 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebly Supervised Learning for Skin Lesion Classification
Paper and Code
Mar 31, 2018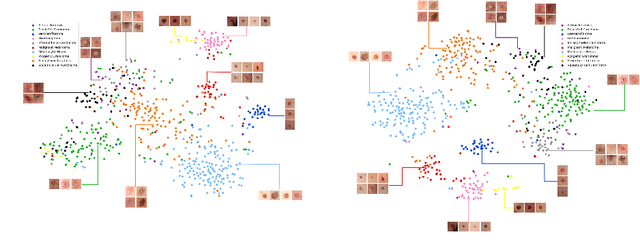
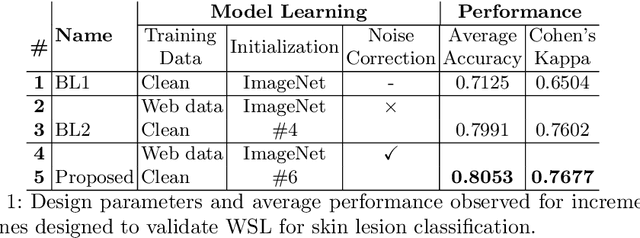

Within medical imaging, manual curation of sufficient well-labeled samples is cost, time and scale-prohibitive. To improve the representativeness of the training dataset, for the first time, we present an approach to utilize large amounts of freely available web data through web-crawling. To handle noise and weak nature of web annotations, we propose a two-step transfer learning based training process with a robust loss function, termed as Webly Supervised Learning (WSL) to train deep models for the task. We also leverage search by image to improve the search specificity of our web-crawling and reduce cross-domain noise. Within WSL, we explicitly model the noise structure between classes and incorporate it to selectively distill knowledge from the web data during model training. To demonstrate improved performance due to WSL, we benchmarked on a publicly available 10-class fine-grained skin lesion classification dataset and report a significant improvement of top-1 classification accuracy from 71.25 % to 80.53 % due to the incorporation of web-supervision.