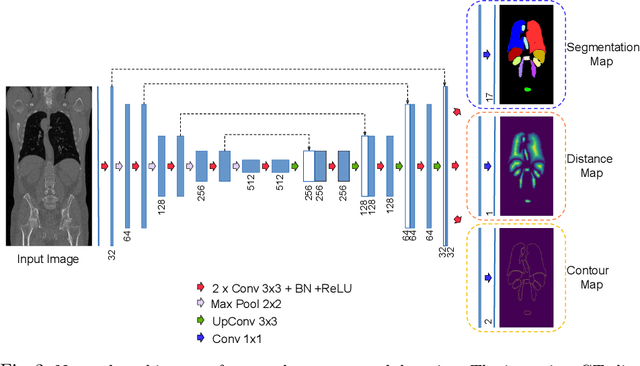

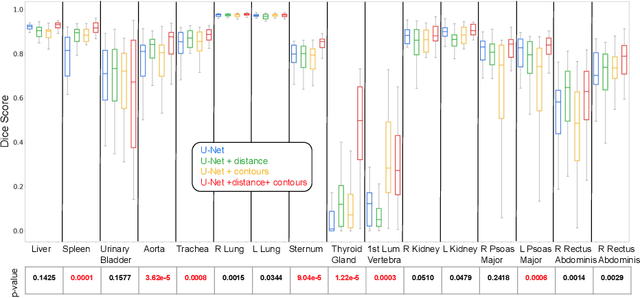
Multi-organ segmentation in whole-body computed tomography (CT) is a constant pre-processing step which finds its application in organ-specific image retrieval, radiotherapy planning, and interventional image analysis. We address this problem from an organ-specific shape-prior learning perspective. We introduce the idea of complementary-task learning to enforce shape-prior leveraging the existing target labels. We propose two complementary-tasks namely i) distance map regression and ii) contour map detection to explicitly encode the geometric properties of each organ. We evaluate the proposed solution on the public VISCERAL dataset containing CT scans of multiple organs. We report a significant improvement of overall dice score from 0.8849 to 0.9018 due to the incorporation of complementary-task learning.
Webly Supervised Learning for Skin Lesion Classification
Mar 31, 2018
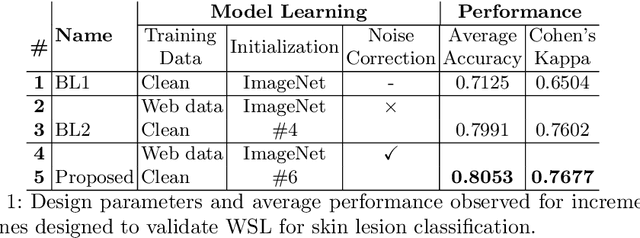

Within medical imaging, manual curation of sufficient well-labeled samples is cost, time and scale-prohibitive. To improve the representativeness of the training dataset, for the first time, we present an approach to utilize large amounts of freely available web data through web-crawling. To handle noise and weak nature of web annotations, we propose a two-step transfer learning based training process with a robust loss function, termed as Webly Supervised Learning (WSL) to train deep models for the task. We also leverage search by image to improve the search specificity of our web-crawling and reduce cross-domain noise. Within WSL, we explicitly model the noise structure between classes and incorporate it to selectively distill knowledge from the web data during model training. To demonstrate improved performance due to WSL, we benchmarked on a publicly available 10-class fine-grained skin lesion classification dataset and report a significant improvement of top-1 classification accuracy from 71.25 % to 80.53 % due to the incorporation of web-supervision.