 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocused Decoding Enables 3D Anatomical Detection by Transformers
Paper and Code
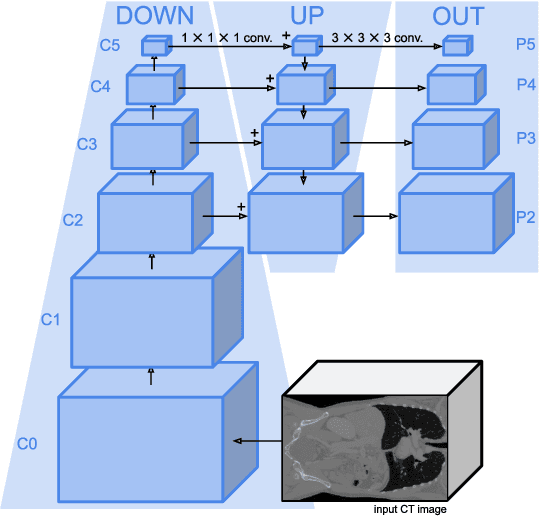
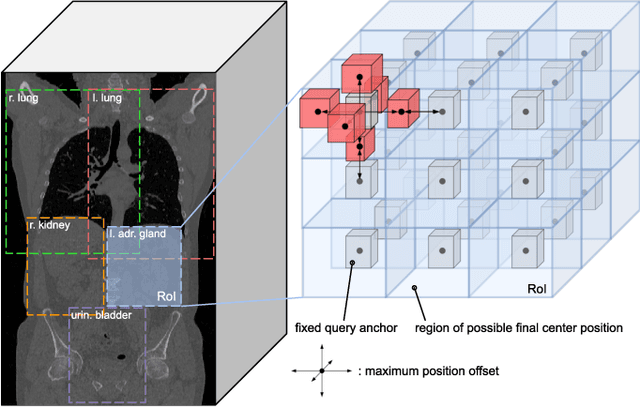
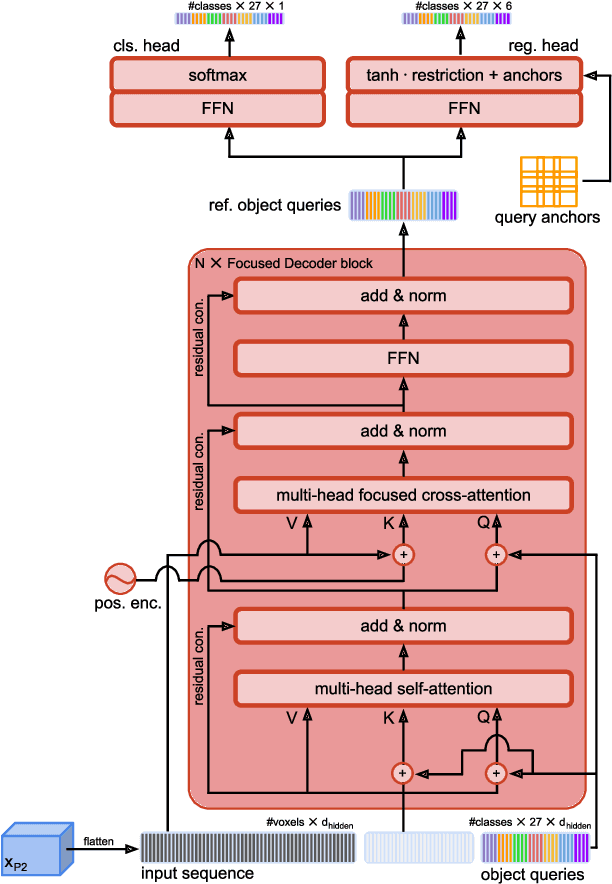
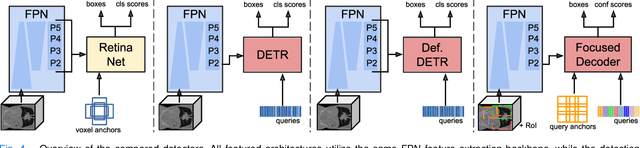
Detection Transformers represent end-to-end object detection approaches based on a Transformer encoder-decoder architecture, exploiting the attention mechanism for global relation modeling. Although Detection Transformers deliver results on par with or even superior to their highly optimized CNN-based counterparts operating on 2D natural images, their success is closely coupled to access to a vast amount of training data. This, however, restricts the feasibility of employing Detection Transformers in the medical domain, as access to annotated data is typically limited. To tackle this issue and facilitate the advent of medical Detection Transformers, we propose a novel Detection Transformer for 3D anatomical structure detection, dubbed Focused Decoder. Focused Decoder leverages information from an anatomical region atlas to simultaneously deploy query anchors and restrict the cross-attention's field of view to regions of interest, which allows for a precise focus on relevant anatomical structures. We evaluate our proposed approach on two publicly available CT datasets and demonstrate that Focused Decoder not only provides strong detection results and thus alleviates the need for a vast amount of annotated data but also exhibits exceptional and highly intuitive explainability of results via attention weights. Code for Focused Decoder is available in our medical Vision Transformer library github.com/bwittmann/transoar.