 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MAMA-MIA Challenge: Advancing Generalizability and Fairness in Breast MRI Tumor Segmentation and Treatment Response Prediction
Mar 01, 2026Breast cancer is the most frequently diagnosed malignancy among women worldwide and a leading cause of cancer-related mortality. Dynamic contrast-enhanced magnetic resonance imaging plays a central role in tumor characterization and treatment monitoring, particularly in patients receiving neoadjuvant chemotherapy. However, existing artificial intelligence models for breast magnetic resonance imaging are often developed using single-center data and evaluated using aggregate performance metrics, limiting their generalizability and obscuring potential performance disparities across demographic subgroups. The MAMA-MIA Challenge was designed to address these limitations by introducing a large-scale benchmark that jointly evaluates primary tumor segmentation and prediction of pathologic complete response using pre-treatment magnetic resonance imaging only. The training cohort comprised 1,506 patients from multiple institutions in the United States, while evaluation was conducted on an external test set of 574 patients from three independent European centers to assess cross-continental and cross-institutional generalization. A unified scoring framework combined predictive performance with subgroup consistency across age, menopausal status, and breast density. Twenty-six international teams participated in the final evaluation phase. Results demonstrate substantial performance variability under external testing and reveal trade-offs between overall accuracy and subgroup fairness. The challenge provides standardized datasets, evaluation protocols, and public resources to promote the development of robust and equitable artificial intelligence systems for breast cancer imaging.
Segmentation variability and radiomics stability for predicting Triple-Negative Breast Cancer subtype using Magnetic Resonance Imaging
Apr 02, 2025
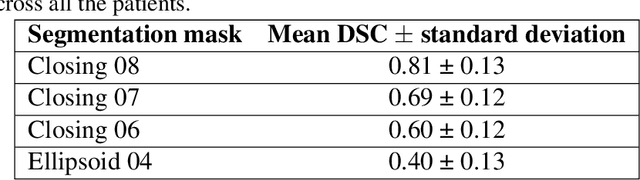


Most papers caution against using predictive models for disease stratification based on unselected radiomic features, as these features are affected by contouring variability. Instead, they advocate for the use of the Intraclass Correlation Coefficient (ICC) as a measure of stability for feature selection. However, the direct effect of segmentation variability on the predictive models is rarely studied. This study investigates the impact of segmentation variability on feature stability and predictive performance in radiomics-based prediction of Triple-Negative Breast Cancer (TNBC) subtype using Magnetic Resonance Imaging. A total of 244 images from the Duke dataset were used, with segmentation variability introduced through modifications of manual segmentations. For each mask, explainable radiomic features were selected using the Shapley Additive exPlanations method and used to train logistic regression models. Feature stability across segmentations was assessed via ICC, Pearson's correlation, and reliability scores quantifying the relationship between feature stability and segmentation variability. Results indicate that segmentation accuracy does not significantly impact predictive performance. While incorporating peritumoral information may reduce feature reproducibility, it does not diminish feature predictive capability. Moreover, feature selection in predictive models is not inherently tied to feature stability with respect to segmentation, suggesting that an overreliance on ICC or reliability scores for feature selection might exclude valuable predictive features.
Federated nnU-Net for Privacy-Preserving Medical Image Segmentation
Mar 04, 2025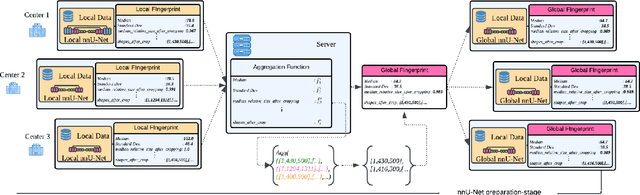
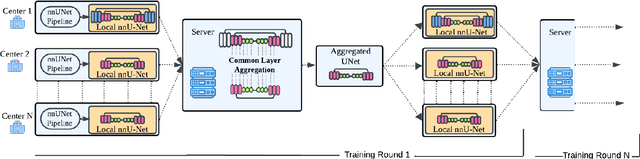
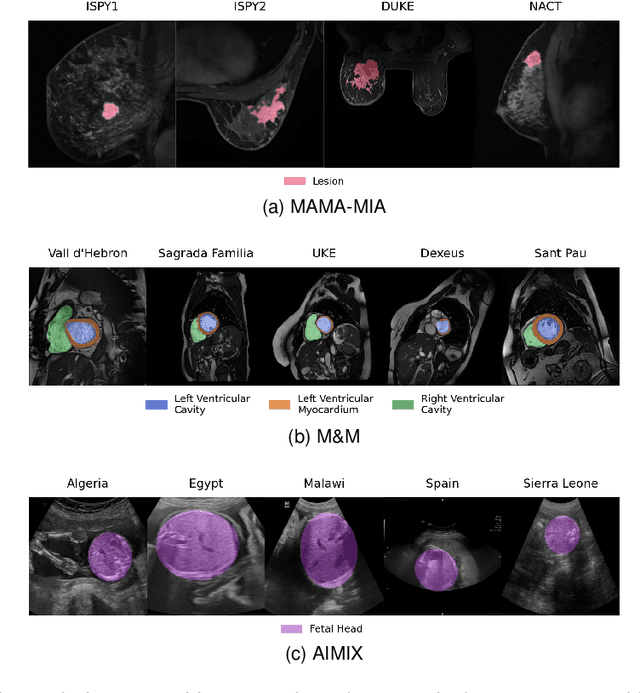
The nnU-Net framework has played a crucial role in medical image segmentation and has become the gold standard in multitudes of applications targeting different diseases, organs, and modalities. However, so far it has been used primarily in a centralized approach where the data collected from hospitals are stored in one center and used to train the nnU-Net. This centralized approach has various limitations, such as leakage of sensitive patient information and violation of patient privacy. Federated learning is one of the approaches to train a segmentation model in a decentralized manner that helps preserve patient privacy. In this paper, we propose FednnU-Net, a federated learning extension of nnU-Net. We introduce two novel federated learning methods to the nnU-Net framework - Federated Fingerprint Extraction (FFE) and Asymmetric Federated Averaging (AsymFedAvg) - and experimentally show their consistent performance for breast, cardiac and fetal segmentation using 6 datasets representing samples from 18 institutions. Additionally, to further promote research and deployment of decentralized training in privacy constrained institutions, we make our plug-n-play framework public. The source-code is available at https://github.com/faildeny/FednnUNet .
MAMA-MIA: A Large-Scale Multi-Center Breast Cancer DCE-MRI Benchmark Dataset with Expert Segmentations
Jun 19, 2024Current research in breast cancer Magnetic Resonance Imaging (MRI), especially with Artificial Intelligence (AI), faces challenges due to the lack of expert segmentations. To address this, we introduce the MAMA-MIA dataset, comprising 1506 multi-center dynamic contrast-enhanced MRI cases with expert segmentations of primary tumors and non-mass enhancement areas. These cases were sourced from four publicly available collections in The Cancer Imaging Archive (TCIA). Initially, we trained a deep learning model to automatically segment the cases, generating preliminary segmentations that significantly reduced expert segmentation time. Sixteen experts, averaging 9 years of experience in breast cancer, then corrected these segmentations, resulting in the final expert segmentations. Additionally, two radiologists conducted a visual inspection of the automatic segmentations to support future quality control studies. Alongside the expert segmentations, we provide 49 harmonized demographic and clinical variables and the pretrained weights of the well-known nnUNet architecture trained using the DCE-MRI full-images and expert segmentations. This dataset aims to accelerate the development and benchmarking of deep learning models and foster innovation in breast cancer diagnostics and treatment planning.
Mitigating annotation shift in cancer classification using single image generative models
May 30, 2024Artificial Intelligence (AI) has emerged as a valuable tool for assisting radiologists in breast cancer detection and diagnosis. However, the success of AI applications in this domain is restricted by the quantity and quality of available data, posing challenges due to limited and costly data annotation procedures that often lead to annotation shifts. This study simulates, analyses and mitigates annotation shifts in cancer classification in the breast mammography domain. First, a high-accuracy cancer risk prediction model is developed, which effectively distinguishes benign from malignant lesions. Next, model performance is used to quantify the impact of annotation shift. We uncover a substantial impact of annotation shift on multiclass classification performance particularly for malignant lesions. We thus propose a training data augmentation approach based on single-image generative models for the affected class, requiring as few as four in-domain annotations to considerably mitigate annotation shift, while also addressing dataset imbalance. Lastly, we further increase performance by proposing and validating an ensemble architecture based on multiple models trained under different data augmentation regimes. Our study offers key insights into annotation shift in deep learning breast cancer classification and explores the potential of single-image generative models to overcome domain shift challenges.